This article is contributed. See the original author and article here.
Background MediamarktSaturn is the leading consumer electronics retailer in Europe with more than 1000 stores spread over 13 countries in Europe. We started to rollout Yammer as one of our first Microsoft 365 apps to office workers in May 2018. In March 2020, we continued to roll it out to first line workers in Germany and Spain, two of the largest customer markets.
Initially, we had slow adoption of Yammer and did not see the network effect take off the way we knew it could. We needed to focus on making sure our employees knew and understood the purpose of Yammer, and we decided to focus on four strategic initiatives:
Specific use cases and connecting the store employees to hq departments
Consistent community management
Shifting the focus of conversations from selling used goods to using Yammer for CEO Communications
Communities app in pinned Microsoft Teams deployed to all employees
Store employees now get information from Yammer One tactic we implemented was to include store employees in our Yammer communities to connect to other stores. Now, they can ask employees at headquarters questions, and give feedback like never before. The ability to ask and answer questions has been a huge driver of adoption. Our store employees access Yammer on their own time, and they will have access to company mobile devices with Yammer installed for them.
Now, our employees are better informed, and contribute their involvement in Yammer communities and conversations to their learning and growth at MediaMarktSaturn.
What does consistent community management look like? We have created the same story about why and how employees are using Yammer in order to bring awareness to different department and use cases. Yammer enables our employees the ability to connect with the right people to find answers, and now, we can measure progress and share our success stories with communities to encourage participation. Previously, we had heard rumors and the grumbles about employee dissatisfaction, but now we have a way to react and educate our employees about what’s being shared, all out in the open where any employee can contribute.
CEO Communications in Yammer Leadership connection on Yammer has been key for us. Our CEO Ferran Reverter Planet, now shares regularly on Yammer. And most recently he shared about a new strategy, which really showcases some of the reasons behind the shift in strategy. This two-way communication between the leadership and the associates allows for open dialog about these upcoming changes, and empowers employees at every level to ask questions and get answers.
Our CEO is also very active in starting, replying and reacting to conversations.
The Communities app in Teams Microsoft Teams officially rolled out July 2020, with early adopters taking to it as early as March when many began working remotely. Prior to the official rollout, we pinned the Communities app in Teams on June 1st for all MediamarktSaturn employees in the Teams side-bar, including firstline workers at the stores.
Corporate communications worked with IT to start a campaign in Yammer highlighting the new possibilities of using Yammer in Teams. This campaign focused on the benefits of having all communications (1:1, team, 1:many, and all employees) in one place.
Additionally, we communicated to employees “when to use what?”, providing them with suggestions and guidance on when to use which tool and best practices for each tool.
What we’ve learned and what’s next We learned that the Communities app in Microsoft Teams is a great driver for adoption. As additional Yammer features become available in the Communities app many existing Yammer users may primarily use Yammer in Teams as they find it to be the most convenient solution to interact within their communities. In just one month almost 25% of Yammer users have already shifted and we anticipate more to follow.
We have also uninstalled the Yammer Desktop App on all computers in the headquarters. Employees who used to see Yammer in the morning now switch to Microsoft Teams for a similar experience.
Furthermore, we are working on rolling out to the rest of the organization. We know with more people gaining access to Yammer, the more knowledge and opportunity our employees have to ask questions, get answers and provide feedback. Additionally, we are expanding our leadership engagement by encouraging every Country Manager to share and have a voice on Yammer.
Finally, we are working hard to rollout our new intranet and will be using Yammer to help facilitate communications about the changes. Within the intranet we will also be using the new Yammer SharePoint conversations webpart.
Looking back we realized giving everyone a voice helped moved the needle on important conversations and strengthen relationships and communities from the retail stores back to headquarters. Yammer has helped us improve processes and listen to feedback so we can react to employees in new ways. We can’t wait to see what is to come for us in the future.
More about Enrico Dreher
Social Collaboration & Corporate Community Manager, MediaMarktSaturn
Enrico is responsible for project management, implementation of Yammer; he is Corporate Community Manager for Yammer; Project management, conception and realisati-on of a social intranet based on O365 + Powell 365; Enrico also writes an internal company blog about Community & Collaboration and works with the business departments in using communication and collaboration tools
This article is contributed. See the original author and article here.
