This article is contributed. See the original author and article here.
Introducing Unified Neural Text Analyzer: an innovation for Neural Text-to-Speech pronunciation accuracy improvement
This post is co-authored by Dongxu Han, Junwei Gan and Sheng Zhao
Neural Text-to-Speech (Neural TTS), part of Speech in Azure Cognitive Services, enables you to convert text to lifelike speech for more natural user interactions. Neural TTS has powered a wide range of scenarios, from audio content creation to natural-sounding voice assistants, for customers from all over the world. For example, BBC, Progressive and Motorola Solutions are using Azure Neural TTS to develop conversational interfaces for their voice assistants in English speaking locales. Swisscom and Poste Italiane are adopting neural voices in French, German and Italian to interact with their customers in the European market. Hongdandan, a non-profit organization, is adopting neural voices in Chinese to make their online library audible for the blind people in China.
In this blog, we introduce our latest innovation in the Neural TTS technology that helps to improve the pronunciation accuracy significantly: Unified Neural Text Analyzer.
What is text analyzer?
Neural TTS converts plain text into wave form via three modules: neural text analyzer, neural acoustic model and neural vocoder. Text analyzer converts plain text to pronunciations, acoustic model converts pronunciations to acoustic features and finally vocoder generates waveforms. Text analyzer is the first link of the entire TTS system with results directly affecting the acoustic model and vocoder. The correct pronunciation of a word or phrase is the basic expectation in TTS, which delivers the right information to use but it’s not always easy. For example, “live” should be read different in “We live in a mobile world” and “TV Apps and live streaming offerings from The Weather Network” depending on context. If TTS reads them incorrectly, the intelligibility and naturalness of the content will be significantly influenced. Thus, text analyzer is important to TTS.
Recent updates on Neural TTS include a major innovation to the text analyzer, called “UniTA” (Unified Neural Text Analyzer). UniTA is a unified text analyzer model, which seamlessly simplifies text analyzer workflow and reduces time latency in the runtime server. It adopts a multitask learning approach, jointly training all ambiguity models to solve context ambiguity and generate correct pronunciation and as a result reduces over 50% of pronunciation errors.
What are the challenges?
Generally, different natural languages have different linguistic grammar. In TTS, text analyzer needs to follow the same grammar of languages in order to generate correct pronunciations, which contains but isn’t limited to the following required grammar categories:
Word Segmentation is the process of dividing the written text into meaningful units, such as words. In English and many other languages using some form of the Latin alphabet, the space is a good approximation of a word divider. On the other hand, in languages such as Chinese or Japanese, there is no spacing in sentences. Different word segmentation results may cause different meanings and pronunciations.
Part-of-Speech Tagging is the process of marking up a word in a text as corresponding to a particular part of speech (such as noun, verb, adj, adv and so on), based on both its definition and its context.
Morphology is the progress of classifying words according to shared inflectional categories such as person (first, second, third), number (singular vs. plural), gender (masculine, feminine, neuter) and case (nominative, oblique, genitive) with a given lexeme.
Text Normalization is the process of transforming digits or symbols to their standard format for disambiguation, for example: “$200″ would be normalized as “two hundred dollars”, “200M” would be normalized as “two hundred meters” or “two hundred million”.
Similar to Text Normalization, Abbreviation Expansion is the process of transforming non-standard words to their standard format for disambiguation, for example: “VI” would be normalized as “six”, “St” would be normalized as “Saint” or “street”.
Polyphone Disambiguation is the process of marking up polyphone word (heteronym word, which has one spelling but has more than one pronunciation and meaning) to its correct pronunciation based on its context.
Category
Example
Word Segmentation
[English] Nice to meet u:) –> Nice / to / meet / u / :)
[Noun, | l ai v s |] Many people have lost their lives since the cyclone because aid has not been able to be distributed.
[Verb, | l I v s |]
I also discovered the very angry raccoon that lives near my porch.
Morphology
[Singular]
1km –> one kilometer
[Plural]
5km –> five kilometers
Text Normalization
[Fraction, nine out of ten]
The O.S. Speed T1202 ups the ante for race-winning performance, resulting in a power plant that will dominate 9/10 scale competition.
