This article is contributed. See the original author and article here.
In last blog, I introduced how SSL/TLS connections are established and how to verify the whole handshake process in network packet file. However capturing network packet is not always supported or possible for certain scenarios. Here in this blog, I will introduce 5 handy tools that can test different phases of SSL/TLS connection so that you can narrow down the cause of SSL/TLS connection issue and locate root cause.
curl
Suitable scenarios: TLS version mismatch, no supported CipherSuite, network connection between client and server.
curl is an open source tool available on Windows 10, Linux and Unix OS. It is a tool designed to transfer data and supports many protocols. HTTPS is one of them. It can also used to test TLS connection.
curl -v https://pingrds.redis.cache.windows.net:6380 --tlsv1.2
* Rebuilt URL to: https://pingrds.redis.cache.windows.net:6380/
* Trying 13.75.94.86...
* TCP_NODELAY set
* Connected to pingrds.redis.cache.windows.net (13.75.94.86) port 6380 (#0)
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 1/3)
* schannel: checking server certificate revocation
* schannel: sending initial handshake data: sending 202 bytes...
* schannel: sent initial handshake data: sent 202 bytes
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: failed to receive handshake, need more data
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: encrypted data got 4096
* schannel: encrypted data buffer: offset 4096 length 4096
* schannel: received incomplete message, need more data
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: encrypted data got 1024
* schannel: encrypted data buffer: offset 5120 length 5120
* schannel: received incomplete message, need more data
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: encrypted data got 496
* schannel: encrypted data buffer: offset 5616 length 6144
* schannel: sending next handshake data: sending 3791 bytes...
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: encrypted data got 51
* schannel: encrypted data buffer: offset 51 length 6144
* schannel: SSL/TLS handshake complete
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 3/3)
* schannel: stored credential handle in session cache
Fail connection example due to either TLS version mismatch. Not supported ciphersuite returns similar error.
curl -v https://pingrds.redis.cache.windows.net:6380 --tlsv1.0
* Rebuilt URL to: https://pingrds.redis.cache.windows.net:6380/
* Trying 13.75.94.86...
* TCP_NODELAY set
* Connected to pingrds.redis.cache.windows.net (13.75.94.86) port 6380 (#0)
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 1/3)
* schannel: checking server certificate revocation
* schannel: sending initial handshake data: sending 144 bytes...
* schannel: sent initial handshake data: sent 144 bytes
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: failed to receive handshake, need more data
* schannel: SSL/TLS connection with pingrds.redis.cache.windows.net port 6380 (step 2/3)
* schannel: failed to receive handshake, SSL/TLS connection failed
* Closing connection 0
* schannel: shutting down SSL/TLS connection with pingrds.redis.cache.windows.net port 6380
* Send failure: Connection was reset
* schannel: failed to send close msg: Failed sending data to the peer (bytes written: -1)
* schannel: clear security context handle
curl: (35) schannel: failed to receive handshake, SSL/TLS connection failed
Failed due to network connectivity issue.
curl -v https://pingrds.redis.cache.windows.net:6380 --tlsv1.2
* Rebuilt URL to: https://pingrds.redis.cache.windows.net:6380/
* Trying 13.75.94.86...
* TCP_NODELAY set
* connect to 13.75.94.86 port 6380 failed: Timed out
* Failed to connect to pingrds.redis.cache.windows.net port 6380: Timed out
* Closing connection 0
curl: (7) Failed to connect to pingrds.redis.cache.windows.net port 6380: Timed out
openssl
Suitable scenarios: TLS version mismatch, no supported CipherSuite, network connection between client and server.
openSSL is an open source tool and its s_client acts as SSL client to test SSL connection with a remote server. This is helpful to isolate the cause of client.
