Migrate HDInsight 3.6 Hive(2.1.0) to HDInsight 4.0 Hive(3.1.0)
This article is contributed. See the original author and article here.
HDInsight 4.0 brings upgraded versions for all Apache components , but for this lab we specifically focus on the Hive versions.
| Component | HDInsight 4.0 | HDInsight 3.6 |
|---|---|---|
| Hive | 3.1.0 | 2.1.0 ; 1.2.1 |
Some key areas that Hive 3.x differs from earlier versions are.
Client
- Hive CLI support is deprecated in Hive 3.x and only the thin client Beeline is supported
Transaction Processing
- ACID tables are the default table type in Hive 3.x with performance as good as non Acid
- Automatic query cache
Catalogs
- Spark and Hive use independent catalogues for Spark SQL or Hive tables in same or independent clusters
- The Hive Warehouse connector is used to integrate between Spark and Hive workloads.
For an exhaustive overview of advancements in Hive 3.0 , listen to this presentation.
Lab
This lab is a simulation of a real migration and will consist of the following steps in sequence.
- Create an HDInsight Hadoop 3.6 cluster.
- Create test data in the HDInsight 3.6 cluster. We use TPCDS data here.
- Run TPCDS tests to simulate Hive workloads.
- Copy the Hive 2.1 Metastore and upgrade the Metastore copy to 3.1.
- Delete the older HDInsight Hadoop 3.6 cluster.
- Create a new HDInsight 4.0 cluster with the older storage account and new upgraded 3.1 Hive Metastore.
Run the same TPCDS tests to ensure everything is working as intended.
Create a Storage account
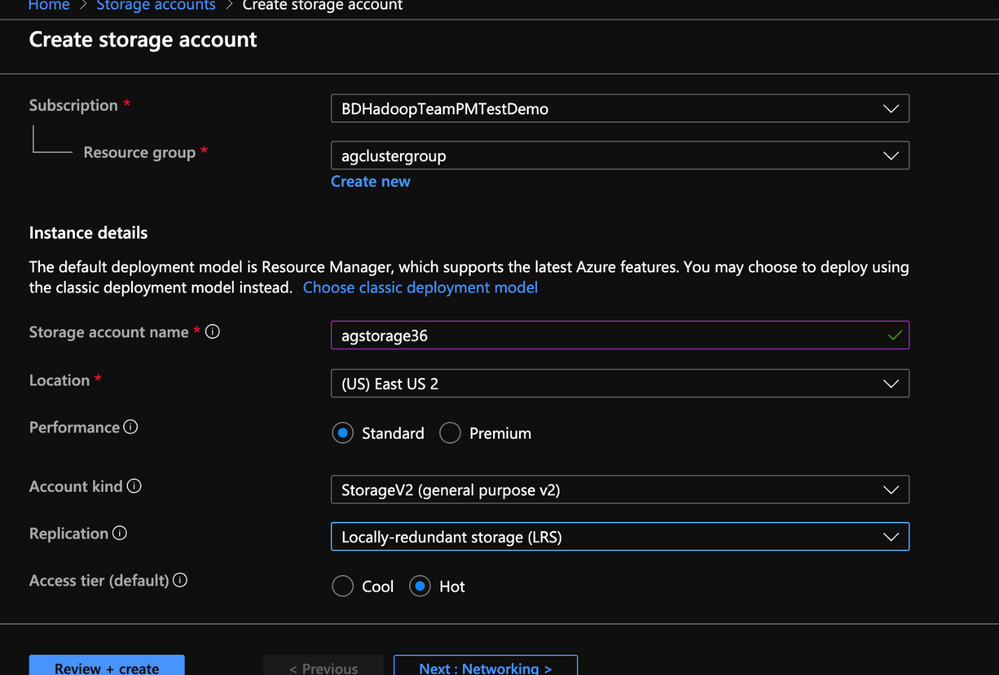
1. Create storage account and click create
2. Populate the Basics tab of Storage account with the below information.
- Resource group: Create or use an existing resource group
- Storage account name: Enter a unique name for your storage account( I used agstorage36 to represent an older cluster )
- Location: Enter an Azure region( HDInsight cluster needs to be created in same the Azure region)
- Performance: Standard
- Account Kind: StorageV2(general purpose v2)
- Replication: Locally-redundant storage(LRS)
- Access Tier: Hot

