
by Contributed | Dec 17, 2020 | Technology
This article is contributed. See the original author and article here.
When we deploy SQL Server on AKS, sometimes we may find SQL HA is not working as expect.
For example, when we deploy AKS using our default sample with 2 nodes:
https://docs.microsoft.com/en-us/azure/aks/tutorial-kubernetes-deploy-cluster#create-a-kubernetes-cluster
az aks create
--resource-group myResourceGroup
--name myAKSCluster
--node-count 2
--generate-ssh-keys
--attach-acr <acrName>
There should be 2 instances deployed in the AKS virtual machine scale set:
According to the SQL document:
In the following diagram, the node hosting the mssql-server container has failed. The orchestrator starts the new pod on a different node, and mssql-server reconnects to the same persistent storage. The service connects to the re-created mssql-server.

However, this seems not always be true when we manually stop the AKS node instance from the portal.
Before we stop any nodes, we may see the status of the pod is running.

If we stop node 0, nothing will happen as SQL reside on node 1.

The status of SQL pod remains running.

However, if we stop node 1 instead of node 0, then there comes the issue.

We may see original sql remains in the status of Terminating while the new sql pod stucks in the middle of status ContainerCreating.
$ kubectl describe pod mssql-deployment-569f96888d-bkgvf
Name: mssql-deployment-569f96888d-bkgvf
Namespace: default
Priority: 0
Node: aks-nodepool1-26283775-vmss000000/10.240.0.4
Start Time: Thu, 17 Dec 2020 16:29:10 +0800
Labels: app=mssql
pod-template-hash=569f96888d
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/mssql-deployment-569f96888d
Containers:
mssql:
Container ID:
Image: mcr.microsoft.com/mssql/server:2017-latest
Image ID:
Port: 1433/TCP
Host Port: 0/TCP
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment:
MSSQL_PID: Developer
ACCEPT_EULA: Y
SA_PASSWORD: <set to the key 'SA_PASSWORD' in secret 'mssql'> Optional: false
Mounts:
/var/opt/mssql from mssqldb (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-jh9rf (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
mssqldb:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mssql-data
ReadOnly: false
default-token-jh9rf:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-jh9rf
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/mssql-deployment-569f96888d-bkgvf to aks-nodepool1-26283775-vmss000000
Warning FailedAttachVolume 18m attachdetach-controller Multi-Attach error for volume "pvc-6e3d4aac-6449-4c9d-86d0-c2488583ec5c" Volume is already used by pod(s) mssql-deployment-569f96888d-d8kz7
Warning FailedMount 3m16s (x4 over 14m) kubelet, aks-nodepool1-26283775-vmss000000 Unable to attach or mount volumes: unmounted volumes=[mssqldb], unattached volumes=[mssqldb default-token-jh9rf]: timed out waiting for the condition
Warning FailedMount 62s (x4 over 16m) kubelet, aks-nodepool1-26283775-vmss000000 Unable to attach or mount volumes: unmounted volumes=[mssqldb], unattached volumes=[default-token-jh9rf mssqldb]: timed out waiting for the condition
This issue caused by an multi-attach error should be expected due to the current AKS internal design.
If you restart the node instance that was shutdown, the issue will be resolved.
by Contributed | Dec 17, 2020 | Technology
This article is contributed. See the original author and article here.
This enhanced solution builds on the existing “Connector Health Workbook” described in this video. The Logic App leverages underlying KQL queries to provide you with an option to configure “Push notifications” to e-mail and/or a Microsoft Teams channel based on user defined anomaly scores as well as time since the last “Heartbeat” from Virtual Machines connected to the workspace. Below is a detailed description of how the rule and the logic app are put together. The solution is available for deployment from the official Azure Sentinel GitHub repo on this link .
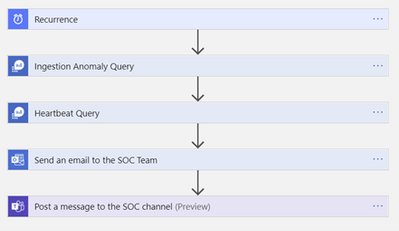
Overview of the steps the Logic App works through
The Logic App is activated by a Recurrence trigger whose frequency of execution can be adjusted to your requirements

Since the Logic App is being deployed from an ARM template you will need to make connections to Azure Monitor, Office 365 and Teams before the Logic App can work in your environment. You can expect to see windows like the one below. Click “Add new” to create a connection for each of the three resources.