[Date, September tenth]
1st episode will air 9/10 with never before seen video of her birth!
Abbreviation Expansion
[Street]
Oh man, biking from 24th St BART to the 29th St bikeshare station, that will be sweet.
[Saint]
We continue to ask anyone who was in the wider area near St Heliers School between 7.30am and 9am and witnessed any suspicious activity to contact police
Polyphone Disambiguation
[p r ih – z eh 1 n t]
The prices will present the estimated discount utilizing the drug discount card.
[p r eh 1 – z ax n t]
But our present situation is not a natural one.
Most pronunciations are affected by these categories based on syntactic or semantic context, and these categories are all challenging disambiguation problems. The traditional TTS approach is a pipeline-based module called “text analyzer” with a series of models aimed at solving grammar disambiguation problems, which causes some of the following issues:
Complex model. Redundant models are built and optimized separately but implemented together in the traditional text analyzer, which causes pipeline long and complicated.
Error propagation. Accumulated errors caused by the models isolated would affect the final results.
High latency. Models run one by one in the traditional text analyzer which is pipeline-based. Time cost is high in the runtime server.
Compared to the traditional pipeline-based text analyzers, our Neural TTS proposes a Unified Neural Text Analyzer model (UniTA) to improve TTS pronunciation.
It builds a unified text analyzer model, which greatly simplifies the text analyzer workflow and reduces time latency in the runtime server.
It adopts a multitask learning approach, jointly training all ambiguity models to solve context ambiguity and generate the correct pronunciations, reducing pronunciation errors by over 50%.
How does UniTA improve pronunciations?
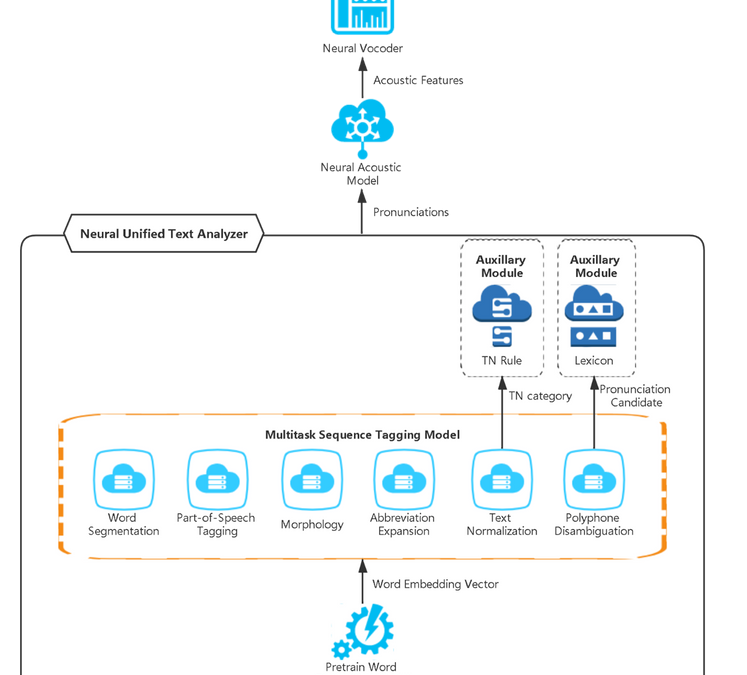
Firstly, UniTA converts the input text to word embedding vectors through a pre-trained model. Word embedding is a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from vocabulary are mapped to vectors of real numbers. Conceptually, it involves a mathematical embedding from a space with many dimensions per word to a continuous vector space with a much lower dimension. Pre-training models like XYZ-Code have demonstrated unprecedented effectiveness for learning universal language representations based on unlabeled corpus with the method achieving great success in many tasks like language understanding and language generation.
Secondly, a sequence tagging fine-tune strategy is adopted in the UniTA model. UniTA is designed as a typical word classification task, in which
Word Segmentation predicts word delimiter as word boundary or not.
Part-of-Speech(POS) predicts “noun”, “verb”, “adj” and so on to classify word part-of-speech.
