by Contributed | Oct 29, 2020 | Technology
This article is contributed. See the original author and article here.
In response to the unique and evolving requirements of the United States government and regulated industries we’ve built Office 365 Government offerings for customers handling controlled unclassified information (CUI) on behalf of the US Government. Office 365 Government (GCC and GCC High) are designed to support US government entities and those working with the US government to meet specific compliance and cybersecurity requirements. We’re excited to announce that our Office 365 Government GCC environment now has a FedRamp High SAR (security assessment report). More on the history of the Office 365 Government cloud offerings can be found here.
Government regulations are not static. As the world of data security and compliance evolves, so too does our need to support governments and regulated industries with solutions to protect and manage their data. As part of our journey to support US government and regulated industries we will continue to evolve our Office 365 Government cloud offerings with new compliance value to help customers achieve their compliance commitments. All regulated businesses have varying needs when it comes to storing, processing, and transmitting CUI. As part of our commitment to data security and compliance, we will continue to bring innovative products such as Teams, Office Apps, Security, and Compliance to our government clouds with the strict controls required to ensure all products meet FedRAMP High control requirements. We will continue to bring more compliance value to GCC including DFARs support and CMMC accreditation in the near future. Government contractors and all regulated businesses that require US government compliance for CUI, will continue to have access to comprehensive, secure, and compliant SaaS offerings, giving them a holistic tool set to create a compliant environment.
We’re excited for the evolution of the GCC environment and we see this offering being an integral part of a defense contractors journey to meet their CMMC obligations while still being able to address government and internal guidance commitments to CUI. This ongoing journey is going to help government customers and their industry partners choose and select the right environment for them based on their CUI and compliance needs.
by Contributed | Oct 29, 2020 | Technology
This article is contributed. See the original author and article here.
One of the unique things about Postgres is that it is highly programmable via PL/pgSQL and extensions. Postgres is so programmable that I often think of Postgres as a computing platform rather than just a database (or a distributed computing platform—with Citus). As a computing platform, I always felt that Postgres should be able to take actions in an automated way. That is why I created the open source pg_cron extension back in 2016 to run periodic jobs in Postgres—and why I continue to maintain pg_cron now that I work on the Postgres team at Microsoft.
Using pg_cron, you can schedule Postgres queries to run periodically, according to the familiar cron syntax. Some typical examples:
-- vacuum my table every night at 3am (GMT)
SELECT cron.schedule('0 3 * * *', 'VACUUM my_table');
-- call a procedure every minute
SELECT cron.schedule('process-new-events', '* * * * *', 'CALL process_new_events()');
-- upgrade an extension when PostgreSQL restarts
SELECT cron.schedule('upgrade-pgcron', '@reboot', 'ALTER EXTENSION pg_cron UPDATE');
-- Delete old data on Saturday at 1:30am (GMT)
SELECT cron.schedule('delete-old-events','30 1 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Since its initial release, pg_cron has become a standard tool in the arsenal for many of you who use PostgreSQL. You can find the pg_cron extension on GitHub—it’s open source, and it’s easy to install and set up. And pg_cron is also included in managed Postgres database services such as the Hyperscale (Citus) and Flexible Server options in Azure Database for PostgreSQL.
The popularity of pg_cron has also created demand for more advanced features, such as an audit log, the ability to update cron job schedules, and for other ways to run pg_cron in cloud database services.
Recently, the RDS team at Amazon reached out to us to see if would accept contributions to pg_cron to enable pg_cron in RDS. And our answer was: Of course! Hence the is the result of a collaboration between Microsoft (job names, reviews, bug fixes) and Amazon (audit log, background workers), with a little help from Zalando (PostgreSQL 13 support).
Audit log lets you see your running cron jobs, as well as past job runs
Pg_cron logs the outcome of jobs in the PostgreSQL log, but the log is not always easy to access for database users. Thanks to an awesome contribution by Bertrand Drouvot and Nathan Bossart from the Amazon RDS team, you can now also see a log of your pg_cron jobs in the database in a table called cron.job_run_details.