4. Verify if remote server’s certificates are trusted.
Success connection example:
CONNECTED(000001A0)
depth=1 C = US, O = Microsoft Corporation, CN = Microsoft RSA TLS CA 02
verify error:num=20:unable to get local issuer certificate
verify return:1
depth=0 CN = *.blob.core.windows.net
verify return:1
---
Certificate chain
0 s:CN = *.blob.core.windows.net
i:C = US, O = Microsoft Corporation, CN = Microsoft RSA TLS CA 02
1 s:C = US, O = Microsoft Corporation, CN = Microsoft RSA TLS CA 02
i:C = IE, O = Baltimore, OU = CyberTrust, CN = Baltimore CyberTrust Root
---
Server certificate
-----BEGIN CERTIFICATE-----
MIINtDCCC5ygAwIBAgITfwAI6NfesKGuQGWPYQAAAAjo1zANBgkqhkiG9w0BAQsF
ADBPMQswCQYDVQQGEwJVUzEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9u
pK8hqxL0zc4NQLRTq9RNpdPwnNmGn5SZ4Nu5ktUgWokR97THzgs6a/ErHH2tigLF
jwkgB8UuV/hhu3vEa0jxstSBgbjQPgSNexAl7XwgawaucIF+wkRpPW2w0VTcDWtT
1bGtFCpewAo=
-----END CERTIFICATE-----
subject=CN = *.blob.core.windows.net
issuer=C = US, O = Microsoft Corporation, CN = Microsoft RSA TLS CA 02
---
No client certificate CA names sent
Peer signing digest: MD5-SHA1
Peer signature type: RSA
Server Temp Key: ECDH, P-256, 256 bits
---
SSL handshake has read 5399 bytes and written 293 bytes
Verification error: unable to get local issuer certificate
---
New, TLSv1.0, Cipher is ECDHE-RSA-AES256-SHA
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
SSL-Session:
Protocol : TLSv1.1
Cipher : ECDHE-RSA-AES256-SHA
Session-ID: B60B0000F51FFB7C9DDB4E58CD20DC20987C13CFD31386BE435D612CF5EFDBF9
Session-ID-ctx:
Master-Key: DA402F6E301B4E4981B7820CAF6E0AF3C633290E85E2998BFAB081788488D3807ABD3FF41FF48DA55DB56281C024C4F4
PSK identity: None
PSK identity hint: None
SRP username: None
Start Time: 1615557502
Timeout : 7200 (sec)
Verify return code: 20 (unable to get local issuer certificate)
Extended master secret: yes
Fail connection example due to TLS mismatch:
OpenSSL> s_client -host sdcstest.blob.core.windows.net -port 443 -tls1_3
CONNECTED(0000017C)
write:errno=10054
---
no peer certificate available
---
No client certificate CA names sent
---
SSL handshake has read 0 bytes and written 254 bytes
Verification: OK
---
New, (NONE), Cipher is (NONE)
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
Early data was not sent
Verify return code: 0 (ok)
---
error in s_client
Fail connection example due to network connectivity:
Suitable scenarios: TLS version mismatch, no supported CipherSuite.
This is a free online service performs a deep analysis of the configuration of any SSL web server on the public Internet. It can list all supported TLS versions and ciphers of a server. And auto detect if server works fine in different types of client, such as web browsers, mobile devices, etc.
Please note, this only works with public access website. For internal access website will need to run above curl or openssl from an internal environment. And it only supports domain name and does not work with IP address.
Web Browser:
Suitable scenarios: Verify if server certificate chain is trusted on client.
Web Browser can be used to verify if remote server’s certificate is trusted or not locally:
Access the url from web browser.
It does not matter if the page can be load or not. Before loading anything from the remote sever, web browser tried to establish SSL connection.
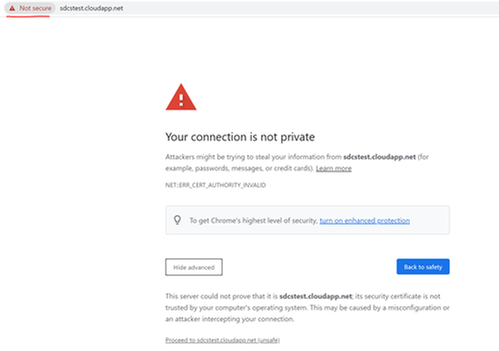
If you see below error returned, it means certificate is not trusted on current machine.
Certutil
Suitable scenarios: Verify if server certificate on client, verify client certificate on server.
Certutil is a tool available on windows. It is useful to verify a given certificate. For example verify server certificate from client end. If mutual authentication is implemented, this tool can also be used to verify client certificate on server.
The command auto verifies trusted certificate chain and certificate revocation list (CRL).
Between the four of them, there’s somewhere around 100 different configuration options, which can be configured into countless combinations; and if you want to make the most out of them, you’re also going to need to be somewhat familiar with SharePoint Search topics such as managed and crawled properties, refiners, result sources, etc…
Point is, these web parts are not meant for the masses and can be a challenge even for the most super of super users.
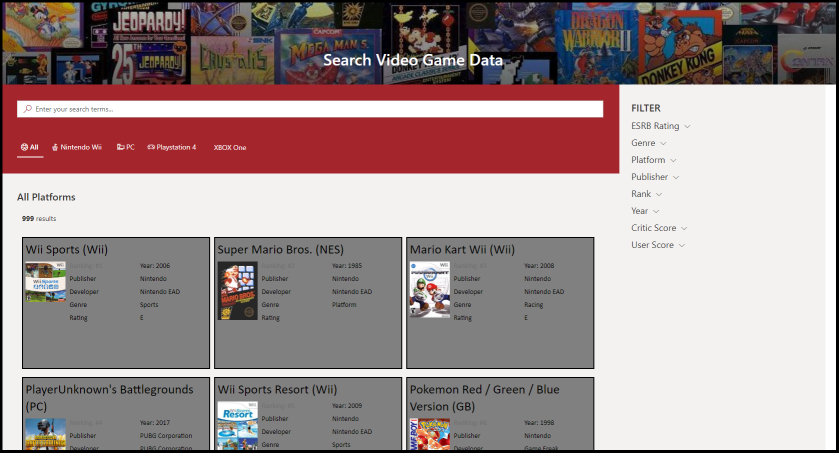
The aim of this post is to, hopefully, lessen that challenge a bit. And to do that, we’re going to be using these web parts to build a page for searching a SharePoint list of the top 999 video games (by # of units shipped).
We’re not going to be deep diving into every option or combination of setting. Instead, we’re going for the classic “Minimal Path to Awesome”…with a few detours throughout.