Morphology predicts “singular”, “plural”, “masculine”, “feminine”, “neuter” and so on to classify word number, gender and case.
Text Normalization(TN) predicts candidate digits to “cardinal”, “date”, “time”, “stock” or other TN categories, and then an auxiliary component “TN Rule” helps convert digits to word form based on predicted category.
Abbreviation Expansion predicts candidate abbreviation word to its expanded form.
Polyphone disambiguation predicts polyphone words’ pronunciation. An auxiliary component, “Lexicon” is used here for achieving non-polyphone words’ pronunciations.
Different from the traditional text analyzer training models , UniTA adopts a multitask learning approach to jointly train all categories together including word segmentation, part-of-speech tagging, morphology, abbreviation expansion, text normalization and polyphone disambiguation. The multitask learning approach shares hidden layers’ information and jointly trains across different tasks, which has achieved state-of-art achievements on many NLP tasks. In UniTA, hidden information is also shared in models when training.
For example, the sentence “St. John had a 10-3 run to build its lead to 78-64 with 4:44 left.” in the training corpus is annotated as showed in the table below. “–” means there is no related tag in the category. In the word segmentation column, the phrase “10-3” is segmented as “10”, “-” and “3”; in the morphology column, the word “had” is annotated as “past tense”; in the text normalization column, “10-3” belongs to interpreting word “to” instead of “-“ while “4:44” belongs to the pattern using time format; In the abbreviation column, word “St.” is expanded as “Saint” rather than “Street”; and in the polyphone disambiguation column, the word “lead” is pronounced as [l i: d]. Actually, the word “lead” has two pronunciations, it is pronounced as [l i: d] when its POS is noun while pronounced as [l e d] when its POS is verb. This means the POS results and Polyphone results can share the inner information. In this way, multitask model improves UniTA accuracy.
Word
Word Segmentation
Part-of-Speech
Morphology
Text Normalization
Abbreviation
Polyphone disambiguation
St.
—
Noun
—
—
Saint
—
John
—
Noun
—
—
—
—
had
—
Verb
Past tense
—
—
—
a
—
Det
—
—
—
—
10-3
10 / – / 3
Num
—
numbers are predicted as “ten to three”
—
—
run
—
Noun
Singular
—
—
—
to
—
Particle
—
—
—
—
build
—
Verb
—
—
—
—
its
—
Det
—
—
—
—
lead
—
Noun
Singular
—
—
l i: d
to
—
Particle
—
—
—
—
78-64
78 / – / 64
Num
—
numbers are predicted as “seventy-eight to sixty-four”
—
—
with
—
Prep
—
—
—
—
4:44
4 / : / 44
Num
—
numbers are predicted as time format
—
—
left
—
Verb
Past participle
—
—
—
.
—
Symbol
—
—
—
—
UniTA model predicts categories’ results together in the neural TTS runtime service. The same as training, UniTA converts the plain texts to word embeddings and then the multitask sequence tagging model predicts all the categories’ results. Some auxiliary modules are embedded after fine-tuning categories to further improve pronunciations. Finally, the pronunciation results are generated from UniTA.
Here is the figure of the UniTA model structure in Neural TTS:
UniTA model diagram
Pronunciation accuracy improved with UniTA
Compared with the traditional TTS text analyzer, UniTA reduces over 50% of pronunciation errors in improving pronunciation accuracy. It is already used many neural voice languages such as English (United States), English (United Kingdom), Chinese (Mandarin, simplified), Russian (Russia), German (Germany), Japanese (Japan), Korean (Korea), Polish (Poland) and Finnish (Finland). Due to varying types of grammar in language, not all categories are suitable for every language. For example, Chinese and Japanese heavily depend on word segmentation and polyphone while these languages don’t need morphology or abbreviation expansion.
Here are some samples of the pronunciation improvement using UniTA.
Category
Language
Input text
(target word bolded)
Previous pronunciation
Current pronunciation
Word Segmentation
Chinese (Mandarin, simplified)
太子与三殿下行过礼后坐了片刻就离开了。
“三殿 / 下行 / 过礼”
“三殿下 / 行过礼”
Word Segmentation
Chinese (Mandarin, simplified)
叶奎最终还是在剧痛下泄了气
“剧痛 / 下泄了气”
“剧痛下 / 泄了气”
Word Segmentation
German (Germany)
kulturform
kult+urform
kultur+form
Word Segmentation
Korean (Korea)
해외감염병
h̬ɛwɛg̥mjʌmbjʌŋ
h̬ɛwɛg̥mjʌmpjʌŋ
Morphology – case ambiguity
Russian (Russia)
Количество ударов по воротам (15 против 7)также говорит о преимуществе чемпионов мира
Семь
Семи
Abbreviation Expansion
English (United States)
Joined TX Army National Guard in 1979.
T.X.
Texas
Text Normalization
English (United States)
The Downtown Cabaret Theatre’s Main Stage Theatre division concludes its 2010/11 season with the Tony Award winning musical, in the heights by Lin-Manuel Miranda.
November 2010
2010 to 2011
Polyphone disambiguation
Chinese (Mandarin, simplified)
卓文君听琴后,理解了琴曲的含意,不由脸红耳热,心驰神往。
qu1
qu3
Polyphone disambiguation
English (United States)
I received a copy early in November, and read and contemplated it’s provisions with great satisfaction.
Polyphone disambiguation
Japanese (Japan)
パッケージには、富士屋ホテルが発刊した「We Japanese」内の説明用の挿絵を採用。
うち
(w u – ch i)
ない
(n a – y i)
Hear how the Cortana voice pronounces each word accurately with UniTA.
Get started
With these updates, we’re excited to continue to power accurate, natural and intuitive voice experiences for customers world-wide. Azure Text-to-Speech service provides more than 200 voices in over 50 languages for developers all over the world.
This article is contributed. See the original author and article here.
Logic Apps Preview enables hosting Logic apps runtime on top of App Service infrastructure and as a result inherits many platform capabilities that App Service offers. In this blog we are going to explore some of the network capabilities that you can leverage to secure your workflows running in Logic Apps preview.
Networking overview of Logic Apps preview
The azure storage that is configured in the default create experience will have a public endpoint that the Logic Apps runtime will use for storing state of your workflows.
The managed API service (azure connectors) is a separate service hosted in azure and is shared by multiple customers. The Logic Apps runtime uses a public endpoint for accessing the API connector service.
Securing Inbound Traffic Using Private Endpoints
See here for instructions for adding a private endpoint to your Logic App preview. When you add a private endpoint:
The data-plane endpoint will resolve to the private IP of the private link and all public inbound traffic to your Logic Apps data plane endpoint will be disabled.
Request triggers and webhook triggers will only be accessible from within your vNET.
Azure managed API webhook triggers and actions will not work since they need a public endpoint for invocations.
The monitoring view will not have to access to inputs and outputs from actions and triggers if accessed from outside of your vNET.
Deployment from VSCode or CLI will only work from within the vNET. You can leverage deployment center to link your app to a GitHub repo and have the azure infrastructure build and deploy your code. In order for GitHub integration to work the setting WEBSITE_RUN_FROM_PACKAGE should be removed or set to 0.
Enabling private link will not affect the outbound traffic and they will still flow through app service infrastructure.
An alternative configuration
You can setup an application gateway to route all inbound traffic to your app by enabling service endpoint and adding a custom domain name for your app to point to the application gateway.
Securing Outbound Traffic Using vNET integration
To secure your outbound traffic from your web app, enable VNet Integration. By default, your app outbound traffic will only be affected by NSGs and UDRs if you are going to a private address (10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16).
To ensure that all your outbound traffic is affected by the NSGs and UDRs on your integration subnet, set the application setting WEBSITE_VNET_ROUTE_ALL to 1.
Set WEBSITE_DNS_SERVER to 168.63.129.16 to ensure your app uses private DNS zones in your vNET
Routing all outbound traffic through your own vNET allows you to subject all outbound traffic to NSGs, routes and firewalls. Note that an uninterrupted connection to storage is required for Logic Apps runtime to work and an uninterrupted connection to managed API service is needed for azure connectors to work.