The KQL query below will be added to this step in the Logic App and will execute against your workspace. You can modify the threshold values to suit your needs
let UpperThreshold = 3.0; // Upper Anomaly threshold score
let LowerThreshold = -3.0; // Lower anomaly threshold score
let TableIgnoreList = dynamic([‘SecurityAlert’, ‘BehaviorAnalytics’, ‘SecurityBaseline’, ‘ProtectionStatus’]); // select tables you want to EXCLUDE from the results
union withsource=TableName1 *
| make-series count() on TimeGenerated from ago(14d) to now() step 1d by TableName1
| extend (anomalies, score, baseline) = series_decompose_anomalies(count_, 1.5, 7, ‘linefit’, 1, ‘ctukey’, 0.01)
| where anomalies[-1] == 1 or anomalies[-1] == -1
| extend Score = score[-1]
| where Score >= UpperThreshold or Score <= LowerThreshold
| where TableName1 !in (TableIgnoreList)
| project TableName=TableName1, ExpectedCount=round(todouble(baseline[-1]),1), ActualCount=round(todouble(count_[-1]),1), AnomalyScore = round(todouble(score[-1]),1)

Execute query against workspace to detect potential VM connectivity issues

To adjust the lookback period for the last heartbeat received from VMs in the workspace, change the “| where LastHeartbest < ago(5h)” line in the query above
Send out the results of the query to the SOC team as a summarized HTML table

Note that while the two queries use two query outputs named “Body” they are different and care should be taken to select the correct output. Naming the Ingestion Anomaly and the Heart Beat query steps differently will help distinguish between the two “Body” variables.
Send the same message to a Microsoft Teams channel monitored by the SOC team