The cron.job_run_details table shows:
- when a command started and finished,
- whether the pg_cron command succeeded, and
- the number of rows returned—or the error message to quickly detect when something went wrong
-- update my rollup tables every minute
SELECT cron.schedule('update rollups', '* * * * *', 'SELECT update_rollup_tables()');
-- after a while
SELECT * FROM cron.job_run_details;
┌───────┬───────┬─────────┬──────────┬──────────┬───────────────────────────────┬───────────┬────────────────────────────────────────────┬───────────────────────────────┬───────────────────────────────┐
│ jobid │ runid │ job_pid │ database │ username │ command │ status │ return_message │ start_time │ end_time │
├───────┼───────┼─────────┼──────────┼──────────┼───────────────────────────────┼───────────┼────────────────────────────────────────────┼───────────────────────────────┼───────────────────────────────┤
│ 2 │ 13 │ 1022 │ postgres │ marco │ SELECT update_rollup_tables() │ succeeded │ 1 row │ 2020-10-28 12:18:00.059566+02 │ 2020-10-09 12:18:01.734262+02 |
│ 2 │ 1 │ 986 │ postgres │ marco │ SELECT update_rollup_tables() │ succeeded │ 1 row │ 2020-10-28 12:19:00.029769+02 │ 2020-10-09 12:09:01.345637+02 |
│ 1 │ 14 │ 1023 │ postgres │ marco │ VACUUM my_table │ failed │ ERROR: relation "my_table" does not exist │ 2020-10-28 12:19:00.079291+02 │ 2020-10-28 12:19:00.080133+02 |
└───────┴───────┴─────────┴──────────┴──────────┴───────────────────────────────┴───────────┴────────────────────────────────────────────┴───────────────────────────────┴───────────────────────────────┘
(3 rows)
The audit log is not automatically cleaned up, but … we have pg_cron! That means you can easily decide on your own retention policy and use pg_cron to schedule a job that cleans up the audit log:
-- at midnight, delete all audit log entries older than 14 days
SELECT cron.schedule('clean audit log', '0 0 * * *', $$DELETE FROM cron.job_run_details WHERE end_time < now() – interval ’14 days’$$);
In implementing the audit log in pg_cron, we used the row-level security feature in Postgres to make sure that database users can only see and delete their own audit log entries.
Using background workers avoids connection configuration
Pg_cron normally executes commands by either connecting to localhost or the unix domain socket (configurable using the `cron.host` setting). Both connection options are secure but do require some changes to pg_hba.conf to enable, and which change you need to make depends on which Linux distribution you are using.
Thanks to another contribution by Bertrand and Nathan, you can choose to use dynamic background workers instead of connections by setting cron.use_background_workers = on in postgresql.conf. That way, you do not need any pg_hba.conf changes.
A slight downside of background workers is that the number of concurrent jobs is limited to max_worker_processes (8 by default). The standard way of connecting to localhost is only limited to max_connections (which is 100 by default, usually higher). We recommend increasing max_worker_processes when using background workers.
Job names simplify pg_cron job management
If you are already familiar with pg_cron, you may have noticed that the examples above now includes a job name as the first argument to the cron.schedule(..) function. The ability to give your pg_cron jobs a name is also a new feature in pg_cron 1.3, by yours truly.
When you use a job name, cron.schedule does an upsert rather than an insert, which means you idempotently set your schedule and your command.