3. Populate the Advanced tab of Storage account with the below information.
- Security(Secure transfer required): Enabled
- Virtual Network(Allow access from): All networks
- Data Protection(Blob soft delete:( Disabled
- Data Lake Storage Gen2(Hierarchical Namespace): Disabled
< Insert Image >
4. Make no changes to the Tags Tab and post validation click Create on the Review + Create tab to create an Azure Blob storage account.

5. In the next section we would create the external metastore for the HDInsight Hadoop 3.6 cluster.
Create an External Metastore for the HDInsight Hadoop 3.6 cluster
1. On the Azure Portal Navigate to the SQL Database blade and click create

2. Populate the Basics tab of SQL Server with the below information.
-
Resource group: Use the same resource group used for storage
-
Database Details :
-
Database name: Choose any allowed name for the metastore ( I used aghive36db to represent a Hive 2.1 metastore on an HDInsight 3.6 cluster type
-
Server :- Click Create new
- Server admin login: Create a username
- Password/Confirm Password : Enter Metastore server password – Location : Choose same location as Storage Account
-
Want to use SQL Elastic Pool : N
-



3. Compute+Storage : Click on the Configure Database link to Navigate to the database configuration page

4. In the Database Configuration page select the Standard Tier with the below settings and click Apply
- DTU: 200
- Data Max Size : A few GBs

5. In the Networking tab ensure the following settings are met
- Connectivity Method : Public endpoint
- Firewall Rules:
- Allow Azure Services and Resources to Access this Server : Yes
- Add current IP address: Yes

6.Leave the Additional settings and Tags to their default state
7. In the Review+Create tab click Create

8. In this section we created an External Hive Metastore(aghive36db) which we will use subsequently in an HDInsight 3.6 cluster.

Provision HDInsight Hadoop 3.6(Hive 2.1.0) cluster from Azure Management Portal
To provision HDInsight LLAP with Azure Management Portal, perform the below steps.
-
Go to the Azure Portal portal.azure.com. Login using your azure account credentials.
-
Select Create a resource -> Azure HDInsight -> Create
-
Click the Custom(size ,settings, apps) slider

2. In the Basics tab populate the following values.
- Resource Group:Put the cluster in the same resource group as the Storage account and Metastore
- Cluster Name: Enter the cluster name. A green tick will appear if the cluster name is available.
- Region: Choose the same region as the storage account
- Cluster Type : Cluster Type – Hadoop
- Version: Hadoop 2.7.3 (HDI 3.6)

- Cluster login username:Enter username for cluster administrator(default:admin)
- Cluster login password:Enter password for cluster login(admin)
- Confirm Cluster login password:Repeat the same password as used earlier
- Secure Shell(SSH) username:_Enter the SSH username for the cluster(default:sshuser)
- Use cluster login for SSH: Check this box(this makes your SSH password same as the cluster admin password)

5. In the Storage tab populate the following values.
- Primary Storage Type: Azure Storage
- Selection method: Select from list
- Primary Storage account: Select the Azure storage blob account created earlier.
- Container: Enter a name for the storage container
6. Metastore Settings: Enter the name for the SQL Database/SQL Server combination that was created in the last step



7. Click Authenticate to enter the username and password for the Metastore. Enter the username and password that was set for the SQL Server in the last exercise.

8. In the Configuration+Pricing tab select the node sizes for the cluster. There are no hard and fast rules and the recommendation is to select larger nodes for faster data processing. Note that choosing nodes that are too small may result in failures.

