by Contributed | Apr 23, 2021 | Technology
This article is contributed. See the original author and article here.
Hello Folks! @Guido here.
This is my very first blog and I’d like to share with you how we can add or remove members from FSLogix local groups using a GPO.
To recap
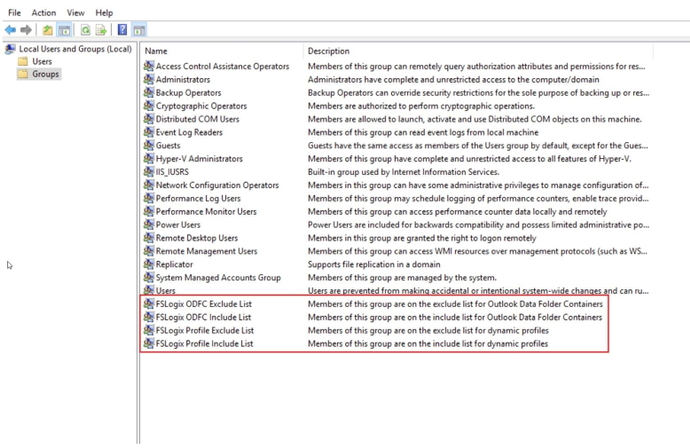
There are often users, such as local administrators, that have profiles that should remain local. During installation, four user groups are created to manage users who’s profiles are included and excluded from Profile Container and Office Container redirection.
FSLogix include or Exclude groups allow us to add or exclude members from FSLogix service so the users can get the default local profile instead using a FSLogix container.
- By default Everyone is added to the FSLogix Profile Include List group.
- Adding a user to the FSLogix Profile Exclude List group means that the FSLogix agent will not attach a FSLogix profile container for the user.
- FSLogix Profile Exclude List group take priority over FSLogix Profile Exclude List group if there is a member on both Local Groups.
Adding or removing member of a Local Groups is extremely easy on a few machines but what happens if you have deployed hundred or thousands of machines? Here where Restricted Groups comes into play.
Restricted Groups
Restricted groups allow an administrator to define the following two properties for security-sensitive (restricted) groups:
Using the “Members” Restricted Group Portion of Policy
When a Restricted Group policy is enforced, any current member of a restricted group that is not on the “Members” list is removed with the exception of administrator in the Administrators group. Any user on the “Members” list which is not currently a member of the restricted group is added.
Using the “Member Of” Restricted Group Portion of Policy
Only inclusion is enforced in this portion of a Restricted Group policy. The Restricted Group is not removed from other groups. It makes sure that the restricted group is a member of groups that are listed in the Member Of dialog box.
Let’s start
- Open Group Policy Management Console
- Create a new GPO or edit an existing one.
- Go to Computer Configuration –> Policies —>Windows Settings–>Security Settings–>Restricted Groups
- Right click over Restricted Group and select Add Group
- Type the Group you you want to add or remove members. The name must match with the local one. I recommend you to just copy and paste the name to avoid mistakes.

Then add the members in Members of this group

Note: Adding members in Members of this Group option will be deleting other local members if they already exist. If you want to keep the existing members, just add the members under This group is member of option
You can validate it from client machine local group side.

Hope you find this useful and informative.
Keep in touch.
Guido.
by Contributed | Apr 23, 2021 | Technology
This article is contributed. See the original author and article here.
SQL server is a batch oriented service, just like any DBMS. One program has to query it in order to get the result – so to have real time analytics we would have to change this batch behavior to a streaming /event/push behavior.
On the other side, we have azure with Azure Event Hubs, Stream analytics and Streaming datasets on Power BI. They work pretty well together if the data source is a streaming, producing events (something we can have with an custom code application or some Open Source solution with Kafka.
The challenge here was to find something to make the bridge between SQL Server and Event Hubs.
After some time looking for solutions on the internet, I found this Docs <reference> page with an approach to bring CDC data from Postgres to Event Hubs.
The solution proposed to use an Apache Kafka based solution named Debezium <reference>. This was so far unknown to me. With Debezium, one solution can monitor a CDC source and generate the events on a Kafka enables hub.
The initial setup seems a bit complex and it do not run on windows, so I had to find easier ways to enable this deployment.
Have you event thought about Docker?
It works pretty well on windows 10 or any build after (Build number…18363?) because of WSL2 <reference>. If you still never tried WSL2, I hightly recommend it.
After a few tries, I installs a WSL2 – Ubuntu 20.04 based and with that I could install Docker Desktop on my Windows 10 Surface Book :smiling_face_with_smiling_eyes:
Note: Docker Desktop works well for your development env. For production, you can install it on ACI or AKS <reference, reference>
With that said, Debezium had a Docker Image available on hub.docker.com, named Debeziumserver.
Debezium Server is a lightweight version that do not have Kafka installed. The image has already installes the SQL Server connector and can output the events directly to Event Hubs.
To install and configure the docker, I ran only this line of code
docker run -d -it –name SampleDebezium -v $PWD/conf:/debezium/conf -v $PWD/data:/debezium/data debezium/server
My SQL Server is hosted on Azure and to create a lab enviorement, I created a single table and ebabled CDC on it
<script>
Debezium will query the latest changed rows on CDC based on how it is setted on the configuration file and create the events on Event Hub
<sample configuration file>
Event Hub:
I created a sample event hub to hold this experiment.
But how to consume the events?? -> Stream analytics
With Stream analytics I consumes the events and created 2 outputs.
Azure Data Lake output
I’m saving every event on a Azure data lake for doing later analytics. This approach even enables to move from a OLTP on premises database to a modern Data Warehouse architecture with a incremental CDC based load. More need to be worked and tested here – Maybe a next post
Power BI Output
The Power BI output created a real tine dataset that can be consumes from a Power BI Dashboard.
Difference between real time dataset and Direct Query <reference>
Make it work and test
I created a script who negates data on my CDC enables table to test this method. The script will <describe the script>
<Add the script from GitHub>
Lets assure the Debezium server container is running
Show query output on Steam Analytics
Create the tiles on a Power BI Dashboard
See it running
<Add a .gif with real time enables dashboard and the SQL Server creating data>
Known problem
It seems when a big transaction (like a update on 200k rows) happens, Debezium stops complaining the message was bicker than the maximum size defined from Event Hubs. Maybe there is a way to break it on smaller messages, maybe it is how it works, so our system shoun only run OLTP (row by row) workload.
Acknowledgment
Special thanks to Goran, who guided me on my first steps on Stream Analytics
<Add a gif >
# References
# Architecture https://debezium.io/documentation/reference/architecture.html#_debezium_server
# Docker image with example https://hub.docker.com/r/debezium/server
# Debezium Server https://debezium.io/documentation/reference/1.4/operations/debezium-server.html
# SQL Server connector https://debezium.io/documentation/reference/connectors/sqlserver.html
# Azure Event hubs connection https://debezium.io/documentation/reference/1.4/operations/debezium-server.html#_azure_event_hubs
by Contributed | Apr 23, 2021 | Technology
This article is contributed. See the original author and article here.
Here’s an excerpt. Please find the full article on https://lnkd.in/gMqFCnW
Machine Learning Services is a feature of Azure SQL Managed Instance that provides in-database machine learning, supporting both Python and R scripts. The feature includes Microsoft Python and R packages for high-performance predictive analytics and machine learning. The relational data can be used in scripts through stored procedures, T-SQL script containing Python or R statements, or Python or R code containing T-SQL.
Use Machine Learning Services with R/Python support in Azure SQL Managed Instance to:
· Run R and Python scripts to do data preparation and general purpose data processing
· Train machine learning models in database
· Deploy your models and scripts into production in stored procedures
by Contributed | Apr 23, 2021 | Technology
This article is contributed. See the original author and article here.
A common conversation for bringing Oracle workloads to Azure always surrounds the topic of Real Application Clusters, (RAC). As it’s been quite some time since I’ve covered this topic, I wanted to update from this previous post, as with the cloud and technology, change is constant.
One thing that hasn’t changed is my belief RAC is A solution for Oracle for a specific use case and not THE solution for Oracle. The small detail that Oracle won’t support RAC in any third-party cloud is less important than the lack of need for RAC in most cases for those migrating to an enterprise level cloud such as Azure.
Not So Lift and Shift
Whenever we are working on migrating Oracle workloads to Azure, it is important for us to focus on how we should most effectively architect for the Azure cloud and not to just lift and shift what exists onprem. A common challenge during cloud migrations is when an attempt is made to duplicate everything onprem in the cloud or simply treating the cloud like another data center, not realizing how much high availability is built into Azure that isn’t in their onprem data center.
We often experience customers implementing redundancy in products, features and at the same time, introducing redundancy and sometimes their own failures. Most common abuses are in the areas of hypervisors on top of hypervisors, mirroring/storage copies and storage management tripping all over itself and this topic, high availability products.
In Data Guard We Trust
Due to this transparent and very important part of the Azure cloud, the most common Oracle architecture deployed are single instance Oracle databases, (often from onprem RAC) with Oracle Data Guard standbys to support both disaster recovery and high availability using features that surprisingly, less technologists are aware of than we’d like.
When we’ve completed an Oracle sizing and architecture assessment here at Microsoft with a customer, the diagrams look very similar to the following:
Fig. 1
As there are several topics around why we so rarely use RAC in Azure, I’m going to take each of these on separately and hopefully cover the important details.
High Availability Cluster
If we were to build out a RAC cluster in the Azure cloud, unlike an Always on Availability Group, all the nodes for RAC are deployed only to a single Availability Zone. If we think about high availability architecture design, you will realize that this architecture will fail basic HA requirements.

Fig. 2
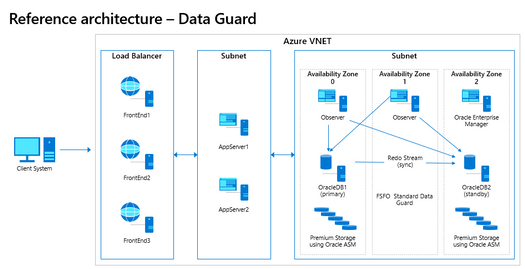
Oracle Data Guard is very similar in design to Always on AG and an essential part of any Disaster Recovery architecture design. Notice in the diagram, Figure 3, if the RAC in Availability Zone 1 goes down, there will be an outage unless there is an Oracle Data Guard standby available in another Availability Zone to failover to.

Fig. 3
With Oracle Data Guard, we can configure several features to build out a full-blown, highly available architecture that can support 8-9’s of uptime. With Oracle Data Guard configured with Fast-Start Failover, (FSFO) if the primary database becomes unavailable or goes down for any reason, the secondary will automatically become the primary and take over in a matter of seconds. A notification can be set up in Oracle Enterprise Manager to notify those responsible, but this failover happens in seconds when configured correctly in Azure, allowing for transparent failover to a secondary standby in a second availability zone.
To take this a step further, you can configure the DG Broker and set up Oracle Observer in secondary Availability zones, (with full redundancy) to failover applications that are failover compatible. This results in a transparent failover of new sessions to the secondary when FSFO comes into play, failing over the database.
We can deploy the primary in one Availability Zone and a standby in a second Availability Zone, creating a fully redundant and automatic failover solution. As Oracle Data Guard can support numerous standby databases, these HA and DR copies can be deployed in multiple Availability Zones and secondary regions to meet the customer’s RPO/RTO, no matter how complex the SLA.
For Oracle’s Maximum Availability Architecture, (MAA) to reach a gold standard, Oracle Data Guard must be part of the deployed solution. As customers often move to storage snapshots from RMAN for backups, having Data Guard features, such as DBverify and Analyze to perform logical checks for intra-block and inter-object consistency offers added benefits. Data Guard provides in-memory intra-block checks and shadow lost write protection if there is an interruption in service to the storage layer to the database.
For an additional charge of Active Data Guard, the standby can be used for an RMAN backup target to offload the demand on the primary database, as well as offload the intra-block logical checks to the standby in its active read-only mode.
We can also use a separate Far Sync instance to guarantee zero data loss by performing a compressed offload compressed transport of the redo to the Active standby database. This also offers the ability to perform continuous Oracle validation to the standby and additional encryption to secure business data.
High Availability via rolling patches and upgrades
As RAC isn’t supported in any third-party cloud, Azure specialists are going to investigate the solutions that do provide what is required and for Azure cloud, Oracle Data Guard is very compatible with Azure cloud infrastructure HA. Another nice feature that many aren’t aware of is that with Oracle Active Data Guard, (active/active, secondary is a read-only active standby) you can do switch overs and using the DBMS_ROLLING package provided with Oracle 19c, you can do rolling patches and upgrades. This provides one of the most loved features of Oracle RAC by DBAs and is very little known in Data Guard.
With DBMS_ROLLING and Active Data Guard, database and application downtime can be decreased to seconds with a fault tolerant, resumable and rollback capable solution.
Scalability
This is the best reason to use RAC and for many, the least common reason we’ve often seen businesses choose it. For an OLTP or hybrid database workload that requires significant CPU and memory and the database design has been optimized for RAC, considerable demanding workloads can be leveraged with the product. When we reach for RAC over OS level clustering with load balancer or a larger VM that can handle the workload has to do with per VM limits we can’t work our way around. There are significant challenges with concurrency, initial transaction locking, GC waits or shipping between nodes that are outside of this discussion, but you do realize the benefit that could be brought to the table with RAC…but not in Azure or any other third-party cloud if you want it supported by Oracle. It’s not about the shared storage or even the multi-cast network that’s the problem, it’s simply around supportability by Oracle.
Although we’re not able to use RAC for scalability, for heavy read-only workloads, we can use Oracle’s Active Data Guard standbys, in a read-only active mode to disperse those application compatible workloads, retaining the primary to only process the transactional workload.
Oracle Sharding offers another option for scalability, spreading the database, with a shared-nothing architecture, across multiple databases/hosts using shard keys. Sharding is a horizontal partitioning of data across numerous databases and each shard holds a subset of the total data source vs. housing in a single database. As RAC isn’t supported in any third-party cloud, this is deployed in the Azure cloud without a RAC clusterware backbone but is able to use Oracle’s multi-tenant feature with the additional licensing.

Fig. 4
For those workloads that absolutely need a RAC solution, we leverage OS level clustering in Azure VMs using PaceMaker and for the customers who can adopt a co-location, we recommend Azure BareMetal RAC offering. This is a proximity located Co-Lo to Azure that can offer RAC for customer that absolutely must have it. The infrastructure is supported by Azure and everything above that is supported by the customer.
There is also Azure RAC BareMetal which is in a gated GA status. Bare Metal, which are dedicated machines in a co-location configuration in proximity to the Azure cloud offers a RAC solution where the infrastructure is supported by Azure, but everything above this is managed by the customer.

Fig. 5
Latency between the Bare Metal solution and other Azure services and VMs is minimized, along with additional high availability built into the offering to support what would be missing from most onprem data center deployments.
Azure Bare Metal can support RAC One Node and standard RAC deployments with an HA storage configuration to support the demands of 2 and 4 Node RAC configurations in a highly scaled, enterprise cloud solution.
A customer may use Flashgrid on Azure with the understanding that all support for this RAC solution running in Azure must go through Flashgrid. Neither Oracle nor Microsoft can support RAC running inside the Azure cloud, but Flashgrid has shown a history of offering solid support for their customers.
Although initially, we hoped to use Azure’s shared storage for an option to run Oracle RAC in our cloud, we’ve backtracked from this due to support constraints and same goes for networking advancements in Azure. It’s not that we can’t run RAC in Azure, it’s just that it isn’t supported, and our main goal is long term customer satisfaction and supportability in Azure. No matter your feelings on RAC, the goal for this post was to discuss what features are best suited for a deployment in Azure making Oracle highly available, easy to manage and most likely to receive vendor support.

by Contributed | Apr 23, 2021 | Technology
This article is contributed. See the original author and article here.
About Me
My name is Chak Koppula https://ckoppula199.github.io/ and I’m a 3rd year Computer Science student at University College London and have been working alongside Microsoft’s Project 15 team to help in creating a system to reduce the poaching of elephants.
Project Aims and Goals
The overall aim of the project is to create a system that utilises the Project 15 platform to identify and track the movement of elephants. The African elephant population has reduced by 20% in the past decade due to poaching meaning keeping track of them has become vital in preventing their numbers from further decreasing.
To help in the development of this system I made three tools:
Source Code
ckoppula199/UCL-Microsoft-IXN-Final-Year-Project (github.com)
Video Indexer Analysis Script
The following Python script that takes videos of surveillance footage from Azure cloud storage and passes them to Azure Video Indexer to obtain quick insights into a video.
import requests
import os
import io
import json
import time
from azure.storage.blob import (
ContentSettings,
BlobBlock,
BlockListType,
BlockBlobService
)
# Load details from config file
with open('config.json', 'r') as config_file:
config = json.load(config_file)
storage_account_name = config["storage_account_name"]
storage_account_key = config["storage_account_key"]
storage_container_name = config["storage_container_name"]
video_indexer_account_id = config["video_indexer_account_id"]
video_indexer_api_key = config["video_indexer_api_key"]
video_indexer_api_region = config["video_indexer_api_region"]
file_name = config["file_name"]
confidence_threshold = config["confidence_threshold"]
print('Blob Storage: Account: {}, Container: {}.'.format(storage_account_name,storage_container_name))
# Get File content from blob
block_blob_service = BlockBlobService(account_name=storage_account_name, account_key=storage_account_key)
audio_blob = block_blob_service.get_blob_to_bytes(storage_container_name, file_name)
audio_file = io.BytesIO(audio_blob.content).read()
print('Blob Storage: Blob {} loaded.'.format(file_name))
# Authorize against Video Indexer API
auth_uri = 'https://api.videoindexer.ai/auth/{}/Accounts/{}/AccessToken'.format(video_indexer_api_region,video_indexer_account_id)
auth_params = {'allowEdit':'true'}
auth_header = {'Ocp-Apim-Subscription-Key': video_indexer_api_key}
auth_token = requests.get(auth_uri,headers=auth_header,params=auth_params).text.replace('"','')
print('Video Indexer API: Authorization Complete.')
print('Video Indexer API: Uploading file: ',file_name)
# Upload Video to Video Indexer API
upload_uri = 'https://api.videoindexer.ai/{}/Accounts/{}/Videos'.format(video_indexer_api_region,video_indexer_account_id)
upload_header = {'Content-Type': 'multipart/form-data'}
upload_params = {
'name':file_name,
'accessToken':auth_token,
'streamingPreset':'Default',
'fileName':file_name,
'description': '#testfile',
'privacy': 'Private',
'indexingPreset': 'Default',
'sendSuccessEmail': 'False'}
files= {'file': (file_name, audio_file)}
r = requests.post(upload_uri,params=upload_params, files=files)
response_body = r.json()
print('Video Indexer API: Upload Completed.')
print('Video Indexer API: File Id: {}.'.format(response_body.get('id')))
video_id = response_body.get('id')
# Check if video is done processing
video_index_uri = 'https://api.videoindexer.ai/{}/Accounts/{}/Videos/{}/Index'.format(video_indexer_api_region, video_indexer_account_id, video_id)
video_index_params = {
'accessToken': auth_token,
'reTranslate': 'False',
'includeStreamingUrls': 'True'
}
r = requests.get(video_index_uri, params=video_index_params)
response_body = r.json()
while response_body.get('state') != 'Processed':
time.sleep(10)
r = requests.get(video_index_uri, params=video_index_params)
response_body = r.json()
print(response_body.get('state'))
print("Done")
output_response = []
item_index = 1
for item in response_body.get('videos')[0]['insights']['labels']:
reformatted_item = {}
instances = []
reformatted_item['id'] = item_index
reformatted_item['label'] = item['name']
for instance in item['instances']:
reformatted_instance = {}
if instance['confidence'] > confidence_threshold:
reformatted_instance['confidence'] = instance['confidence']
reformatted_instance['start'] = instance['start']
reformatted_instance['end'] = instance['end']
instances.append(reformatted_instance)
if len(instances) > 0:
item_index += 1
reformatted_item['instances'] = instances
output_response.append(reformatted_item)
#Print response given by the script
print(json.dumps(output_response, indent=4))
Demo
Camera Trap Simulator
The camera trap simulator allows users to simulate a real camera trap on their own computers and can even be run on devices such as a Raspberry Pi. It takes in a video feed and then uses a detection method over that video feed. If the detection method is triggered then it will send a message to Azure IoT hub. Once the data is in the cloud the user can test out their cloud paths and solutions as if the data had come from a real camera trap.
The camera trap can operate over both a live video feed such as a webcam or it can be used with a pre-recorded video feed. A video of the intended deployment area can be provided to the simulator to make the simulation more realistic, but for projects who don’t have access to videos of their deployment area, a live video feed may be fine for testing and development purposes.
The camera trap can use motion based detection or can utilise a Machine Learning model to more accurately identify points of interest within a video frame. Use of an ML model will reduce the number of false positives the systems gives and will be a more accurate.

Above is an image showing the motion detection software running. It uses a method of motion detection known as foreground detection. The top left is the normal video feed, the top right is a greyscaled and blurred version of the video feed, the bottom left is the difference between the current frame and the reference frame and the bottom right is the final result showing any moving object in white.simulation but if an ML model isn’t available then motion detection can be used for testing and development purposes.
Demo
Machine Learning Models
When creating the models there was difficulty in collecting a suitable dataset. Initially the plan was to use our own devices in the deployment area to create our own dataset of images to use for training purposes but due to time constraints and various blockers I ended up having to utilise a public dataset called Animals-10 from Kaggle which contained images of elephants among other animals.
I then created a set of image classification models using Python with TensorFlow and also created a set of object detection models using Azure Custom Vision services.
The first image classification model that was made used a very simple Convolutional Neural Network and achieved an accuracy of 77% on a test set. The second image classification model used a CNN architecture known as VGG-16 which performed much better with an accuracy of 97% on the test set. The confusion matrices for these two models can be seen below.

The object detection models made using Azure Custom Vision also achieved quite high results as shown below.

The object detection model was only trained using around 130 images of elephants and managed to achieve the above metrics. More images weren’t used since when providing images for the object detection models to train on, you have to tag every occurrence of every object you want to model to identify which can be quite time consuming.

The object detection model ended up being able to identify most elephants in an image, struggling on in cases where elephants were obscured. In the above image you can see in the bottom middle of the image there is a single elephant hidden by bush the model didn’t quite manage to identify.
The conclusion that was reached was that for our use case object detection should be used. This is due to it not only saying if an image is of an elephant, but it providing the additional information of how many elephants are in the image and where in the image they are. This extra information that can’t be provided by image classification allows for more uses case to be fulfilled by the system later on. Azure custom vision was also chosen as the method to use as while TensorFlow is an incredible library allowing users to specify the exact architecture and hyperparameters that they want to use, it can take a long time to find the optimal setup and also requires more data to train on to achieve the same level of results produced by Azure Custom Vision. The ease of use and its ability to seamlessly work with other Azure services being used in the Project 15 platform make Azure Custom Vision the best choice for this project.
Demo
Summary
Overall, the process of learning about cloud services and machine learning tools has been extremely enjoyable and getting the opportunity to apply what I learnt to a real world project like this has been an incredible experience. So if your interested in building a project to support Project 15 see Project 15 Open Platform for Conservation and Ecological Sustainability Solutions or if your new to this see the amazing resources to help get your started at Microsoft Learn.

Recent Comments