Importance of application resiliency in the cloud
High availability is a fundamental part of SQL Managed Instance (MI) platform that works transparently for your database applications. As such, failovers from primary to secondary nodes in case of node degradation or fault detection, or during our regular monthly software updates are an expected occurrence for all applications using SQL Managed Instance in Azure. This is why it is important to ensure your applications (legacy apps migrated to the cloud or cloud born apps) are “cloud-ready” and resilient to transient errors typical for the cloud environments.
Your cloud-ready apps need to follow these principles:
The application must be able to detect faults when they occur
The application must be able to determine if the fault is transient
The application needs to retry an operation in case of transient issues and keep count of the retries
The application must use an appropriate strategy for the retries (number of retries, delay between each attempt)
Recommended best practices for making your apps cloud-ready are:
Use the latest drivers to connect to SQL Managed Instance. Newer drivers have a stronger implementation of transient error handling resiliency.
Use the latest drivers to your advantage, the following parameters are recommended to be added to your application connection string for SQL MI: “Connect Timeout=30;ConnectRetryCount=3;ConnectRetryInterval=10”.
Implement retry logic in your applications for all transient errors common to the cloud environment. See this sample source code for the connection retry logic. Use this as a template to modify your apps.
Finally, test your applications for the resiliency using user-initiated manual failover for SQL Managed Instance (subject of this blogpost).
To learn more on building cloud-ready apps and test them with user-initiated failover functionality for SQL Managed Instance, see the embedded video (15 minutes in length):
To learn more how to execute and monitor user-initiated failover on SQL MI, read further:
Initiate SQL Managed Instance failover on-demand
In August 2020, we have released a new feature user-initiated manual failover allowing users to manually trigger a failover on SQL Managed Instance using PowerShell or CLI commands, or through invoking an API call. Manually initiated failover on a managed instance will be an equivalent of the automated failover for high availability and software patches initiated automatically by the service.
This functionality will allow you to test your applications end to end for transient errors fault resiliency on automatic failovers in case of planned or unplanned events before deploying to production. In addition to testing how failover impacts existing database sessions, it can also help verify if it changes the end-to-end performance due to changes in the network latency. In some cases, if performance issues are encountered on SQL MI, manually invoking a failover to a new node can help mitigate the performance issue.
Because the restart operation is intrusive and a large number of them could stress the platform, only one user-initiated manual failover call is allowed every 15 minutes for each managed instance (this was reduced from the original 30 minutes in October 2020).
Ensuring that your applications are failover resilient prior to deploying to production will help mitigate the risk of application faults in production and will contribute to application availability for your customers.
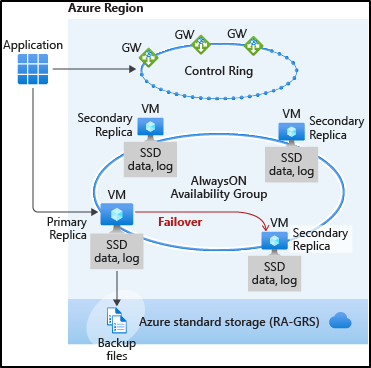
How is High Availability (HA) implemented on a Managed Instance?
Azure SQL Managed Instance (MI) is offered in two service tiers, one is Business Critical (BC) and the other one is GP (General Purpose). Both service tiers offer High Availability (HA), with different technical implementations, as follows:
HA for SQL Managed Instance BC (Business Critical) service tier was built based on AlwaysOn Availability Groups (AG) technology, resulting in such MI consisting of the total of 4 nodes – one primary and three secondary R/O replicas. In case of a failover, one of the secondary replicas becomes primary. This type failover typically takes only a few short seconds.
HA for SQL Managed Instance GP (General Purpose) service tiers was based on multiple redundancy of the storage layer and it is based on a single primary node. In case of a failover, a new node is taken from the pool of standby nodes, and the storage is re-attached from the old to the new primary node. This type of failover typically takes under a minute.
Using the user-initiated manual failover functionality, manually initiating a failover on MI BC service tier will result in a failover of the primary node to one of the three secondary nodes. As secondary read-only nodes on the MI BC service tier can be used for read scale-out from a single node (out of three read-only secondary nodes), the user initiated manual failover capability allows also a failover of read-only replica. This means that users can manually failover the read scale-out from the current to one of the two other available read-only secondary nodes.