Below is a sample output of the push notification message

This solution was built in close collaboration with @Javier Soriano , @Jeremy Tan and @Benjamin Kovacevic
by Contributed | Dec 17, 2020 | Technology
This article is contributed. See the original author and article here.
When learning something new there are a lot of phrases, terms and theory to learn and when learning Azure the same is true. One of the things you should be aware of within Azure is the difference and use cases of Availability Zones and Availability Sets.
When we are architecting workloads we see availability is making sure the resources or workloads are there when you need them.
Virtual Machines in Azure
Within Azure when you spin up a virtual machine it gives you an availability of either 95%, 99.5% or 99.9% depending on how you configure your disks with that virtual machine. When you think about it in monthly terms a 95% Service Level Agreement (SLA) allows for around one and half days downtime. For a lot of workload cases and organisations these availability numbers will be more than adequate. If you need more then that’s where Availability Zone and Sets can help.
Availability Sets
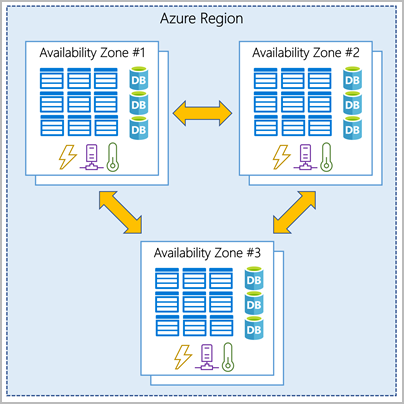
Availability Sets takes the virtual machine and configures multiple copies of it. Each copy is isolated within a separate physical server, compute rack, storage units and network switches within a single datacentre within an Azure Region.
When you create your virtual machine you can specify the Availability Set, you can’t change it or move it in or out of an Availability Set after creation. If you wanted to make changes you would need to start again and recreate the virtual machine. And Availability Sets only apply to virtual machines, they can’t be used for any other type of resource within Azure.
Using an Availability Set takes your acceptable downtime to around 22minutes a month. Which is a vast improvement over the single virtual machine deployment.
Availability Zone
The next level of availability for your virtual machines within Azure is Availability Zones. With Availability Zones utilised your acceptable downtime a month moves to less than 5 minutes as you’ve got a 99.99% SLA.
Availability Zone
With Availability Zones you are starting to use zone aware services. Your workload will be spread out across the different zones that make up an Azure region. An Azure region is made up of multiple datacentres and each zone is made up of one or more datacentres. Each datacentre is equipped with independent power, cooling and networking.
When do use them?
There can be a few deciding factors around Availability Zones versus Availability Sets, you should be thinking about these questions when designing your workloads in Azure:
- Are Availability Zones available in the region I want to use? You can find out which regions support them and which services are support here.
- What SLA or availability does this workload really need? Make sure you really understand the business needs versus the wants. Each configuration will offer you the following:
- 99.9% = Single VM (with Premium SSD or Ultra Disk)
- 99.95% = Availability Set
- 99.99% = Availability Zones
Never Stop Learning
It can feel daunting trying to learn new terminology or technologies however never stop learning, if you learn something new each day, you’ll find it all adds up. And if you are looking to learn more core Azure architectural components, check out this free Microsoft Learn module.
by Contributed | Dec 17, 2020 | Technology
This article is contributed. See the original author and article here.
Hi Team, it’s Eric Jansen again, and as always, I’m excited to show you guys what I have in store for you. Now, I gave you guys a break in Part 2 of the series and kept that one short, but break time is over, team; I’m going back to a bit of a more in-depth discussion today, so buckle up and get comfortable. In this edition and in some future editions of the series, I’ll be focusing on collecting data from the DNS Analytical Log, based on certain use cases and presenting it in a more concise and useful manner. In order to do this, I’ll share some examples of how you can parse the DNS Analytical Log to find possible items of interest, since just scrolling through literally, what can be millions of lines of events, just doesn’t sound like a fun time to me; Nor is it really feasible. Time is money!
For this scenario, I’ve developed a customized Windows based version of the popular Pi-Hole, just without the pretty GUI. I did this using PowerShell, DNS policy, and some block lists from GitHub. This was implemented on a non-domain joined physical server using Windows Server 2019. At the time of this writing the server has over 550K Query Resolution Policies to deny query attempts to domains listed within those QRPs.
Note: An important side note for those that have a similar configuration to mine – there is a hard limit of how many policies you can ‘Get’, using Get-DNSServerQueryResolutionPolicy. That limit is 500K, however you can have more than 500K policies, and they will still work, but once you hit that threshold, you’ll need some custom code (fear not, I’ve already written it and can share to those that are interested) to get past that limit for collecting information about those policies (though Get-DNSServerQueryResolutionPolicy still works fine if you’re querying for a specific policy). A topic that I may or may not discuss in the future.
In my scenario though, I have one domain per QRP (you aren’t limited to that, that’s just what I did), and those domains include ones that host ads, collect telemetry / tracking data, malware, and other unwanted domains. Also, for those wondering, yes, in the build process, I did enable the DNS Analytical log – I’d have a hard time writing the rest of this blog if I didn’t  . As I’ve alluded to previously, the use of DNS ‘black holes’ or ‘sink holes’ is a pretty common use case for DNS policy; as far as I can tell, it’s second only to support requests for Split Brain configurations.
. As I’ve alluded to previously, the use of DNS ‘black holes’ or ‘sink holes’ is a pretty common use case for DNS policy; as far as I can tell, it’s second only to support requests for Split Brain configurations.