9. In the Review+Create tab , review the cluster specifics and click Create.

10. In this step we created an HDInsight 3.6 Hadoop cluster with preconfigured external metastore and storage account.

11. In the next step we will create some test data in the cluster to represent a production workload.
Create TPCDS test data on the HDInsight 3.6 Hadoop cluster with Beeline CLI
Goal of this step is to help generate TPCDS data with hive as a close representation of production data.
- Clone this repo
git clone https://github.com/hdinsight/tpcds-hdinsight && cd tpcds-hdinsight
- Upload the resources to DFS
hdfs dfs -copyFromLocal resources /tmp
- Run TPCDSDataGen.hql with settings.hql file and set the required config variables.( 1 GB of data)
beeline -u "jdbc:hive2://`hostname -f`:10001/;transportMode=http" -n "" -p "" -i settings.hql -f TPCDSDataGen.hql -hiveconf SCALE=1 -hiveconf PARTS=1 -hiveconf LOCATION=/HiveTPCDS/ -hiveconf TPCHBIN=`grep -A 1 "fs.defaultFS" /etc/hadoop/conf/core-site.xml | grep -o "wasb[^<]*"`/tmp/resources
SCALE is a scale factor for TPCDS. Scale factor 10 roughly generates 10 GB data, Scale factor 1000 generates 1 TB of data and so on.
PARTS is a number of task to use for datagen (parrellelization). This should be set to the same value as SCALE.
LOCATION is the directory where the data will be stored on HDFS.
TPCHBIN is where the resources are found. You can specify specific settings in settings.hql file.
- Create tables on the generated data.
beeline -u "jdbc:hive2://`hostname -f`:10001/;transportMode=http" -n "" -p "" -i settings.hql -f ddl/createAllExternalTables.hql -hiveconf LOCATION=/HiveTPCDS/ -hiveconf DBNAME=tpcds
- Generate ORC tables and analyze
beeline -u "jdbc:hive2://`hostname -f`:10001/;transportMode=http" -n "" -p "" -i settings.hql -f ddl/createAllORCTables.hql -hiveconf ORCDBNAME=tpcds_orc -hiveconf SOURCE=tpcds
beeline -u "jdbc:hive2://`hostname -f`:10001/;transportMode=http" -n "" -p "" -i settings.hql -f ddl/analyze.hql -hiveconf ORCDBNAME=tpcds_orc
- Run a few queries to represent a production workload. Change the query number in the end to test various queries.
beeline -u "jdbc:hive2://`hostname -f`:10001/tpcds_orc;transportMode=http" -n "" -p "" -i settings.hql -f queries/query12.sql
-
In this section we have created test data on the cluster and then tested a few queries representative of production datasets.
-
In the next section we would upgrade the Hive Metastore from 2.1.1. to 3.1.
Upgrade the Hive Metastore from Hive 2.1.1 to Hive 3.1
Create a copy of the Hive Metastore in HDInsight 3.6
- From the HDInsight 3.6 cluster click on the External Metastores.

2. Click on the Metastore to open the SQL DB portal.

3. On the SQL DB portal click on Restore.

- In the restore blade choose the below values to get the most recent copy of the Hive Metastore
- Select Source : Point-in-time
- Database name: Assign a new db name*( I chose the name aghive40db)
- Restore Point:
- Date: Current date
- Time: Current time
- Target Server: Choose SQL server create earlier
- Elastic Pool: None
- Pricing Tier: Same tier as older metastore db
Click OK to continue with creation of a copy

5. After creation, the new SQL db(aghive40db) appears as an additional database in the same SQL Server.



Upgrade the Hive 2.1.1 Metastore
- On the HDInsight cluster click on Script Actions.