Enabling vNET integration does not impact inbound traffic which will continue to use App Service shared endpoint. Securing inbound traffic can be done separately using private endpoints as we discussed above.
Securing Storage Account by using storage private endpoints.
Azure storage allows you to enable private endpoints on storage account and lock it down to be accessed only within your own vNET. We can leverage this capability by enabling private endpoint on the storage account used by your Logic Apps.
The setting AzureWebJobsStorage should point to the connection string of the storage account with private endpoints.
Different private endpoints should be created for each of table, queue and blob storage services
All outbound traffic should be routed through your vNET by setting the configuration WEBSITE_VNET_ROUTE_ALL to 1.
Set WEBSITE_DNS_SERVER to 168.63.129.16 to ensure your app uses private DNS zones in your vNET.
The workflow app should be deployed from Visual Studio Code and WEBSITE_RUN_FROM_PACKAGE config setting should be set to 1. Note that this will not work if you are also using private endpoint feature in which case you would want to leverage GitHub integration for deployment.
A separate storage account with public access is needed for deployment and setting WEBSITE_CONTENTAZUREFILECONNECTIONSTRING should be set to the connection string of that storage account
Troubleshooting
If your workflow app is not coming up, you can use the Kudu console of the app to check the name resolution and the connectivity. Pls note that you need to connect to kudu console from the vnet if you have enabled private endpoints on the app. Here are some good pointers on debugging connectivity issues.
For example, we can test the private queue endpoint dns resolution for “workflowState” as shown below.
And the connectivity to the private endpoint can be tested as shown below:
Further Reading
This article provides an in-depth detail on different networking options available on App Service platform and Logic Apps preview inherits most of these features given it is running on the App service infrastructure.
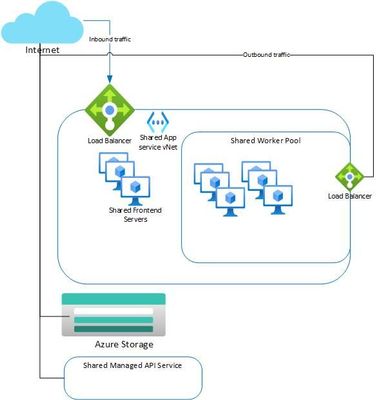
Sample App
Here is a sample deployment of Logic Apps preview integrated into a vNET.
This article is contributed. See the original author and article here.
I know this not a new feature, but this saved my proverbial behind earlier this week. I was cleaning out demo subscriptions and resource groups that I’m no longer using or that need to be reset for new demos. Well… It did not take long for me to pick one that I needed to keep and hit the “Delete resource group”.
And like any situation where you know you’ve screwed up. I knew the second I saw the notification.
Turns out this Resource Group was where stored all the recorded demos I regularly use…. #Facepalm
Blob soft delete is available for both new and existing general-purpose v2, general-purpose v1, and Blob storage accounts (standard and premium). But only for unmanaged disks, which are page blobs under the covers, but is not available for managed disks.
If you have not enabled this on storage accounts where you have important data…. DO IT NOW!!
1. In the Azure portal, navigate to your storage account, and in the left-side menu find the “Data Protection” option under the “Blob service” section.
2. Check the box for “Turn on soft delete for blob”, then specify how long soft-deleted blobs are to be retained by Azure Storage, and finally save your configuration.
That’s it! You are now protected. Anyway, I was still looking at how I was going to recover my data. I deleted the Resource Group!! Not just the storage account or just the blob container… started looking for documentation. And found the one I was looking for. Recover a deleted storage account.
I followed the steps that were simple, even when you’re restoring a storage account from a deleted resource group.
1. Create a Resource Group with the EXACT SAME NAME you just deleted. Once it’s created, navigate to the overview page for an existing storage account in the Azure portal. ANY existing storage account. And in the Support + troubleshooting section, select Recover deleted account.
2. From the dropdown, select the account to recover. If the storage account that you want to recover is not in the dropdown, then it cannot be recovered. Once you have selected the account, click on recover button.