In a future post, if there’s interest, I’ll detail that build process and discuss the functions that I’ve written to make everything happen. For the time being, however, let’s dig in to see how we can harvest some useful data from the analytic log for this particular scenario.
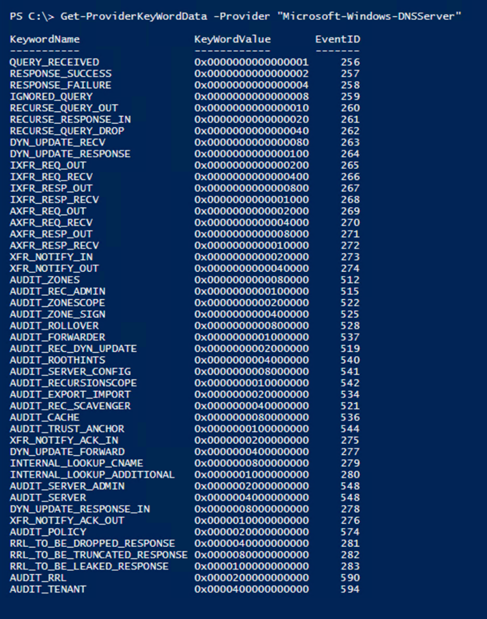
OK, so if we’re going to parse the DNS Analytical Log to harvest any useful data the first thing that we’ll need to know is what events exist to be able to parse, as well as the format for each of those events that we’re interested in parsing. The events themselves are generated based on provider outputs. In Part 1 of the series, I shared the Get-ProviderKeyWordData function with you guys to show the event keywords that the provider would return. Since then, I’ve modified the function to include the event ID’s and message format information, but I’ve only tested its functionality with the “Microsoft-Windows-DNSServer” provider – so no guarantees that it’ll work any others.
The updated code for that is here, and if you’ve been following the series, you may notice a new parameter that I’ve added to the function (–ShowEventStructure), which we’ll use in a minute:
function Get-ProviderKeyWordData ([Parameter(Mandatory=$true)]$Provider, [switch]$ShowEventStructure, [switch]$ShowLevels)
{
$AllProviderData = Get-WinEvent -ListProvider $Provider
$ProviderKeywords = $AllProviderData | select -ExpandProperty keywords
$Events = $AllProviderData | select -ExpandProperty events
$ConvertedKeywordTable = @()
Foreach ($Keyword in $ProviderKeywords){
ForEach($Event in $Events){
If($Event.keywords.name -eq $Keyword.name){
$EventID = $Event.ID
break
}
}
$KWConvertedToHex = "{0:x16}" -f $Keyword.value
$KWHashTable = [Ordered]@{KeywordName = $Keyword.name;KeyWordValue = $("0x" + $KWConvertedToHex);EventID = $EventID}
$ConvertedKeywordTable += New-Object psobject -Property $KWHashTable
}
If($ShowEventStructure){
ForEach($ConvertedKeyWord in $ConvertedKeywordTable){
$ConvertedKeyWord | ft *
$Events | where ID -eq $ConvertedKeyWord.EventID | fl Template, Description
}
}
Else{$ConvertedKeywordTable}
$LevelData = @()
IF($ShowLevels){
$Levels = $AllProviderData | select -ExpandProperty Levels
foreach($Level in $Levels){$LevelData += New-Object psobject -Property @{DisplayName = $Level.DisplayName ;Level = $("0x" +$Level.Value)} }
}
$LevelData | ft -AutoSize
}
The new default output now shows the Event ID of the associated Keyword Value that the provider logs to the DNS Analytical Log:
For the purposes of today’s blog, and in following suit with Part 1 of the series, I’m just going to focus on the Parsing of RESPONSE_FAILURE events – output by the provider as Event ID 258. For the most part, what I show you in regard to parsing this event would apply to all of the others. I only say this because I haven’t written a parser for all of the events seen in the list above (not yet anyhow). The reason that I’m interested in the 258 events (specifically those that are triggered as a result of policy) are because these are the responses that are sent back to clients that are getting queries refused as a result of something that they’re trying to query (knowingly or unknowingly) that resides in the DNS block list (which exist as QRPs).
But why is this of value? How can this help my organization? Well, here’s a handful of reasons for both employing a DNS black hole solution and parsing the analytical logs to see what’s happening in your organization. (But please write a comment if you have other great use cases that I’ve missed):
- Additional means for more granular control of internet access
- You have the ability to block specific domains or hosts with DNS.
- Though block lists can be bypassed, there are other measures that can be implemented in conjunction with them to mitigate that.
- Bandwidth savings
- This could be especially useful in environments that are remote where bandwidth is extremely limited / degraded. Any organization that relies on satellite communications, maybe remote teams in Antarctica, or the shipping industry with numerous vessels on the open ocean, or military units operating in remote locations – you name it. But I wouldn’t even limit it to that, why not save bandwidth even in high speed environments?
- The bottom line is that if a machine or device can’t resolve a host or domain, then it can’t connect to it, and there can easily be hundreds of thousands of attempts per day even in small / medium sized environments, depending on the block list and clients trying to get out.
- Ability to find “Indicators of Compromise” or “IOCs”
- By parsing and analyzing the ‘hit data’, and possibly comparing current findings to historic trends, among other ways, you may be able to find compromised devices in your environment.
- Ability to find cross domain violations
- Some customers have air gapped environments that aren’t supposed to communicate with one another. If one machine gets moved from one of those environments (for example Domain B) to the other (Domain A) and tries to connect to something back on its original domain, if that domain (Domain B) is in the block list, then those violations can be identified, and a security investigation started.
- Those queries can be traced back to the originating client and you can do further auditing to get a good idea of who made the violation (If it, in fact, was a violation).
Now that we see a bit of the value proposition, we need to dig in more to figure out how to parse this data. First, I’ll figure out the structure of the event that I’m interested in. To see what that looks like, we have some options, two of those options are to trigger the event in the live log and take a look at the format or use the Get-ProviderKeyWordData function with the –ShowEventStructure parameter; we’re going to do both for comparison. The use of the –ShowEventStructure parameter will show the XML Elements and child elements in the template property, as well as the structure of the message in the Description property. It dumps this info for ALL events for the defined provider, so your screen may get busy if you run the following command:
Get-ProviderKeyWordData -Provider “Microsoft-Windows-DNSServer” –ShowEventStructure.
Note: You can’t see the command that I ran because I just snipped the data that I was interested in from a much larger list. Again, I’m just showing the part that I’m interested in.