2. On the Script action page populated the parameters as described below and click Create
- Script Type: Custom
- Name: Enter a new for the script
- Bash Script URI:
https://hdiconfigactions.blob.core.windows.net/hivemetastoreschemaupgrade/launch-schema-upgrade.sh - Node type(s): Head
- Parameters:
SQLservername NEWSQLdbname SQLServerusername SQLServerpasswordNote : Use single space with no commas or semicolons Example:agclusterdbserver aghive40db username password

3. The script action starts on the cluster

4. The script comes back with a green check mark which indicates successful completion.

Validate the Hive Metastore version
After the script finishes , we would need to validate if the Hive Metastore is indeed upgraded
- Launch the new SQL db portal(aghive40db) and click on Query Editor.You could alternatively use SSMS or Azure Data Studio.

-
Enter the below query in the query editor and click Run.
Select * from [dbo].version -
Validate to see the if the schema version was upgraded to 3.1.0 . This would indicate that the Hive metastore was succesfully upgraded.

4. Post up-gradation , delete the older HDInsight 3.6 cluster.



-
In this section we upgraded the new Hive Metastore aghive40db from version 2.1.2 to 3.1.0 post which we deleted the older HDInsight cluster.
-
In the next section , we would create a new HDInsight 4.0( Hive 3.1) cluster with the new Hive Metastore and the older storage account.
Provision HDInsight Hadoop 4.0(Hive 3.1.0) cluster from Azure Management Portal
To provision HDInsight LLAP with Azure Management Portal, perform the below steps.
-
Go to the Azure Portal portal.azure.com. Login using your azure account credentials.
-
Select Create a resource -> Azure HDInsight -> Create
-
Click the Custom(size ,settings, apps) slider
-
In the Basics tab populate the following values.
- Resource Group:Put the cluster in the same resource group as the Storage account and Metastore
- Cluster Name: Enter the cluster name. A green tick will appear if the cluster name is available.
- Region: Choose the same region as the storage account
- Cluster Type : Cluster Type – Hadoop
- Version: Hadoop 3.1.0(HDI 4.0)

- Cluster login username:Enter username for cluster administrator(default:admin)
- Cluster login password:Enter password for cluster login(admin)
- Confirm Cluster login password:Repeat the same password as used earlier
- Secure Shell(SSH) username:_Enter the SSH username for the cluster(default:sshuser)
- Use cluster login for SSH: Check this box(this makes your SSH password same as the cluster admin password)

- In the Storage tab populate the following values.
- Primary Storage Type: Azure Storage
- Selection method: Select from list
- Primary Storage account: Select the Azure storage blob account created earlier.
- Container: Enter the same storage container that was used for the previous HDInsight 3.6 cluster

- Metastore Settings: Enter the name for the new SQL Database/SQL Server(agclusterdbserver/aghive40db) combination that was upgraded in the last step

6. Click Authenticate to enter the username and password for the Metastore. Enter the username and password that was set for the SQL Server.

7. In the Configuration+Pricing tab select the node sizes for the cluster. There are no hard and fast rules and the recommendation is to select larger nodes for faster data processing. Note that choosing nodes that are too small may result in failures.

8. In the Review+Create tab , review the cluster specifics and click Create.

-
In this step we created an HDInsight 4.0 Hadoop cluster with preconfigured upgraded external metastore and mapped its storage to a preexisting storage container.
-
In the next step we will create some test data in the cluster to represent a production workload.
Run TPCDS test data on the HDInsight 4.0 Hadoop cluster with Beeline CLI
Goal of this step is to run TPCDS tests with an upgraded Hive Metastore to represent regression tests of Hive workloads.
-
The TPCDS repo should already be cloned and TPCDS data should already exist from what we created earlier.
-
SSH into the cluster using the ssh credentials provided durinng cluster creation.
-
Run a few TPCDS queries to represent a production regression test . Change the query number in the end to test various queries.
beeline -u "jdbc:hive2://`hostname -f`:10001/tpcds_orc;transportMode=http" -n "" -p "" -i settings.hql -f queries/query12.sql
- In this lab we migrated multiple HDInsight 3.6 Hive workloads to HDInsight 4.0.
Further reference:



























Recent Comments