Once the process is complete, your storage account will have been restored in its original spot. This really saved my bacon. I know it can potentially save yours.
Hopefully this can potentially save you some grief as well.
This article is contributed. See the original author and article here.
Hello, dear readers! Here is Hélder Pinto again, now writing about a topic that came out of my experience in one of my customers, who decided to stop using the Azure Diagnostics Extension in their virtual machine estate but had a massive challenge: how to remove the extension across 1000s of VMs and be sure that the diagnostics data was removed from Azure Storage and, by the way, save more than 10K euros per month? Let’s see how we did it.
Introduction
The Azure Diagnostics extension is an agent that collects monitoring data from the guest operating system of Azure virtual machines. With this extension, you can collect guest metrics and many types of logs and then send it to Azure Storage (default sink), Azure Monitor metrics or even to Azure Event Hubs (to be ingested by a third-party sink). No matter the additional sinks you may configure, the Azure Diagnostic extension always collects data into an Azure Storage account, using mostly Table storage*.
If, for some reason, you decide to stop collecting logs and metrics with the Azure Diagnostics extension, doing it could be as simple as uninstalling the extension from your VMs. But wait! You’re likely need to also get rid of all the data the agent collected over time. What if the Storage Accounts used by the extension are shared with other services? Will you still be able to identify those Storage Accounts after the extension is removed? The mission is not as simple as it seemed! :smiling_face_with_smiling_eyes: Let’s see below how we can do it effectively (and efficiently!).
Azure Diagnostics extension and data cleanup guide
If you need to remove the Azure Diagnostics extension at scale from your Azure virtual machine estate and finally clean the data that it generated, at least the largest one that lives in Azure Storage Tables, then you have here a complete procedure and scripts that will help you successfully achieve your goals.
The procedure is divided into three steps:
Assess which Azure Storage accounts are being used as a sink for the Diagnostics extension – carefully keep the generated CSV, because we will need this list for the last step.
Uninstall at scale the Diagnostics extension from your virtual machines.
Remove at scale the Azure Storage tables that were generated by the Diagnostics extension – we will use here the list extracted in the first step.
The user executing the scripts should have the Contributor role in the Azure subscriptions. If virtual machines have resource locks, then the user must have the Owner role.
Step 1 – Extract the list of Storage Accounts containing Azure Diagnostics data
This will generate a CSV file containing a list of all the Storage Accounts that are being used by the Azure Diagnostics extensions (see sample content below). Save this file, as we will need it for the last step.
CSV output containing the Storage Accounts use by the Azure Diagnostics extension
The magic behind this script is an Azure Resource Graph (I LOOOVE this service) query that quickly returns what you need:
resources
| where type =~ 'microsoft.compute/virtualmachines/extensions' and tostring(properties.type) in ('LinuxDiagnostic', 'IaaSDiagnostics')
| extend storageAccountName = iif(isempty(tostring(properties.settings.StorageAccount)),tostring(properties.settings.storageAccount),tostring(properties.settings.StorageAccount))
| project id, storageAccountName
| join kind=inner (
resources
| where type =~ 'microsoft.storage/storageAccounts'
| project storageAccountName = name, resourceGroup, subscriptionId
) on storageAccountName
| summarize count() by storageAccountName, resourceGroup, subscriptionId
Step 2 – Uninstall at scale the Diagnostics extension from virtual machines
Deallocated virtual machines – it will start them, remove the extension, and shut them down again (only VMs with the extension will be started).
Virtual machines that have a resource lock – it will remove the lock, remove the extension, and re-add the exact same lock – this requires you to have the Owner role for those virtual machines.
Target a specific resource group or subscription.
Make a dry run of the process with the Simulate switch.
.Uninstall-VmDiagnosticsExtensionAtScale.ps1 -RemoveLocks -StartVMs -Simulate – this will simulate an execution, starting deallocated VMs and removing resource locks before uninstalling the extension (of course, VMs won’t be started nor locks removed)
.Uninstall-VmDiagnosticsExtensionAtScale.ps1 -TargetSubscriptionId aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee -StartVMs – this will uninstall the extension only for the aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee subscription, starting deallocated VMs if needed.
Sample output of the script that removes the extensions at scale while dealing with locks and stopped VMs
The script will on-the-fly get the list of VMs to uninstall the extension from and will complete quickly, as the uninstallation is run asynchronously. At the end, you will get a CSV file containing the results of each uninstallation try, e.g., whether the VM was running or not, it had resource locks, or the extension was uninstalled. You must give at least 30 minutes for the process to finish. After this period, you can run the following query in Resource Graph Explorer, to check how successful the process was:
resources
| where type =~ 'microsoft.compute/virtualmachines/extensions' and tostring(properties.type) in ('LinuxDiagnostic', 'IaaSDiagnostics')
| project id, name
| extend vmId = substring(id, 0, indexof(id, '/extensions/'))
| join kind=inner (
resources
| where type =~ 'microsoft.compute/virtualmachines'
| project vmId = id, vmName = name, resourceGroup, subscriptionId, powerState = tostring(properties.extended.instanceView.powerState.code)
) on vmId
| project-away vmId, vmId1
| order by id asc
And here a sample output of the CSV file generated by this script:
Sample CSV output of the script that removes the Diagnostics extension, with the details about the process
If, for some reason, there is some extension that does not remove successfully, refer to the troubleshooting documentation. Nevertheless, you can proceed with no fear to the final step – removing Azure Storage Tables. Those zombie Diagnostics extensions will recreate and continue writing into the Storage tables, but at least you’ll have reduced your problem to a fraction of the dimension it had before. After fixing the extension issues, you can repeat steps 2 and 3.
Step 3 – Remove the Azure Storage Tables used by the Diagnostics extension
In this final step, you’ll use the CSV generated in step 1 and order the removal of all the Azure Storage Tables that are fed by the Diagnostics extension. The Remove-VmDiagnosticsTables.ps1 script is very simple to use. If needed, you can target a specific subscription instead of the whole tenant.
.Remove-VmDiagnosticsTables.ps1 -StorageAccountsCsvPath <path to the storage account list CSV generated in step 1> [-Cloud <AzureCloud | AzureChinaCloud | AzureGermanCloud | AzureUSGovernment>] [-TargetSubscriptionId <subscription Id>]
Example of the PowerShell invocation of the script that removes the Diagnostics Tables from the Storage Accounts
The script removes only the Storage Tables used by the Azure Diagnostics extension, leaving untouched all the remaining data that exist in the Storage Account, such as blobs or other tables used by other applications.
In the next day, you’ll likely notice a drop in your Azure Storage Table costs. Happy cleanup!
* Metrics and logs stored in Azure Tables do not have a retention mechanism, therefore your data (and Storage costs) keep growing over time.
This article was originally posted by the FTC. See the original article here.
Today is National Data Privacy Day, when many organizations and government agencies, including the FTC, join together to raise awareness about privacy issues and to offer tips and information. As more and more of our devices are connected and share information about us, privacy is increasingly important.
There are things you can do to help protect your privacy and limit how you share your information with others. National Data Privacy Day is the perfect time to review some of those steps you can take:
Know what’s on your device. Do an inventory of all the applications that are on your devices. Consider deleting what you don’t use.
Check the privacy settings. It’s a good idea to check the privacy settings of apps, devices, and online accounts periodically. You could, for example, review privacy settings when you get a notice from a company telling you that their privacy policies have changed.
Make sure any software and applications are up to date. This includes your apps, web browsers, and operating systems. Set updates to happen automatically.
Check the security of your home router. Make sure you’re using a router that has WPA2 or WPA3 encryption to protect the information you share over your wireless network. Public Wi-Fi is not secure, so take precautions if you need to use a public Wi-Fi hotspot.
Check out the FTC’s resources on privacy and online security for more tips and information. You can also follow the conversation on social media by searching the hashtag #DataPrivacyDay.
If you own a business, you can find information on how to protect your customers’ and employees’ privacy in this blog series.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.



















Recent Comments