So now let’s compare this to an actual event and see what we can do to pick the event apart for harvesting purposes. So, I ran the Show-DNSAnalyticLog function (more on this function can be found here), looking only for 258 events, selecting the first one found, showing all properties in a list format:

The Result:

Note: The way I collected the ‘258 Event’ in the screenshot above is definitely not the best way to go about this, I just happened to have recently cleared the log so there wasn’t much in it; That and I’m just looking for the first one, so it returned data pretty quickly. If you have millions of events however, and maybe the first event is towards the end of the log, you definitely don’t want to send them all through the pipeline for data collection. This was purely for demonstration purposes…but since I’m already going down the rabbit hole, I might as well give you some metrics to look at.
To give you an example of the speed difference, look at the difference between using a hash table (I’m hiding the hash table version of the collection method in the screenshot below, because I’ll be discussing it more, in greater depth, in just a bit . ) to find the ‘258 events’ vs collecting all events and sending them through the pipeline. Keep in mind that a full log could take SIGNIFICANTLY longer, and everyone’s mileage may vary depending upon resources:

Ok, I’m back out of the rabbit hole, and back to the primary discussion. So, yes…I’m mainly interested in the Message property. I’ll split the property on the semi colon since it splits up the child elements of the message property nicely, and see if I can make it more closely resemble the XML template that I showed you guys earlier:

Ok, that’s a lot closer to what we see in the XML template. When parsing and collecting data, now you’d just need to decide what data is of interest to you, and why. For this particular scenario, I decided that I wanted to collect the following data:
- The Event ID, which is actually a property of its own.
- I’d want this because I’d likely parse multiple events in a single parsing cycle, and not just 258 Events – but for this scenario, I’m just parsing 258 Events.
- The Query Source (seen above as the Destination), so that I know where the query originated from.
- Though the element name is ‘Destination’, that is where the server is sending the failure response, which makes it the ‘Query Source’.
- The Query (seen above as the QNAME), so that I know what FQDN was being queried.
- The Query Type (seen above as QTYPE), so that I know if it was queried via IPv4 or IPV6.
- The Policy (seen above as PolicyName), so that I know which policy blocked the query.
- The TimeStamp, which is actually a property of its own, but useful so that I know when the query response took place.
- The XID (also known as the ‘Transaction ID’), so that I can look at client / server transactions.
- The GUID, so that I can follow complete conversations, since that’s not possible with just the XID.
OK, log file defined, event picked, properties of the event decided upon, and even child elements decided upon, so how do we go about collecting all of this? Well, the first thing that we need to do is collect the data from the DNS Analytical log so that we can parse it. The most efficient way that I know of to accomplish this is by using the Get-WinEvent cmdlet with the –FilterHashTable parameter.
Let’s do it! Below is a code sample to demonstrate how I built the hash table filter, and its functionality with Get-WinEvent:
#Define the DNS Analytical Log name.
$EventLogName = 'Microsoft-Windows-DNSServer/Analytical'
#Step 1 for Parse-DNSAnalyticLog.....does the Analytical log even exist on the computer?
If(Get-WinEvent -listlog $EventLogName -ErrorAction SilentlyContinue){
$DNSAnalyticalLogData = Get-WinEvent -listlog $EventLogName
If(($DNSAnalyticalLogData.LogFilePath).split("")[0] -eq '%SystemRoot%'){
$DNSAnalyticalLogPath = $DNSAnalyticalLogData.LogFilePath.Replace('%SystemRoot%',"$env:Windir")
}
}
#Define the event or events that you're interested in collecting.
[int[]]$EventIDs = 258
#Build the HashTable for use with Get-WinEvent
$FilterHashTable = @{
Path="$($DNSAnalyticalLogPath)"
ID=$EventIDs
}
$FilterHashTable = @{
Path=$DNSAnalyticalLogPath
ID=$EventIDs
StartTime= $LastIterationLastEventTimeStamp
}
#Validate functionality
Get-WinEvent -FilterHashtable $FilterHashTable -Oldest -ErrorAction SilentlyContinue
Below shows that the filter works, since it is only returning 258 events, and just as an FYI, for this demonstration, I am logging all events from the provider to the Analytical Log. I haven’t limited the output of the provider, as I demonstrated how to do in Part 1 of the series.

Awesome, we‘ve just confirmed that the filter finds the data that we’re interested in, so we can now work on picking it apart to generate more useful statistics. Ok, so how do we do that? There’s a lot of different ways. What I decided to do was create a custom PSObject to build a customized table and then I just used string manipulation to pick out just the pieces that I was interested in, to store into the PSObject. I chose string manipulation because it’s fast and it’s easier to understand for most folks reading this, over regular expressions, for example (where I have to re-learn them every time I use them  ). Here’s a snippet of code with some comments to help anyone that needs it.
). Here’s a snippet of code with some comments to help anyone that needs it.
Note: For the code below to work, the above code must be run in order to populate the $FilterHashTable variable. Also, I did find one scenario where the message property data was different, so in some scenarios (regardless of what you see in the event template above for event ID 258) you may see an error complaining about writing null data to the pscustomobject. If that’s the case, and for those following along, then you may need to modify the code below. The scenario that I’m aware of would require the following change:
GUID=$Event.Message.Split(“;”)[15].trim(” “).substring(5)
would need to be to be changed to:
GUID=$Event.Message.Split(“;”)[14].trim(” “).substring(5)
This is the case because in some scenarios the “ElapsedTime” field isn’t returned in the 258 event. Once I figure out why, I’ll update the post.
$i = 0 #Counter for the number of events that were parsed in total.
$j = 0 #Counter for the number of 258 events that were parsed in total.
$k = 0 #Counter for the number of 258 events that were a result of a policy match.
$l = 0 #Counter for the number of 258 events that were NOT a result of a policy match.
#Defining the HitData variable as a collection and nullifying the data within.
$HitData = @()
$HitData = foreach ($Event in (Get-WinEvent -FilterHashtable $FilterHashTable -Oldest -ErrorAction SilentlyContinue)){
$i++ #Increment Counter
#In this case, I took this code snippet from a much larger function that parses multiple Event IDs, so this just picks out the 258 events.
If($Event.ID -eq 258){
$j++ #Increment Counter
#I'm only interested in the 258 events that were a result of a policy hit.
IF($Event.Message.Split(";")[2].toLower().trim(" ") -eq "reason=policy"){
#Created a custom PSObject with the eight properties below, using string manipulation to only collect the parts of the element that I needed.
[pscustomobject]@{
#Split the message property on the semicolon, choosing the index (15 for example), trim the spaces,
#and then skip the beginning characters (5 for example), collecting only what remains.
GUID=$Event.Message.Split(";")[15].trim(" ").substring(5)
Query=$Event.Message.Split(";")[4].trim(" ").substring(6);
QuerySource=$Event.Message.Split(";")[3].trim(" ").substring(12);
QType=$Event.Message.Split(";")[5].trim(" ").substring(6); #Query Type 1 = IPv4, Query Type 28 = IPv6
Policy=$Event.Message.Split(";")[11].trim(" ").substring(11);
XID=$Event.Message.Split(";")[6].trim(" ").substring(4)
EventID=$Event.Id;
TimeStamp=$Event.TimeCreated;
}
$k++ #Increment Counter
}
Else{
$l++ #Increment Counter
}
}
Else{
Write-Host "No blackholed domain hole hits were found, and thus, there's nothing that needs to be parsed!" -ForegroundColor Green
Return
}
}
Now, we run the code above. So, what does it look like, and did we meet the goal of parsing the event and collecting only the specific data of interest? Well, let’s see:

Boom! We won! It’s so pretty!
Ok, it’s just an array of data in a custom object that contains only the data that I wanted to collect, but I think it’s pretty.. I can hear you guys now though:
“OK, how is this better than just finding the 258 events, which we already know how to do? It looks like we’re just taking the same info that’s in the log and just moving it around a bit on the screen.”
That’s a great question!
Well, now that we have the data in a separate variable, we can do a lot with it. We can build reports, for example. The report could contain the following and more:
- Total 258 Events / Total blocked Queries
- Total 258 Events / Total blocked Queries, that were a result of a policy.
- Unique blocked queries (based on the Transaction IDs).
- A list of unique domains that the clients are trying to get to, that they aren’t allowed to get to.
- The number of unique domains in that list.
- A list of which clients are trying to get to those domains.
- Though if you have a tiered DNS forwarding hierarchy in place this may take a little extra work, depending upon where the QRPs have been deployed.
- Percentage of total queries being blocked during the timeframe of events that were in the log, at the time of the parse operation.
- Percentage of domains being queried and blocked, out of the total list of QRPs / domains that are in the block list.
- Etc.
The next thing that I want to do since I’ve successfully collected the parsed data, is export all of what I’ve deemed useful, so that maybe it can be ingested into SQL for tracking historical data. In addition to that I want to further refine this data to build a more concise report that could potentially be e-mailed or even written to its own event log… But I don’t want to make this post any longer than it already is, so I’ll continue this in the next post... I know, I know, such an abrupt ending – I’m practicing the art of writing cliffhangers. 
Oh yeah, I almost forgot to mention that all of my code comes with the following disclaimer:
The code snippets above are considered sample scripts. Sample scripts are not supported under any Microsoft standard support program or service. The sample scripts are provided AS IS without warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
Until next time!

by Contributed | Dec 16, 2020 | Technology
This article is contributed. See the original author and article here.
SAP Connector
The Logic App SAP Connector is a Generally Available component for Azure which allows easy integration with SAP ECC and S/4 HANA today.

This connector enables:
- RFC based integrations – IDOC/BAPI
- Bi-directional SAP integration
- Advanced capabilities – SNC, stateful sessions
- tRFC for IDOC – Send IDOCs to SAP only once
- Implicit Commit to commit BAPI calls
- Stateful BAPI calls
- SNC with certificate
Additional capabilities are coming soon:
- SNC support for ISE
- Stateful RFC calls
Multi-tenant setup
When using this connector in our multi-tenant offering, customer needs to deploy the On-Premises Data Gateway (OPDG) to bridge from the Azure cloud to the private network containing the SAP instance to connect to. Generally no production SAP system is directly exposed to the Internet. Furthermore the OPDG allows the customer to install the necessary SAP client libraries “SAP .NET Connector” also known as SAP NCo.
The detailed installation instructions are available in the connector’s public documentation, with this subsection specific to multi-tenant environment.
From Logic App to SAP

Logic App SAP Connector (LA) makes calls to the gateway cloud service (CS) which acts as relay to the OPDG. Internally the CS uses Azure Service Bus and the OPDG can be used to connect to a range of other back-end services besides SAP such as SQL, SharePoint, File shares. Full architecture for the gateway service can be learned in this public documentation article.
On the OPDG the SAP adapter creates an RFC Client (RFC-C) via the SAP NCo library which finally talks with the SAP system.
The messages send this way may have a synchronous response. Such is the case when calling a list method on a BAPI business object for instance.
Some other messages are asynchronous by nature, like sending an IDOC, and while there is no response from the SAP system, the transaction Id of the underlying call is returned by the SAP adapter to allow later de-duplication and troubleshooting.
For advanced used it is also possible to transmit payloads larger than the 2.5 MB allowed by the gateway Azure Service Bus relay. This requires uploading the payload to an Azure Storage blob accessible from the private network, and provide the full SAS URL instead of the payload in the call to the LA SAP Connector.
SAP to Logic App

For SAP to initiate calls to Logic App via the SAP Connector Trigger, LA sends an initial registration message when the trigger is first saved and each time it is modified. The SAP Adapter on the OPDG will register an RFC Server (RFC-S) with the SAP system. This RFC Server is identified by a Program Id inside SAP such that RFCs and BAPI methods may be call against it, or IDOC may be send to a Logic System (LS) partner configured for this Program Id. The OPDG SAP adapter will relay the calls from SAP to the RFC Server as HTTP Webhook callbacks to Logic App. The Logic App may further synchronously respond on the Webhook with a response payload for SAP.
The detailed steps to configure sending IDOCs to SAP are part of the public documentation for the connector in this subsection.

Recent Comments