Manually initiating a failover on MI GP service tier will result in deallocation of the primary node, and allocation of a new node from the pool of available nodes, and reattachment of the storage from the old to the new node.
How to initiate a manual failover on SQL Managed Instance?
RBAC permissions required
User initiating a failover will need to have one of the following RBAC roles:
The minimum version of Az.Sql needs to be v2.9.0 (download link), or use Azure Cloud Shell from the Azure portal that always has the latest PowerShell version available.
If you have several Azure subscriptions, first ensure that you select the appropriate subscription where your target SQL MI is located:
PowerShell
Select-AzureRmSubscription <SubscriptionID>
Use PS command Invoke-AzSqlInstanceFailover with the following example to initiate failover of the primary node, applicable to both BC and GP service tier:
Use az sql mi failover CLI command with the following example to initiate failover of the primary node, applicable to both BC and GP service tier:
CLI
az sql mi failover -g myresourcegroup -n myinstancename
Use the following CLI command to failover read secondary node, applicable to BC service tier only:
CLI
az sql mi failover -g myresourcegroup -n myinstancename –replica-type ReadableSecondary
Using Rest API
For advanced users who would perhaps like to automate failovers of their SQL Managed Instances for purposes of implementing continuous testing pipeline, or automated performance mitigators, this can be accomplished through initiating failover through an API call, see Managed Instances – Failover REST API for details.
To initiate failover using REST API call, first generate the Authentication Token. One way to do that is to use a Postman client. Initiating the API call from any other client should generally work as well. This token is used as Authorization property in the header of API request and it is mandatory.
The following is an example of the API URI to call:
The following are API call properties that can be passed in the call:
API property
Parameter
subscriptionId
Subscription ID to which managed instance is deployed
resourceGroupName
Resource group that contains managed instance
managedInstanceName
Name of managed instance
replicaType
(Optional) (Primary|ReadableSecondary)
This is the type of replica to be failed over: primary or readable secondary. If not specified, failover will be initiated on the primary replica by default.
api-version
Static value and currently needs to be “2019-06-01-preview”
API response will be one of the following two:
202 Accepted
One of the 400 request errors.
Track the operation status
Operation status can be tracked through reviewing API responses in response headers.
Note: Completion of the failover process (not the actual short unavailability) might take several minutes at a time in case of high-intensity workloads. This is because the instance engine is taking care of all current transactions on the primary and catch up on the secondary, prior to being able to failover.
Monitoring the failover
SQL MI Business Critical
To monitor the progress of user initiated manual failover for Business Critical service tier, execute the following T-SQL query in your favorite client (such is SSMS) on SQL Managed Instance. It will read the system view sys.dm_hadr_fabric_replica_states and report replicas available on the instance. Refresh the same query after initiating the manual failover.
T-SQL
SELECT DISTINCT replication_endpoint_url, fabric_replica_role_desc FROM sys.dm_hadr_fabric_replica_states
Receiving success confirmation from a PowerShell command, or from the API response indicates a successfully completed failover operation. Therefore, monitoring of the failover process is not required. It is however shown in this article for illustration purposes only. Please note that examples in this article do not include monitoring failover of secondary for SQL MI BC SKU.
T-SQL output prior to initiating the failover will indicate the current primary replica on the MI BC containing one primary and three secondaries in the AlwaysOn Availability Group.
In this example we see the primary and three secondary replicas on MI BC node, each assigned to an internal IP address starting with 10.0.0.X. The primary node in this example has been allocated to the internal IP address 10.0.0.16.
Upon execution of a failover, running this query again would need to indicate a change of the primary node.
In this particular example, we can see that before the failover, the primary node IP was 10.0.0.16, whereas after the failover this node became secondary, and the new primary node became node with the IP 10.0.0.22.
Monitor failover of secondary replica for BC (Business Critical) Service tier
Monitoring failover of secondary replica for MI BC is not available through DMVs. Receiving a response of success from PowerShell or API is sufficient confirmation that failover has been successful.
Monitor failover for GP (General Purpose) Service tier
As MI GP service tier is a single node system replaced with another node on the failover, you will not be able to see the role change using the above DMV example for MI BC service tier. Your T-SQL query output for MI GP service tier will always show a single node before and after the failover, something as the following:
However, there is an alternative way to monitor the GP instance failover by looking at the last start time of the SQL engine before and after the failover. Use the following T-SQL command before and after the failover to see the SQL engine start time change:
T-SQL
SELECT DISTINCT sqlserver_start_time, sqlserver_start_time_ms_ticks FROM sys.dm_os_sys_info
The output will be the timestamp when the SQL engine was started which should be different before and after the failover. For example, your output before the failover might show something as follows:
After the failover, the timestamp will be further in time than the previous reading. This indicates a new start time of the SQL engine, therefore indicating that failover has occurred.
Also consider the following to note the failover is in progress:
Upon executing the failover of MI GP, if you refresh any T-SQL query there will be no availability (loss of connectivity) from your client until the node failover has been executed (typically under a minute), after which the query will show the same IP of the primary replica. This loss of connectivity to MI GP during the failover will be the indication of the failover execution.
Functional limitations
Throttle mechanism is implemented to guard from potentially too many failovers. As such, you can initiate one failover on the same MI every 15 minutes. If this is the case, there will be an error message shown when attempting to initiate a manual failover within this protected time frame.
For BC instances there must exist quorum of replicas for the failover request to be accepted. This means that failover can be executed only in the case all replicas are healthy. If this is not the case, and if one of replicas is unhealthy or being rebuilt, you will not be able to manually initiate a failover at such time.
It is notpossible to specify which readable secondary replica to initiate the failover on. The system will determine this automatically. is because MI allows automatically for only a single read-only replica to be available to customers.
If there was a database recently created on SQL MI, user-initiated failover will not be possible until automated systems perform the first full backup of a new database. This is to protect the automated backup process from the failover and ensure backup integrity. Depending on the database size that needs to be backed up for the first time, the time to wait until you are able to initiate a failover might vary.
Disclaimer
Please note that products and options presented in this article are subject to change. This article reflects the user-initiated manual failover option available for Azure SQL Managed Instance in January, 2021.
Closing remarks
If you find this article useful, please like it on this page and share through social media.
This article is contributed. See the original author and article here.
As today’s world expands with a massive wealth of customer information gleaned from brand interactions, purchases, services, and experiencestruly understanding your customers is of the upmost importance. The traditional approach of analyzing one piece of purchase data or one simple survey is insufficient for businesses looking to make an impact on the bottom line. With more information comes more opportunity to increase sales with effective marketing, but it also comes with a challenge: privacy.
According to a 2020 study conducted by Forrester1, protecting customers’ personal information and privacy was the top priority for marketing decision makers when considering customer analytics.
Gathering and tracking customer metrics is critical for a business to build better customer experiences and respond in the moments that matter. With Dynamics 365 Customer Voice, organizations can send direct surveys and collect customer feedback, then analyze it using powerful, built-in artificial intelligence to uncover key customer insights. Now, semi-anonymous surveys create peace of mind for customers when responding to surveys so you can receive more reliable feedback while protecting privacy.
Not only do semi-anonymous surveys enable you to understand your customers, but they can also be an important tool in listening to your employees. With Dynamics 365 Customer Voice, you can capture internal feedback and monitor responses only by title, department, and work location, keeping personal identifiers out.
The new semi-anonymous survey feature allows organizations to select which fields they want to keep anonymous, and which fields to track. For example, you can select to keep relevant location such as location of purchase but exclude personal information such as name and email. This gives organizations even more power managing their data. With rich data now at organizations’ fingertips, departments can align on marketing decisions to build better experiences and lifelong fans.
The value of customer data
Your business is only as successful as your understanding of your customers and data.
A Forrester study in 20182 found that data-driven organizations are growing at an average of 30 percent or more annually.
With Dynamics 365 Customer Voice, the customer understanding process is simplified with easy-to-use survey creation, data analysis, integration with your other applications, and automatic notifications so you can meet the customer at every moment. Now, with added functionality for survey reminders, you can be sure to capture all relevant feedback and information to uncover rich insights.
Ultimately, data-driven and customer-centric organizations are at a competitive advantage because they understand the value of how better insights lead to more sales. Many organizations are missing the key piece of an easy-to-use direct feedback management solution, holding them back from creating a holistic view of the customer and maximizing data’s value. Dynamics 365 Customer Voice empowers a complete understanding of your data, linking together direct and indirect feedback directly in Microsoft Dynamics 365 and enabling better customer experiences.
Get started today
Customer privacy is key when collecting data and making decisions. Dynamics 365 Customer Voice empowers you to bridge the gap between uncovering key customer insights and protecting personal information, allowing you to build meaningful relationships for long-term success. With unified customer profiles linked across your business applications, customer-first and employee-first organizations can act quickly on feedback and drive great experiences.
This article is contributed. See the original author and article here.
Faced with an unprecedent global crisis that disrupted classrooms around the world, educators demonstrated perseverance, agility, and creativity in quickly adapting to an online classroom environment. As remote and hybrid learning continues into 2021, we know that maintaining secure and productive classrooms remains one of your top concerns. Creating safer distance learning environments is a two-fold effort involving both the policies and safeguards enabled by IT Admins in schools and districts, as well as the daily best practices of educators. With that goal in mind, we’ve pulled together five tips you can start using today to help keep your classroom meetings safe, productive, and fun.
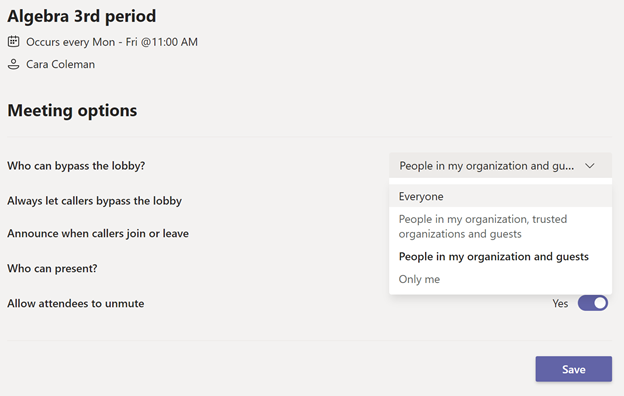
Tip 1: Decide who can do what, ahead of time Before your class begins, it’s important to choose how you’d like your students to join and interact during the class.
When setting up a meeting for your class in Teams, adjust the online meeting options to determine who can bypass the lobby, who can share content, and if you’d prefer attendees to be muted when you begin class.
Tip 2: Make sure the right people have access Every classroom is different. Today, a guest speaker may be joining your class. To avoid any uninvited guests, we recommend setting Always let callers bypass the lobby to Only Me most of the time. When you know a guest will be joining you, you can edit the strictness of this setting. This way, students and others joining your class meeting will automatically wait in a virtual lobby before you admit them.
Tip 3: Control who can present their screen or share content It’s “show and tell” time for one of your students, so they need to be able to share with the rest of the class.
As a rule, everyone should join as a standard attendee without the ability to present or share content. That way, you control the agenda of the class. However, if you have a guest presentation planned, you can grant the presenter role in Meeting options. Need a student to present while class is going? No problem! You can grant presenter permissions to specific attendees during the class and change them back to attendees after their presentation is done.
Tip 4: Mute all meeting attendees or specific individuals Let’s face it, sometimes you need to focus class on one voice, or mute disruptive background noise—barking dogs, traffic, you name it!
Here you have a couple of options: If you need to make sure there are no interruptions, you can mute all the attendees to make sure the whole class stays focused on the lesson’s content. Or, mute specific attendees at any time.
Tip 5: End the class for all attendees It’s safer for students if they do not have access to a meeting after it’s over, especially if you’ve already left the call.
At the end of class, make sure that you end the meeting for everyone. Instead of selecting Leave, make sure to select the dropdown arrow and click End meeting.
Thanks for following along! Please let us know how else we can support you and your students in your distance and hybrid learning journeys.
This article is contributed. See the original author and article here.
Microsoft is committed to continually extending Microsoft Defender for Endpoint capabilities across all the endpoints you need to secure, and today we’re excited to announce that Defender for Endpoint for Windows Virtual Desktop is now generally available! In this post we’ll briefly go over what this means, and what the experience looks like in the Microsoft Defender Security Center.