For instance, if I name my pg_cron job nightly vacuum then I can easily change the schedule:
-- set up a nightly vacuum at 1am with a job name
select cron.schedule('nightly vacuum', '0 1 * * *', 'vacuum my_table');
┌──────────┐
│ schedule │
├──────────┤
│ 4 │
└──────────┘
(1 row)
-- I can now see the nightly vacuum job in the cron.job.table
table cron.job;
┌───────┬───────────┬─────────────────┬───────────┬──────────┬──────────┬──────────┬────────┬────────────────┐
│ jobid │ schedule │ command │ nodename │ nodeport │ database │ username │ active │ jobname │
├───────┼───────────┼─────────────────┼───────────┼──────────┼──────────┼──────────┼────────┼────────────────┤
│ 4 │ 0 1 * * * │ vacuum my_table │ localhost │ 5432 │ postgres │ marco │ t │ nightly vacuum │
└───────┴───────────┴─────────────────┴───────────┴──────────┴──────────┴──────────┴────────┴────────────────┘
(1 row)
-- change the schedule to 3am by using the same job name
select cron.schedule('nightly vacuum', '0 3 * * *', 'vacuum my_table');
┌──────────┐
│ schedule │
├──────────┤
│ 4 │
└──────────┘
(1 row)
-- I can see the new schedule in the cron.job table
table cron.job;
┌───────┬───────────┬─────────────────┬───────────┬──────────┬──────────┬──────────┬────────┬────────────────┐
│ jobid │ schedule │ command │ nodename │ nodeport │ database │ username │ active │ jobname │
├───────┼───────────┼─────────────────┼───────────┼──────────┼──────────┼──────────┼────────┼────────────────┤
│ 4 │ 0 3 * * * │ vacuum my_table │ localhost │ 5432 │ postgres │ marco │ t │ nightly vacuum │
└───────┴───────────┴─────────────────┴───────────┴──────────┴──────────┴──────────┴────────┴────────────────┘
(1 row)
Using a job name also makes it easy to ensure a specific set of jobs is running, without having to check whether the job already exists.
PostgreSQL 13 support is available for pg_cron
Finally, PostgreSQL 13 is out! Of course, the new pg_cron 1.3 release supports (and all PostgreSQL versions since 9.5). Big thanks to Alexander Kukushkin from Zalando for updating pg_cron to support Postgres 13.
Packages for pg_cron 1.3 are available via PGDG for Red Hat/CentOS and Debian/Ubuntu.
Better together: Improving PostgreSQL across competitive boundaries
One of the exciting parts of being on the Postgres team at Microsoft is that Microsoft has embraced open source. What that means in practice is that we are making significant contributions to PostgreSQL via our team of PostgreSQL committers and contributors (including engineers Andres Freund, David Rowley, Dimitri Fontaine, Jeff Davis, and Thomas Munro). In addition, we have created and maintain some pretty useful open source extensions to Postgres such as Citus, pg_auto_failover, and of course pg_cron. When we open source our software, competitors might benefit from our work, but the more important point is all PostgreSQL users (including our customers) benefit!
I find pg_cron to be super useful. And some have gone so far to say that it’s “really cool” to have the scheduler within the database, and tied to the data itself. We’re happy to see that pg_cron has gotten significant contributions from Amazon and look forward to seeing one great PostgreSQL job scheduler across Azure Database for PostgreSQL, RDS, and other Postgres cloud database services.
by Contributed | Oct 29, 2020 | Technology
This article is contributed. See the original author and article here.
Here is your next installment in the troubleshooting hybrid migrations blog series! See:
There are 2 main flavors of “completed with warnings” scenarios when onboarding mailboxes from Exchange on-premises to Exchange Online. While these warnings can happen in offboarding scenarios, that is rarer than seeing them during onboarding. We gathered some examples for onboarding migrations and will discuss these here.
The migration batch / move requests will typically have a status of “CompletedWithWarning” and you might see a warning similar to the following in the Exchange Admin Center Migration pane:
Warning: Unable to update Active Directory information for the source mailbox at the end of the move. Error details: An error occurred while updating a user object after the move operation.
As mentioned several times by now in this blog series, to dig deeper into the details of the move, you would get move request statistics for the affected user with IncludeMoveReport switch, from Exchange Online PowerShell and then import it and store it in a variable:
Get-MoveRequestStatistics <user> -IncludeMoveReport | export-clixml C:tempEXO_MoveReqStats.xml
Issues you’d see on-premises
If we fail to convert the source mailbox into a remote mailbox (fail to cleanup things on source after mailbox has been moved to the cloud), as result of this failure we may end up with 2 mailboxes for the same user (one on-premises and a migrated one in the cloud.)