Getting the Web Parts
The latest version of the PnP Modern Search web parts can be found using this link.
For the purposes of this blog, we’re looking at v4.1.0, which can be found using this link (in case it’s no longer the latest).
Just scroll down to the bottom of the page and download the .SPPKG file.
Once you have those, you can follow along with the installation guide to get them in your tenant.
Setting up for the demo
If you’re interested in following along with the demo in your own environment, there’s a bit of behind-the-scenes work that was done to stage things.
I’ve included a PnP Site template and a README in the github repository for this blog to help get you up to speed.
Configuring the Search Box web part
In keeping with the spirit of our “Minimal Path to Awesome” approach, the Search Box web part will be the easiest to configure of the lot. We can just drop it on the page somewhere and be done.
That doesn’t mean, however, that it has to be that simple. Version 4 has introduced more advanced features than we’ll be making use of, but that doesn’t mean we can’t take a peek.
Panel 1 – Search box settings
The first configuration panel initially offers two settings.
The first setting will replace the default “Enter your search terms…” placeholder text with whatever you type here.
The second setting – Send the query to a new page – will be off by default (and will stay that way for this example). If you enable it, you’ll see some new options appear that allow you send the user’s query to a new page/tab.
This can be incredibly useful if you want to create “Search Results” page like what we’re currently doing, but also want to provide a search box on other pages. Using this we could, for example, include a Search box web part on the home page of our site and, when a user submits a query, the query is passed to the page we’re building, and search results are shown.
Panel 2 – Query Suggestions
It’s possible to provide users with some search suggestions (you know, the things that appear beneath what you’re typing in search engines like Bing or Google) to help speed them along their search journey.
As users search for a particular term or phrase and click on search results, SharePoint will (supposedly) make a correlation between the two. In our example, if a user searched for World of Warcraft and clicked on the result World of Warcraft: Legion six times, SharePoint would begin suggesting World of Warcraft: Legion as a potential query.
NOTE: I used the word supposedly earlier because I never saw this feature working in my example. I assume this is either because the search results we’re creating aren’t clickable, or that the Search suggestions are only curated when you’re using the built-in search boxes, such as the Microsoft Search bar.
Panel 3 – Available Connections
The last panel of options includes configurations that allow us to pull queries from other sources.
Again, we’re not going to be dealing with these on our MPA. However, referring to the example of having a search box on a home page sending queries to the page we’re currently building, we would want to select the “Query string” option here and specify our parameter name. Once configured, we could pass query information from one page and pull it in here.
Configuring the Search Verticals web part
Verticals allow users to limit their search results to a specific kind of result. If you’ve been around SharePoint long enough, you’ve no doubt seen the standard All, Files, People, Sites, etc… verticals that SharePoint shows when you search for stuff.
Well, the Search Verticals web part allows us to create our own verticals that enable our users to see results for specific platforms.
In terms of difficulty, the Search Verticals web part comes in second place in our example, although it’s probably the easiest to configure overall if you count the Search Box features we’re not making use of.
While the other three web parts in this package saw new features (and added complexity) with the latest version, this web part is actually became much easier to use. There’s only one configuration panel to deal with, so let’s take a look.
Panel 1 – Search verticals configuration
When you open the Search Verticals web part, you’ll be greated with a singular button that says Configure Verticals.
When clicked, you get the real deal…
We can add any number of verticals simply by giving them a name and setting an order. We can also make use of the standard Fabric icons if we wish (and we do!) and, if we choose, we can make verticals a link that opens a new page when clicked.
Since we want our users to stay on the same page, we’re not going to bother with hyperlinks, but we will go ahead and create verticals for the latest generation of platforms available in our dataset, as well as an “All” vertical.
Search Verticals Summary
That’s all there is to it, really. However, one important thing to keep in mind is that each vertical you choose to add will require a separate instance of the Search Results web part. For those that are familiar with previous versions of these web parts, this is a deparature from what we’re used to.
Configuring the Search Refiners web part
Once a user gets to searching, they may want to be able to filter the results by certain criteria. We can use the Search Filters web part to fulfil that demand.
Panel 1 – Available Connections
For refiners to show, they’ll need search results to refine. The “Available connections” settings will allow you select one or more Search Results web parts. If you haven’t already added one, there won’t be any options, so make sure you’ve added one first. Once you’ve got one, select it here.
Later, you’ll see that we end up with multiple Search Results web parts, so we’ll revisit this after that point to update it so our refiners respect that.
Panel 1 – Filter Settings
The other section has two different settings we can configure.
Clicking the edit button will, again, open a meme-worthy panel. Unlike the last panel, though, this new panel is far more involved.
Most of the settings are, I think, self explanatory and you can see the settings used for the demo in the above screenshot.
However, it’s important to note that the values you use in the “Filter field” column MUST map to a managed property that has been marked as Refinable. In our case, we’ve already gone into our search schema and mapped the columns we wanted to filter by to the provided Refinable managed properties.
NOTE: If you’ve applied the PnP template referenced earlier, these settings will have already been mapped for you.