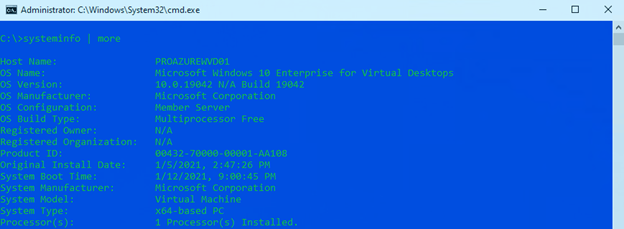
Defender for Endpoint now supports Windows Virtual Desktop with up to 50 concurrent user connections for Windows 10 Enterprise multi-session (listed here as “Microsoft Windows 10 Enterprise for Virtual Desktops”)
Single session scenarios on Windows 10 Enterprise are fully supported and onboarding your Windows Virtual Desktop machines into Defender for Endpoint has not changed.
There are several new items in the Microsoft Defender Security Center that you’ll see have been added to support Windows Virtual Desktop, we’ll detail them in the following sections.
Device Inventory Page
On the device inventory page, select “filters” to see a new “Windows 10 WVD” filter under OS Platform that you can use to view only Windows Virtual Desktop machines. Identify Windows Virtual Desktop machines by looking for “Windows 10 WVD” in the OS platform column of the table.
Device Page
On the device page in the left fly out, you’ll also see that Windows Virtual Desktop is reflected under the device details section. Under “OS” you’ll see “Windows 10 WVD x64” indicating that it’s a Windows Virtual Desktop machine.
The device page will also show the number of logged on users in the past 30 days on the overview tab.
Selecting the “See all users” link will allow you to see the complete list of users. You’ll have a number of columns at your disposal including “Logon Type,” which for Windows Virtual Desktop will be “logon type 10” or “RemoteInteractive.”
The changes thus far are there to help you identify Windows Virtual Desktop machines in the Microsoft Defender Security Center. The data that is collected, and the investigation experience that you are used to with all other supported endpoint types, remains mostly unchanged. You can expect the majority of the functionality and capabilities such as the device page, response actions, threat and vulnerability management, Microsoft Secure Score for Devices, software inventory, etc. to all still work in the same way they do for Windows 10 and other supported devices. However, there are some things to take note of in a few key areas of the security center which we’ll walk through below.
Machine Timeline
The machine timeline will be populated with cyber telemetry from all active user sessions on the Windows Virtual Desktop machine. This allows analysts to see all events happening on the machine and also gives the option to investigate timeline events that are specific to a particular user session. As an example, I’ve flagged a couple of events in the machine timeline from five different users who are logged on concurrently to a Windows Virtual Desktop machine:
If you want to see all activity related to a specific user, simply search for the username to display all associated cyber telemetry:
All of the machine timeline capabilities such as search, filters, flagging, columns, time span, etc. still work the same way as they do with other devices.
Advanced Hunting
All of the cyber telemetry data reported by Windows Virtual Desktop machines will be available in advanced hunting. For example, you may want to see process events or image loads related to a specific user session and this can be accomplished by using columns that are already present in the advanced hunting schema:
Perhaps you want to check browser network events by user on a Windows Virtual Desktop host for the last 24 hours:
For the last example, you may want to check for currently logged on users via the DeviceInfo table, as you can see here at 1/13/2021 1:25:19 there are five users concurrently logged on to this specific Windows Virtual Desktop host:
These are just a few examples that target all or specific user sessions for data insights via advanced hunting. Continue to reference the schema and use your imagination and creativity for unique data insights!
Incidents and Alerts
This experience in the portal remains unchanged, here is an example alert that is triggered for a user on a Windows Virtual Desktop machine:
Note on licensing: When using Windows 10 Enterprise multi-session, depending on your requirements, you can choose to either have all users licensed through Microsoft Defender for Endpoint (per user), Windows Enterprise E5, Microsoft 365 Security, or Microsoft 365 E5, or have the VM licensed through Azure Defender.
We’re excited to share this milestone with everyone, and we hope this better enables organizations who are embracing user productivity virtualization to protect these unique Windows Virtual Desktop assets. Let us know what you think by leaving a comment below!
If you’re not yet taking advantage of Microsoft’s industry leading security optics and detection capabilities for endpoints, sign up for a free trial of Microsoft Defender for Endpoint today.
Jesse Esquivel, Program Manager Microsoft Defender for Endpoint
![[Customer story] Communities app in Microsoft Teams brings adoption to employees in headquarters](https://www.drware.com/wp-content/uploads/2021/01/600x849-600x675.)



























Recent Comments