Example from $stats.Report.Entries:
Failed to convert the source mailbox ‘contoso.onmicrosoft.com4019d389-dcc6-4a77-a19c-e49408e7a160 (Primary)’ to mail-enabled user after the move. Attempt 17/480. Error: CommunicationErrorTransientException.
31.08.2020 11:47:42 [AM5PR0102MB2770] Post-move cleanup failed. The operation will try again in 30 seconds (18/480)
If the source AD user is not correctly updated into a remote mailbox during an onboarding move to Office 365, you would need to follow this KB article to manually disable the mailbox on-premises and convert it into a remote mailbox.
Depending on the time period the two mailboxes coexisted (which results in content being different in these two since migration completed) you would eventually need to restore the content of the disconnected mailbox on-premises to the migrated cloud mailbox (for restore cmdlet see Step 1.7 from this article). Another option is to export it to PST before disabling it and importing the PST into the target mailbox using the Outlook client or using the Office 365 PST Import Service.
Issues you’d see in Exchange Online
It can happen that a database failover occurs in the completion phase of the migration while unlocking the target mailbox in Office 365 (this is a rare case and we have an automatic task that ensures the mailbox is unlocked and would allow us to access the target mailbox.) If this happens, we expect the source mailbox to be converted successfully into a remote mailbox.
A more common scenario in Office 365 would be when there were transient failures with a specific Domain Controller (DC) in Exchange Online but where another DC took over the migration job and the move request was completed successfully.
For this scenario, in the move report entries $stats.report.Entries | % {[string] $_} in PowerShell, or in the Migration User Status Report in Exchange Admin Center, you should check if:
- Target mailbox is updated successfully on a different DC than the DC mentioned in the failure.(AM4PR02A008DC01 unavailable vs AM4PR02A008DC05 which took over, in example below)
- Source mailbox was converted into a mail user with success using on-premises DC; see the line that says “The mailbox was converted into a mail user using domain controller ‘DC6.contoso.com’” in the example
- The move request is complete (“Request is complete”).
All these conclude a successful completion of the move request, even if we had a temporary DC failure during the move.
The ‘good’ example (things worked out well):
10.03.2020 14:24:19 [DB7PR02MB4379] The following failure occurred after the Active Directory modification completed: The domain controller ‘AM4PR02A008DC01.EURPR02A008.PROD.OUTLOOK.COM’ is not available for use at the moment. Please try again..
10.03.2020 14:24:19 [DB7PR02MB4379] An error caused a change in the current set of domain controllers.
10.03.2020 14:24:20 [DB7PR02MB4379] Target mailbox ‘John Smith/ Contoso Org’ was updated on domain controller ‘AM4PR02A008DC05.EURPR02A008.PROD.OUTLOOK.COM’.
10.03.2020 14:24:20 [MAILSRV-EX15] The mailbox was converted into a mail user using domain controller ‘DC6.contoso.com’.19.09.2018 14:24:20 [DB7PR02MB4379] Source mail user ‘John Smith/ Contoso Org’ was updated on domain controller ‘DC6.contoso.com’.
10.03.2020 14:24:21 [DB7PR02MB4379] Target mailbox ‘contoso.onmicrosoft.com39026949-29d0-4f9b-a84d-3c52c8b28b39 (Primary)’ was successfully reset after the move.
10.03.2020 14:25:18 [DB7PR02MB4379] Request is complete.
Other than situations mentioned above, you should check the following things when you have an onboarding move request completed with warnings:
- The mailbox can be accessed least from OWA client for the onboarded user (https://outlook.office365.com/owa) and the migrated content is there.
- Test-MapiConnectivity in Exchange Online PowerShell against that mailbox is OK.
- The user is a Remote Mailbox in on-premises: Get-RemoteMailbox <user>
This concludes the entire blog post series. Hoping that you’ve found this useful. I am here to answer your further questions!
I would like to thank Angus Leeming, William Rall, Brad Hughes, Chris Boonham, Ben Winzenz, Cristian Dimofte, Nicu Simion, Nino Bilic and Timothy Heeney for their precious help on this blog and for dealing with me in my daily support life.
