by Scott Muniz | Jun 25, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Introduction
Customers who have read our previous blogs frequently raise an important question: How should we configure ProxySQL in a highly available setup to get maximum performance and scale from our Azure Database for MySQL service. In this post, I hope to provide detail that will help to address the question.
Important: This post is a part of a multi-post blog series related to configuring ProxySQL with Azure Database for MySQL. We highly recommend that you read the previous posts in this series (shown below) to have more context about use cases for ProxySQL with Azure Database for MySQL servers.
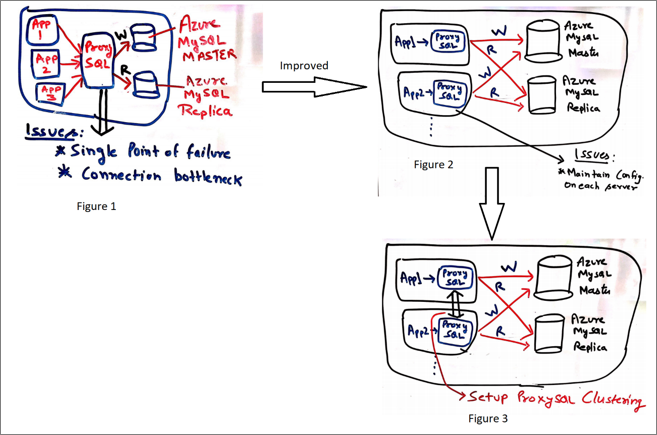
Most of the time, you configure ProxySQL on a separate server, and all the connections are routed from the application to the ProxySQL server. ProxySQL in turn directs all the connections to database server depending on the query rules configured (illustrated in figure 1). There are some concerns with using this approach, as:
- ProxySQL becomes a single point of failure for the application, potentially impacting the application’s availability.
- The ProxySQL server can become a resource bottleneck, limiting performance and scale.
One way to address these concerns is to configure ProxySQL on the application side (illustrated in figure 2). By collocating ProxySQL with the application VMs, you also reduce cost. One of the downsides of this solution is the need to manually synchronize the ProxySQL configuration across application VMs or pods. While this works for many customers, if ProxySQL configuration changes are less frequent (as is the case in most scenarios), it can become a challenge in a complex setup. You can mitigate this problem and also build a highly available and scalable architecture with ProxySQL by using ProxySQL native clustering (as illustrated in figure 3).

This blog post shows how to configure native ProxySQL clustering as shown in Figure 3.
Note:
ProxySQL is an open source community tool. It is supported by Microsoft on a best effort basis. In order to get production support with authoritative guidance, you can evaluate and reach out to ProxySQL Product support.
Prerequisites
For the example in this post, we’ll be setting up a cluster with three nodes and configuring the ProxySQL server to split the read and write workloads to designated Azure Database for MySQL servers. Prerequisites for this effort are outlined in the post Load balance read replicas using ProxySQL in Azure Database for MySQL, the difference being that we’ll use three Linux VMs running Ubuntu as three nodes for ProxySQL cluster.
Configuring ProxySQL native clustering
Perform below steps on all three Linux VMs.
To install ProxySQL, in the post Load balance read replicas using ProxySQL in Azure Database for MySQL, refer to the detail in the section “Installing ProxySQL on Ubuntu VM”.
- After installing ProxySQL, update the proxysql config file located at /etc/proxysql.cnf with the cluster details, and add the information about the servers hosting ProxySQL:
admin_variables=
{
admin_credentials=”admin:admin;cluster1:secret1pass”
# mysql_ifaces=”127.0.0.1:6032;/tmp/proxysql_admin.sock”
mysql_ifaces=”0.0.0.0:6032″
# refresh_interval=2000
# debug=true
cluster_username=”cluster1″
cluster_password=”secret1pass”
cluster_check_interval_ms=200
cluster_check_status_frequency=100
cluster_mysql_query_rules_save_to_disk=true
cluster_mysql_servers_save_to_disk=true
cluster_mysql_users_save_to_disk=true
cluster_proxysql_servers_save_to_disk=true
cluster_mysql_query_rules_diffs_before_sync=3
cluster_mysql_servers_diffs_before_sync=3
cluster_mysql_users_diffs_before_sync=3
cluster_proxysql_servers_diffs_before_sync=3
}
proxysql_servers =
(
{
hostname=”VM_1_Public_IP”
port=6032
comment=”proxysql100″
},
{
hostname=” VM_2_Public_IP”
port=6032
comment=”proxysql200″
},
{
hostname=” VM_3_Public_IP”
port=6032
comment=”proxysql300″
}
)
Important:
- In the proxysql.cnf file, only add the bolded configuration information above. Also, ensure that the VMs can communicate with each other using inbound and outbound rules.
- Make sure that Azure VM are part of availability set to protect from datacenter level failure and update.
2. Execute the below step to re-initialize ProxySQL from the config file (after first startup the DB file is used instead of the proxysql.cnf config file)
Service proxysql initial
Note:
In the previous section, we configured ProxySQL native clustering. This ensures that changes to one ProxySQL node will be propagated to all nodes in the cluster. From now onwards, please perform the ProxySQL specific changes to only one of the nodes in the ProxySQL cluster.
Setting up the ProxySQL
- Connect to the ProxySQL administration interface with the default password ‘admin’.
mysql –u admin –p admin -h127.0.0.1 -P6032
- Add the reader and writer nodes ProxySQL server pool.
insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(1,'mydemomasterserver.mysql.database.azure.com',3306,1,'Write Group');
insert into mysql_servers(hostgroup_id,hostname,port,weight,comment) values(2,'mydemoreplicaserver.mysql.database.azure.com',3306,1,'Read Group');
- Enable SSL support in ProxySQL server pool
UPDATE mysql_servers SET use_ssl=1 WHERE hostgroup_id=1;
UPDATE mysql_servers SET use_ssl=1 WHERE hostgroup_id=2;
Creating the MySQL users
In ProxySQL, the user connects to ProxySQL and in turn ProxySQL passes the connection to the MySQL node. To allow ProxySQL to access to the MySQL database, we need to create a user on MySQL database with the same credentials as on the ProxySQL server.
- Create a new user ‘mydemouser’ with the password ‘secretpassword’
CREATE USER 'mydemouser'@'%' IDENTIFIED BY ' secretpassword';
- Grant ‘mydemouser’ privileges to fully access the MySQL server
GRANT ALL PRIVILEGES ON *.* TO ' mydemouser'@'%' WITH GRANT OPTION;
- Apply the changes to the permissions
FLUSH PRIVILEGES;
Creating the ProxySQL user
Note: Perform the action below on only one of the nodes in the ProxySQL cluster.
Allow the ‘mydemouser’ user to connect to ProxySQL server.
insert into mysql_users(username,password,default_hostgroup,transaction_persistent)values('mydemouser',' secretpassword',1,1);
Configure Monitoring on ProxySQL
Configure ProxySQL to monitor the nodes, and then create the monitoring user on the Master server.
- Create a new user ‘monitoruser’ with the password ‘secretpassword’
CREATE USER ' monitoruser'@'%' IDENTIFIED BY 'secretpassword';
- Grant ‘monitoruser’ privileges to fully access the MySQL server
GRANT SELECT ON *.* TO ' monitoruser'@'%' WITH GRANT OPTION;
- Apply the changes to the permissions
FLUSH PRIVILEGES;
On the server running ProxySQL, configure mysql-monitor to the username of the new account.
set mysql-monitor_username='monitoruser';
set mysql-monitor_password=' secretpassword';
Configure the routing rules for read and write split
- On the ProxySQL Server, configure the write traffic to route to the master server
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(1,1,'^SELECT.*FOR UPDATE$',1,1);
- On the ProxySQL Server, configure the read traffic to route to the read replica server
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(2,1,'^SELECT',2,1);
Save the changes made to the ProxySQL configuration to persists across restarts
In ProxySQL configuration system, the changes we made are in memory and to make them persist across the restarts, you must copy settings to runtime and save them to disk.
- On the server running ProxySQL, execute the below commands to save the settings to runtime:
load mysql users to runtime;
load mysql servers to runtime;
load mysql query rules to runtime;
load mysql variables to runtime;
load admin variables to runtime;
- On the server running ProxySQL, execute the following commands to save the settings to disk:
save mysql users to disk;
save mysql servers to disk;
save mysql query rules to disk;
save mysql variables to disk;
save admin variables to disk;
After successfully completing the above steps, ProxySQL is configured with native clustering and is ready to split the read and write workload. Use the following steps to test if the read and write splits are being forwarded properly:
- Log in to one of the servers running ProxySQL with the ProxySQL user you created
mysql –u mydemouser –p secretpassword -h127.0.0.1 -P6033
- Run the read and write queries
SELECT *
FROM mydemotable;
UPDATE mydemotable
SET mydemocolumn=value
WHERE condition;
To verify that ProxySQL has routed the above read and write correctly:
3. Connect to the ProxySQL administration interface on one of the VM with the default password ‘admin’.
mysql –u admin –p admin -h127.0.0.1 -P6032
4. Execute the following query:
SELECT * FROM stats_mysql_query_digest;
If you have trouble setting up ProxySQL on Azure Database for MySQL, please contact the Azure Database for MySQL team at AskAzureDBforMySQL@service.microsoft.com
Thank you!
Amol Bhatnagar
Program Manager – Microsoft
by Scott Muniz | Jun 25, 2020 | Uncategorized
This article is contributed. See the original author and article here.
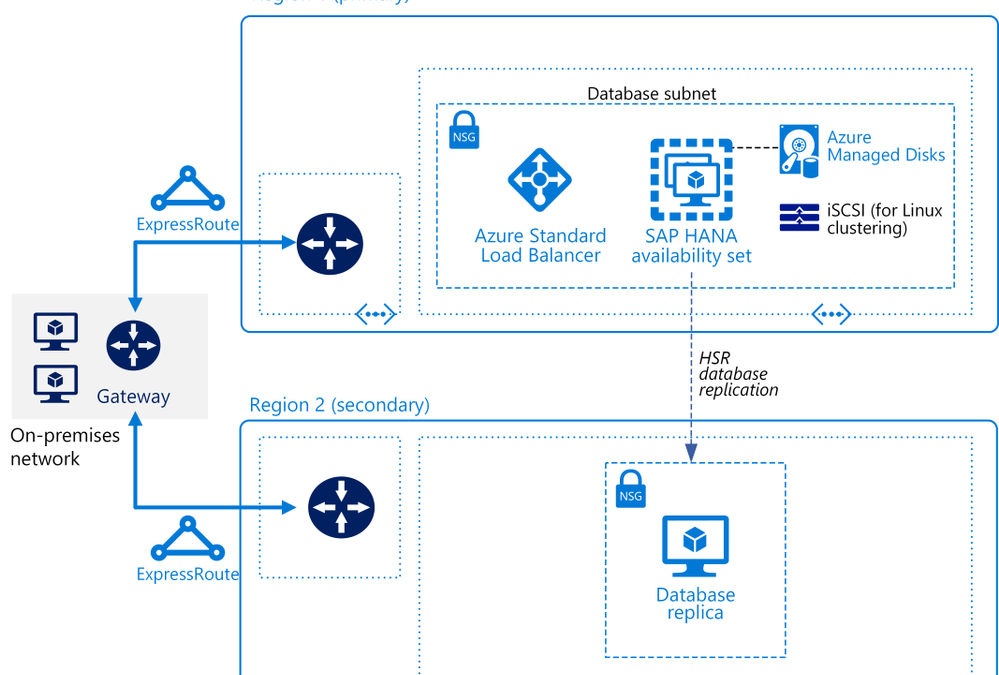
The Azure solution architects who specialize in all things SAP have been hard at work. We’re happy to announce a new SAP on Azure Architecture Guide plus a new SAP reference architecture for running SAP HANA on Linux virtual machines in a scale-up architecture. This implementation focuses on the database layer and is designed to support various SAP applications, such as S/4HANA and SAP BW/4HANA.
Like all our SAP reference architectures, this one was written by a team of cloud solution architects who work closely with customers on their SAP deployments. These experts share their insider understanding in the best practices featured across all our SAP on Azure articles.
The SAP HANA scale-up deployment is designed for high availability in a production environment. Azure offers single-node scale up to 11.5 terabytes (TB) on virtual machines and single-node scale up to 24 TB on Azure Large Instances.

And there’s more: great resources in the Azure Architecture Center
We recently published the SAP on Azure Architecture Guide, a high-level look at migration considerations, such as cost, security, and infrastructure.
In addition, we updated the reference architectures for SAP NetWeaver, SAP S/4HANA, and SAP HANA on Azure (Large Instances). For example, you’ll find info about minimizing latency with proximity placement groups and increasing availability with Azure Availability Zones.
We also made our reference architectures easier to find from the left menu of the Azure Architecture Center. If you like to see content that way, do this:
- Go to the Azure Architecture Center.
- In the left navigation menu, expand the Azure categories item.
- Scroll down (items are in alphabetical order) and click SAP.
The reference architectures and SAP articles in the Azure Architecture Center are designed to complement the how-to documentation about implementing SAP on Azure, starting with Use Azure to host and run SAP workload scenarios.
by Scott Muniz | Jun 25, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Hello everyone, here is part 4 of a series focusing on Application Deployment in Configuration Manager. This series is recorded by @Steve Rachui, a Microsoft principal premier field engineer. These tutorials are from our library and uses Configuration Manager 2012 in the demos, however the concepts are still relevant for Configuration Manager current branch.
This session focuses on the client and works through several demonstrations of deploying applications configured to demonstrate simple deployment, dependencies, supercedence, user affinity and requirements, and the client cache function.
Next in the series Steve continues to focus on the client and works through examples of using maintenance windows, applications configured for distribute on demand and roaming scenarios.
Posts in the series
- Introduction
- Packages
- Applications
- Client Experience Part 1
- Client Experience Part 2
- Packages Behind the Scenes
- Applications Behind the Scenes
- Distribution Points Behind the Scenes
- Clients and Packages Behind the Scenes
- Clients and Applications Behind the Scenes
- Task Sequences
- App-V overview
- App-V 5.0 Sequencer
- App-V 5.0 Client
Go straight to the playlist
by Scott Muniz | Jun 25, 2020 | Uncategorized
This article is contributed. See the original author and article here.
The Azure Sphere OS quality update 20.06 is now available in the Retail feed. This release includes an OS update with the following enhancements:
- Fixed a problem that caused a segmentation fault in the wpa_supplicant.
- Fixed a problem that caused device recovery to fail on a device if the run-time clock (RTC) was disabled.
- Reduced resets triggered by RTC time-outs during OS installation.
Latest SDKs
- The latest Azure Sphere SDK for Linux is version 20.04 Update 1, which supports the Ubuntu 20.04 LTS release.
- The latest Azure Sphere SDK for Windows is version 20.04 Update 2, which supports the “device code” login flow that can help resolve login problems with personal Microsoft accounts.
For more information
For more information on Azure Sphere OS feeds and setting up an evaluation device group, see Azure Sphere OS feeds.
If you encounter problems, please notify us immediately through your Microsoft technical account manager (TAM) or by contacting Azure Support so that we can address any issues. Microsoft engineers and Azure Sphere community experts will also respond to product-related questions on our MSDN forum and development questions on Stack Overflow.


Recent Comments