Panel 2 – Available Layouts
We have three pre-canned layouts available to us, as well as a Custom option which you can use to present your filters in any way you can imagine.
The Vertical and Horizontal options are self-descriptive, while the Panel option will cause a panel to flyout from the right (like how the web part properties do).
Since our Filter web part is in a vertical column, we’ll just stick with that option.
Configuring the Search Results web part.
The Search Results web part is, as the name implies, the component we use to show search results for the things users are searching for. It’s also where things start getting little more involved.
Unlike the previous web parts, there are a lot of different settings, combinations, and customization potential in this web part. Since we’re focused on just getting a quick win, we’ll mostly be sticking to the basics.
Panel 1 – Available data sources
The first section we must deal with is choosing where we will pull search results from: SharePoint or Microsoft Search?
As was mentioned in the at the beginning of this blog, all our data is in SharePoint, so we’re just going to go with that. We could, of course, use Microsoft Search to get the data as well…but we’ll leave that for another time. Just note that if you decide to go forward with Microsoft Search, some of the configuration options will change based on that context.
Panel 1 – Layout slots
If you click the Customize button, you’ll be presented with another flyout panel with a bunch of default entries. There’s a brief description at the top that tries to explain what these are, but honestly didn’t make much sense to me in the beginning.
Search results are, behind the scenes, being rendered using Handlebars templates. Each one of these Slots will create a variable that can be referenced in a template and is tied back to a property returned in the search results.
Considering the above, there will be a property exposed in the Handlebars template called “Author” that is mapped to the “AuthorOWSUSER” managed property.
For those of us walking the minimalist path, this isn’t necessary. However, the search results shown in screenshots does make use of custom templates and does rely on some custom layout slots to tie into the managed properties associated with our list of video games. Below is a table of the mappings for those following along.
Slot name
Slot field
Developer
DeveloperOWSCHCS
Rating
ESRBRatingOWSCHCS
Genre
GenreOWSCHCS
IMGURL
imgurlOWSURLH
Platform
PlatformOWSCHCS
Publisher
PublisherNameOWSCHCS
Rank
RankOWSN
Year
YearOWSNMBR
Panel 1 – SharePoint Search
This section has a lot going on and is our first real chance to influence what search results are surfaced for the user.
Query Template
The first option is the Query template text box. By default, it will simply have {searchTerms} loaded into it, which acts as a token to represent whatever search query is being fed to the web part. In our case, that will be whatever the user has typed into the Search Box web part. You can enter your KQL query here, which can enable you to restrict search results to, say, a particular content type ID like so…
In this case, the content type ID being used is for a “Video Game Data” content type that is used for items in our list. So, by doing this, we’re limiting our search results to only those that match our content type.
This also gives the benefit of displaying default search results when the user enters the page, which is pretty useful in our example.
Result source ID
Immediately below that is the Result source ID field, which allows you select a SharePoint Search Result Source. By default, it will be set to LocalSharePointResults. If you’re using the method above, you can leave it there. The other option is to create your own custom Search Results type to limit results to our content type and supply the GUID for that here. The end result is the same, ultimately.
Selected Properties
Next up is the Selected Properties dropdown. The web part will have several properties selected by default, and if you’re just wanting to leverage the default layout options, you can leave this alone as well. If, however, you want to display different properties on your search results you can (de)select as many options as you need. You won’t be able to make use of any property you haven’t included here though, so bear that in mind.
Our search results don’t need any of the default options. Instead, you can just copy & paste the below string into the text box to get going.
Each one of those values points to a managed property that was created when our site columns were provisioned and allows us to show that data on our result cards.
Sort order
I think this one is fairly self explanatory. You select a managed property (or properties), things get sorted as you specify.
The only thing to keep in mind here is that the property you select must be marked as being sortable in the Search schema, which they won’t be by default and is why we’re referencing RefinableInt00 in the screenshot above, which has been mapped to the Rank column in our list.
Refinement filters
You can add additional filters to search results here. This is another way, like the Query text example above, to limit what results are returned.
We could totally add our ContentTypeId:0x01004527A5975C6A534DAE7EBFD57E41A633* filter here, if we chose, instead of the Query text box above.
The biggest difference would be that we wouldn’t see any search results until the user actually searched for something.
The other options…
There are five other options available in this section which are somewhat self explantory. The only exception to the rule might be the Enable query rules options, which is more than we’re going to get into here (and honestly not something I’m familiar with).
Panel 1 – Paging options
This section, as the name implies, allows you to configure paging options. They’re all straight forward and the only one we changed for the demo was the Number of items per page, which we set to 9 – the idea being that we wanted to show three cards per row (which left a straggler if we lef it at the default 10).
Panel 2 – Available layouts
This panel is more straight forward that the last. Select a layout and configure any common or layout specific options you want.
The complexity will come in when you want to customize the visual appearance of the search results. Many of the non-custom layouts have configuration options that allow you to influence the appearance, but all of them will require some familiarity with Handlebars to get the most out of them.
If you’re just using these web parts to surface standard SharePoint content, such as Pages or Documents, the non-custom layouts should suit your needs perfectly.
For the hardcore, you can also go full custom and get as creative as you’d like. We’re using the custom layout in our Search Results web parts, the source for which can be found on github.
NOTE: For the custom layout to function, you will need to ensure that you’ve defined the custom Slots referenced earlier in the blog.
Panel 3 – Available Connections
The last panel of options allows us to connect the other web parts we have on our page which, in turn, allows them to influence our search results.
The first option is whether to Use input query text, which is Off by default. This setting basically controls whether we want to allow search queries.
Leaving it off might seem odd, but if we didn’t want users to search via text and instead use verticals, refiners, or just browse through result pages of the query we specified back on the first panel’s Query template, that’s how we’d do it.
However, we definitely want to flip that on, otherwise our Search Box web part will be about as useful as a glass nail. Once on, you can select Dynamic Value and select the PnP – Search Box option.
We’ll also want to go ahead and connect our filters web part, which is as simple as toggling the switch and selecting the only item in the dropdown.
Lastly, we’ll want to connect to our verticals web part, which is only slightly more complicated than the refiners. As you’ll see, we have a second dropdown that is labeled Display data only when the following vertical is selected.
To start with, just select the All option. Once that’s done, in order to support all of our verticals, we’ll need to actually duplicate the web part we just configured for each additional vertical (4 times, in our example) and update each one to show during a different vertical. It’s a bit heavy handed for our example, but extremely useful if you intend to display different layouts for different verticals.
Once you’ve duplicated your Search Results web part, be sure to update the Available Connections setting in your Search Refiners web part to include these additions.
Conclusion
If you’ve followed along with everything, you should have a page that looks something like the below…
These web parts are amazingly cool, extremely powerful, and can be leveraged to create a lot of awesome experiences for our users.
It’s also one of the most complicated web parts out there. While this blog post was (mostly) focused on that “minimal path to awesome”, it’s still REALLY long, which speaks to some of that complexity. However, hopefully this has helped make it more accessible to get started.
At a minimum, you’ve at least learned that Wii Sports is the most shipped game of all time…so you’ve got that going for you, which is nice.
This article is contributed. See the original author and article here.
Bring state-of-the-art search capabilities to your custom applications in content management systems with Azure Cognitive Search. Tour the latest enhancements with Semantic Search to surface relevant answers to your search queries.
Azure Cognitive Search is a PaaS solution that allows you to integrate sophisticated search capabilities into your applications. It helps you quickly ingest, enrich, and explore structured and unstructured data, and is available to everyone.
Azure and Bing teams have worked together to bring learned ranking models to Azure for you to leverage in your custom search solutions. Now search can extract and index information from any format, applying machine learning techniques to understand latent structure in all data. Distinguished engineer, Pablo Castro, joins host Jeremy Chapman, to walk you through the improvements and show you how the intelligence works behind these powerful capabilities.
Semantic Search—Relevance, Captions, and Answers:
Create similar experiences to web search engines, but for your own application and on your own data.
Search matches words, but also understands the context of the words relative to the words surrounding them.
Offers a significant improvement in relevant results; all you have to do is enable it.
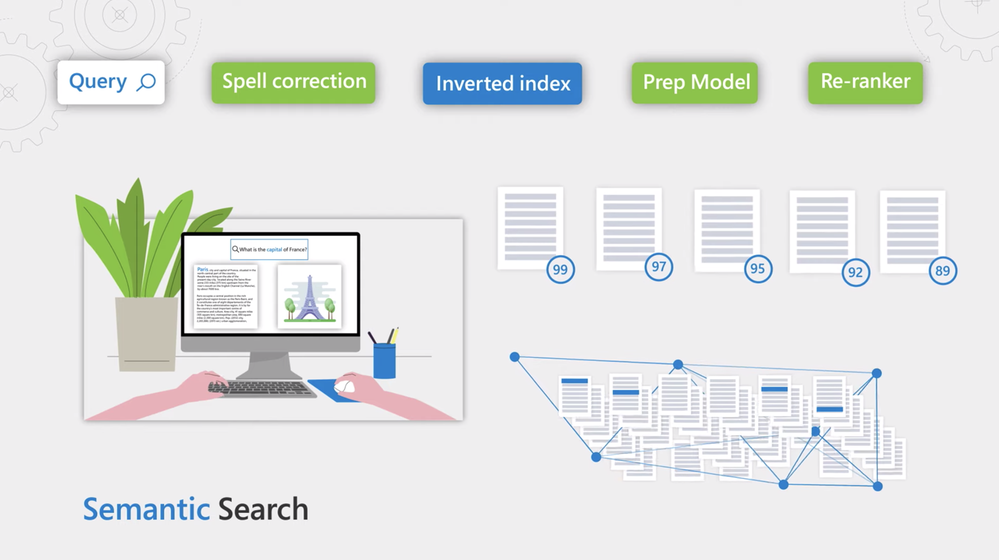
Spell correction, Inverted index, Prep model, and Re-ranker:
Keyword searches return exact matches and ranking is often only based on the rate of relevant frequencies of the words.
Capture nuances in the language for a more sophisticated machine learning model that’s course document relevant in the context of the query.
We are Microsoft’s official video series for IT. You can watch and share valuable content and demos of current and upcoming tech from the people who build it at Microsoft.
– Up next on this special edition of Microsoft Mechanics, we’re joined by distinguished engineer Pablo Castro, to learn how you can bring state-of-the-art search capabilities to your custom applications in content management systems, including the latest enhancements with semantic search for ranking top search results and answers, that uses machine reading and comprehension to surface answers to your search queries. So, Pablo it’s a pleasure to have you on Microsoft Mechanics.
– Thanks Jeremy, happy to be here.
– And it’s a real privilege to have you on the show as one of the leaders for intelligent search at Microsoft and congrats on today’s announcements. But before we get into this though, for those of you who are new to Azure Cognitive Search, it’s a PaaS solution in Azure that allows you to integrate sophisticated search capabilities into your applications. As an example, large industrial manufacturer Howden use Azure Cognitive Search to be able to quickly drill into the details of customer equipment requests, so they can respond with accurate bids. Now, the Azure Cognitive Search platform helps you to quickly ingest, enrich and explore structured and unstructured data. And you can integrate Azure Cognitive Search into your customer-facing mobile apps or e-commerce sites and line of business apps. So Pablo, Azure Cognitive Search really brings together some of the best work for Microsoft across search and AI, and really makes it available for everyone.
– It really does. We’ve been lucky to be able to harness a lot of the amazing work of Microsoft research. We also combined it with our extensive partnership with the Bing team. We’ve developed a lot of advancements for Azure Cognitive Search. Everything starts with data ingestion, so you can bring data from any source. You can automatically pull data in from an Azure data source or you can push any data you want to the search index using the push API. Of course, this content is not uniform, it exists in different formats and it’s anything from records, to long text, to even pictures. So we taught search to extract and index information from any format, applying machine learning techniques to understand latent structure in all data. For example, we extract key phrases, tag images, the tech language, locations and organization names. And you can also bring your custom skills and models. This combination of cognitive search and with cognitive services, in fact makes search able to understand content of all nature.
– Right, and I remember a few years back, we actually showed a great example for this. So we took the John F. Kennedy files, really comprised of decades old, handwritten notes and photos and typed documents. Then with Azure Cognitive Search we could understand the data and even surface new insights that had never been seen before.
– Yeah, the sophistication of data ingestion, the smarts to understand and index content along with keyword search, it’s something we’ve had for a while. And we’ve seen many of you take advantage of this for lots of interesting scenarios. Today, we’re announcing the next step on this journey with the new semantic search capabilities that includes semantic relevance, captions and answers in preview today. I have this demo application that’s fronting a cognitive search index with a dataset that’s often used for evaluation purposes called MS Marco. Let’s search for what’s the capital of France. You can see that the results match the keywords in our search, but it looks like the ambiguity of the word capital in particular, caused top results to be a bit all over the place. We see capital punishment, capital gains, the capital of Kazakhstan, removals in France. Now, I’ll enable something brand new, semantic search. And this, I’ll auto-enable spelling as well. With semantic search, they Azure and Bing teams have worked together to bring state-of-the art learned ranking models to Azure for you to leverage in your custom search solutions. Now, if I go back to the page, you’ll see the results side-by-side, keyword search on the left, semantic search on the right. You can see how on point the new results are, they’re about France and they discuss it’s capital, with links to Britannica and World Atlas. Note, that this huge improvement in quality only required me to enable this option. Now, let’s take this to the next level with semantic captions and answers. Let me go back here into settings and enable both of these features. Not only do we see relevant results, but we can see captions under each result that are meaningful in the context of our query. We can also see an actual answer proposed by cognitive search. So now, you can create the same kind of experiences that web search engines offer but for your own application and on your own data.
– And what I love about this is that the answer is actually presented directly in the context of the search. And you don’t have to click on an additional link then, to find your answer. So what does it take then to add something like this, semantic search, into our apps?
– Well, it’s not that hard to get it running. Let’s first walk through how to ingest and enrich data in cognitive search, and then we can dive into the new semantic search. First thing to do, is to create a cognitive search service. I already have one created and I’m here in the portal with it open. I’m going to use import data to start this process. You can see, we support many Azure stores. In this case, I’m going to point to an existing blob storage account with unstructured data in it. In the next step I can enable one or more cognitive services or custom models to enrich the data I’m ingesting, so I’ll add enrichments. For example, I can enable optical character recognition, edit extraction, computer vision and more. Finally, I have the chance to customize my index definition and to set up indexer options. At this point, I’m done. And I have an ingestion process that will run automatically, detect changes, enrich data and push it into my index. I already created an index before, so we don’t have to wait for this process. Let’s go into this index and give it a quick try. I can search for say, France. And I can see the results coming back. Now in your application, you’ll typically use one of our client libraries or the HTTP API. Here, I’m in VS code and this is a typical HTTP request for the search API. Let me run it to see the results for the same search we did earlier. You can see we get the keyword search results. Now, I’ll just change the query type to semantic and reissue this query. You can see that now I’m getting the new, more relevant results, thanks to semantic relevance. That one line was all I needed, a few more tweaks will also enable captions and answers. And since these options don’t require re-indexing, you can easily try this on your existing applications as well.
– Right, and these all look like pretty simple API calls but behind the scenes at the service level, there’s a ton of complexity going on there.
– Right. We take care of the data science to give you state-of-the art search results without having to create your own ranking models from scratch. At the same time, we also take care of the infrastructure to run our ranking and machine learning models efficiently and fast.
– All of this, what you shown, would have taken a ton of effort if we were trying to build this ourselves, but what kind of improvements have you made to make all of this possible?
– So let’s start by explaining traditional keyword search. Here, you would match each word in a search query against an inverted index, which allows for fast retrieval of documents based on if they contain the words of search terms that you’re searching for. This returns documents that have those words. The problem with this is it only returns exact matches and ranking is often only based on the record relative frequencies of the words. Sometimes that’s what you want, such as when searching for part numbers like in the example you gave earlier with Howden, when you know precisely what to look for. However, when searching through content written by people, you want to capture the nuance in the language. So we added a few key components to improve search precision and recall. First, we added a step, so as a search query comes in, it passes through a new spelling correction service to improve document recall. Then we use the existing inverted index to retrieve all candidates, and we pick the top 50 candidates using a simple scoring approach that’s fast enough for scoring millions of documents quickly. We then added a new prep step for these search results by running another model that picks part of the document that matter the most based on the query. From there, the results are re-ranked via a much, much more sophisticated machine learning model that’s scores document relevance in the context of the query.
– And still there’s a lot more in terms of how the intelligence works. And in the examples that you demonstrated here, you showed how the semantic search wasn’t just matching words but also understanding the context of the words relative to the words surrounding them. So what makes all of this possible?
– This is where we take advantage of recent advancements in natural language processing. Let’s put this into context in terms of what it means for ranking and then for answers. First thing we need to do is to improve recall to find all candidate documents. So in our example search, a key concept was the word capital. The search engine needs to understand that the word capital could be related to states or provinces, money, finances or a number of other meanings. So to go beyond keyword matching, we use vector representations where we map words to high-dimensional vector space. These representations are learned, such as the words that represent similar concepts are close together in sort of a same bubble of meaning. These represent conceptual similarity, even if those words have no lexical or spelling similarity to the word capital.
– Okay, so how does it find then, the relationship between the words?
– So now that we have solved for recall, we need to solve for precision in results. Here Transformers, which is a novel neural network architecture, enabled us to think about semantic similarity, not just of individual words but of sentences and paragraphs. This uses an attention mechanism to understand long-range dependencies in terms, in ways that were impractical before. Particularly, for models this large. Our implementation starts with the Microsoft developed Turing family of models that have billions of parameters. We then go through a domain specialization process where we train models to predict relevance using data from Bing. For example, when I search for what is the capital of France, reading the whole phrase it’s able to identify the dependency between capital and France as a country, that puts capital in context and quickly return results with high confidence, in this case for Paris. And separately, we also build models oriented towards summarization as well as machine reading and comprehension. For captions, we apply a model that can extract the most relevant text passage from a document in the context of a given query. And for answers, we use a machine reading and comprehension model that identifies possible answers from documents and when it reaches a high enough confidence level, it’ll propose an answer.
– And the nice thing here is that Microsoft takes care of all the infrastructure to run these models. But as you say, they’re pretty large, so what are you doing then to operationalize these models into production to avoid slow search results?
– Yeah, you’re right. I mean, this models can be compute and memory hungry and expensive to run. So we have to right-size them and tune them for performance, all while minimizing any loss in model quality. We distill and retrain the models to lower the parameter count. So they can run fast enough to meet the latency requirements of a search engine. And then to operationalize these, we deploy these model on GPUs in Azure and when a search query comes in, we can parallelize over multiple GPUs to speed up scoring operations to rank search results.
– Great, so all of this then offers a great foundation then to achieve both high precision, as well as relevant search results. Now, there’s a lot behind just those few lines of code that light up these powerful capabilities, really as you build out your custom apps. But how can everyone learn more and then really start using this?
– You can try it out yourself. You can sign up for the public review of semantic search today at aka.ms/SemanticPreview. And we have more guidance on how to get started with Azure Cognitive Search at aka.ms/SemanticGetStarted.
– Thanks Pablo. And of course, for the latest updates across Microsoft, keep watching and streaming Microsoft Mechanics. Subscribe if you haven’t already yet and we’ll see you next time.
This article is contributed. See the original author and article here.
Sooooo many candles. Inhale, deep breath… SharePoint – make your wish a good one.
Time flies when you’re powering productivity. And the young feels flow with the vibrancy of a community energizing you month-over-month, year-over-year, decade-after-decade.
Soak it all in below: this multi-media blog brings a special sizzle video to celebrate all that SharePoint is at 20, a unique episode of The Intrazone interviewing several of SharePoint’s original engineers, and some fun singing and singalong gems for the community at large. Quite a tech journey – none of which would be possible with the collective people that nurtured, critiqued, used, pushed and pulled SharePoint in and beyond the enterprise over these last 20 years.
VisitSharePoint’s 20th Birthday Party! page. Join in the fun all day (Saturday, March 27th, 2021), with 2D and 3D options. Stories, videos, and prizes await across all time zones –Jeff Teper (CVP Teams, SharePoint, and OneDrive engineering) kicking it all off at 9:00AM PDT – sharing his own stories, fun videos, and a catchy community singalong. What follows is a day designed for everyone – a day to celebrate amazing people and technology across the community.
The Intrazone: “SharePoint: 20 years young”
Reminisce along with the “SharePoint: 20 years young” podcast episode of The Intrazone. You’ll hear from some of the people that built SharePoint and shaped it into what it is today. SharePoint’s own captain, Jeff Teper, takes us back to the days before SharePoint had a name: Project Tahoe. And then navigate the years with some of the earliest members of the engineering team as your audible historians: Lauren Antonoff who led program management in the early connections to Office, Rob Lefferts who helped define document management, Adam Harmetz who rooted much of its ECM foundation, Bjørn Olstad who joined Microsoft as part of the FAST acquisition and now leads our Microsoft Search efforts, and community leaders Adis Jugo and Spencer Harbar – the duo behind SharePoint’s 20th Birthday Party event and longtime SharePoint consultants. Loads of fun in their stories, favorite moments, plus some special audible timeline tidbits with a song or two to round it all out.
Intrazone guests – clockwise, starting top left – first row: Jeff Teper (CVP | Microsoft), Lauren Antonoff (President, independents | GoDaddy), Bjørn Olstad (CVP | Microsoft), Rob Lefferts (CVP | Microsoft) – bottom row: Adam Harmetz (Partner director of program management | Microsoft), Adis Jugo (Co-founder and CEO | Nubelus), and Spencer Harbar (Enterprise architect).
The history of SharePoint timeline – Visio diagram and list of key milestones
Timeline view of the history of SharePoint (1998 – 2021).
Additional date contextual list of the what and when for SharePoint growth across versions, acquisitions and product/services spinoffs:
1997-1999 | Site Server & Site Server Commerce Edition
1999 | SharePoint begins as codename Tahoe connected to WebDAV
Alongside codename Platinum – aka, the next version of Exchange
1999 | Digital Dashboard Starter Kit (tools to help you customize Outlook 2000 – already billed as “
knowledge management solution from Microsoft)
Introduced “Nuggets”, what would become web parts
2000 | Digital Dashboard Resource Kit, aka, Tahoe beta 1 sitting on SQL Server 2000
2001 | Add a portal UI to the Digital Dashboard Resource Kit and SharePoint Portal Server 2001 is born
2001 | Microsoft acquires nCompass; re-branded the product Content Management Server 2001
2001 | Free Office 2000 add-on = Microsoft SharePoint Team Services (aka, the start to an online, extensible, collaborative platform)
2003 | SharePoint Team Services becomes Windows SharePoint Services (WSS), and Microsoft Office SharePoint Portal Server 2003 emerges
2005 | Microsoft acquires Groove (Peer-2-peer sync; pre-cursor to OneDrive sync) & Frontbridge and enters hosting infrastructure market
Note: Sarbanes-Oxley rears its head related to document and records management practices.
2005 | Microsoft introduces Hosted and Collaboration version 3.0; includes SharePoint Services 2.0
2007 | Microsoft Office SharePoint Server 2007, aka MOSS, combines STS, CMS
Microsoft acquires ProClarity and rebrands as Microsoft Performance Point 2007 – aka, the basis for BI at Microsoft.
2008 – 2009 | Business Productivity Online Suite (BPOS) expands to offer Exchange Online, Office Communications Online, Office Live Meeting, and SharePoint Online (built using SharePoint Server 2007)
Microsoft also acquires FAST, the precursor team and technology behind Microsoft Search
2010 | SharePoint Server 2010; Groove is renamed SharePoint Workspace
2010 | Steve Ballmer’s famous “We’re all in” speech at UW (March.4.2010)
2011 | BPOS rebrands – Office 365 launches, with SharePoint Server 2010 as it’s foundation
Live Meeting and Office Communicator are combined to form of Lync 2010 Online – the precursor to Microsoft Teams
2012 | SharePoint Server 2013; Groove sync tech is rebranded as SkyDrive Pro
2014 | OneDrive for Business, Office Delve, Office Graph (now Microsoft Graph) & Office 365 Video
2016 | SharePoint Server 2016
2017 | SharePoint Framework #SPFx, Microsoft Stream and Microsoft Teams
2018 | SharePoint Server 2019
2020 | Microsoft Lists & SharePoint Syntex
2021 | Microsoft Viva (Connections, Topics, Learning, and Insights)
Bonus fun you can sing along with
Jeff Teper’s, Beatles-inspired, “SharePoint at 20” birthday singalong:
“Happy Birthday, SharePoint” sung by 100s of SharePoint engineers via Teams:
Be sure to visit our show page to hear all the episodes, access the show notes, and get bonus content. And stay connected to the SharePoint community blog where we’ll share more information per episode, guest insights, and take any questions from our listeners and SharePoint users (TheIntrazone@microsoft.com). We, too, welcome your ideas for future episodes topics and segments. Keep the discussion going in comments below; we’re hear to listen and grow.
























Recent Comments