Mirela Buruiana
by Contributed | Oct 29, 2020 | Technology
This article is contributed. See the original author and article here.
Now in preview, the Auditing of Microsoft support operations is a free capability that enable you to audit Microsoft support operations when they need to access to your Azure SQL Databases during a support request to your audit logs destination.
The use of this capability, along with your auditing, enables more transparency into your workforce and allows for anomaly detection, trend visualization, and data loss prevention. We currently support Log Analytics and Event Hub and are working to support storage accounts soon.
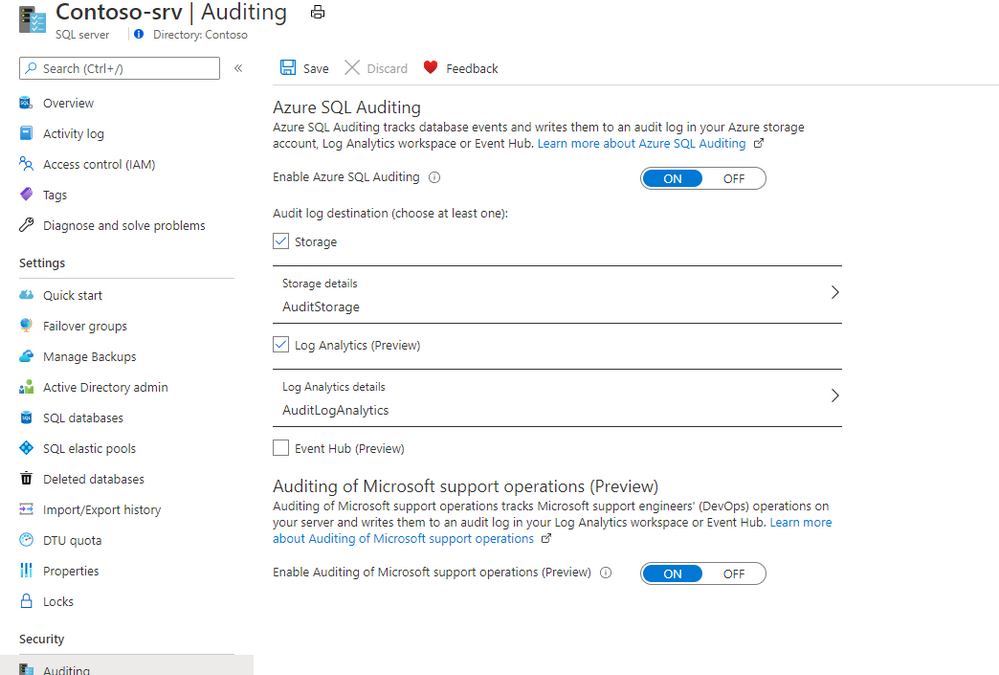
How to enable Auditing of Microsoft support operations
Auditing of Microsoft support operations can be enabled for new and existing Azure SQL Database and Managed Instance. Once enabled, logs will flow to your configured audit logs destination.
Portal
To enable Microsoft DevOps Auditing via the Azure portal for Azure SQL Database:
- Open your Azure SQL Server where your Azure SQL Databases are deployed
- Navigate to Auditing under Security
- Configure a Log Analytics workspace or an Event Hub destination
- Enable Auditing of Microsoft support operations (Preview)

Storage account destination will be added over time. Visit the documentation for up to date information on Auditing of Microsoft support operations.
Please visit the pricing pages of Log Analytics and Event Hub for pricing details for this configuration.

by Contributed | Oct 29, 2020 | Uncategorized
This article is contributed. See the original author and article here.
For some time now, business leaders have made digital transformation a priority. But when the pandemic hit this spring, adopting and embracing digital technology went from being a matter of importance to one of sheer survival. COVID-19 has catapulted us into the era of digital everything. And to keep up with the pace of change,…
The post Power your digital transformation with insights from Microsoft Productivity Score appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments