by Contributed | Jun 30, 2021 | Technology
This article is contributed. See the original author and article here.
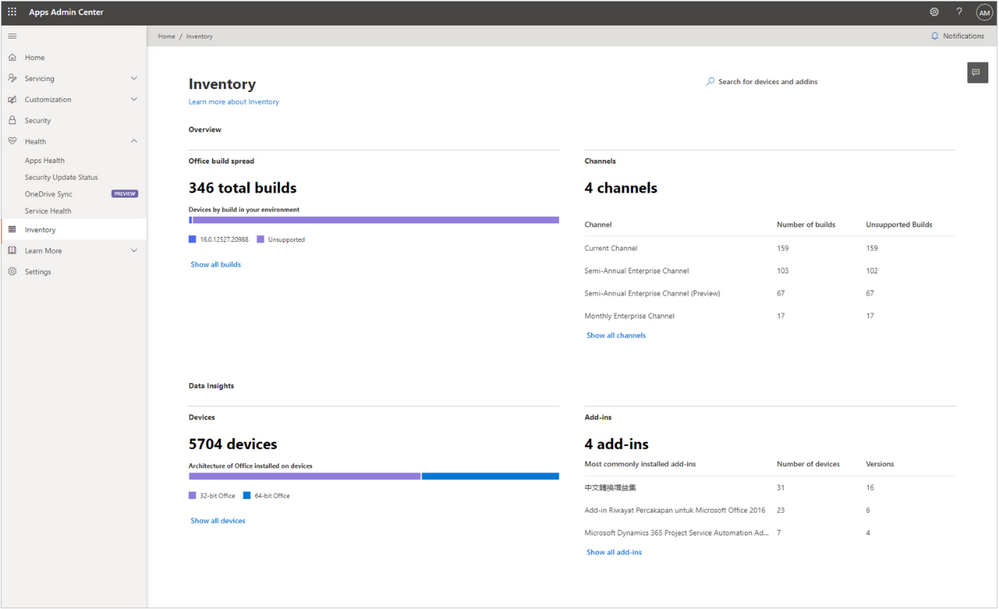
Today, we are happy to announce the General Availability (GA) of the new Inventory in the Microsoft 365 Apps admin center; a new experience specifically tailored to provide admins instant answers on the state of Microsoft 365 Apps in the enterprise environment.
Using the new dashboards, you as an admin can quickly identify potential issues. By getting a view of the build spread in your organization, you evaluate if you need to consolidate and update devices running unsupported Office app versions. You can see detailed information about add-ins installed on devices across the organization. You also have access to the raw Inventory, so you can drill through the device-level details and use filters to create views based on your requirements.
We also are happy to release the Security Update Status feature to GA. Based on inventory data, you as an IT pro can get an overview of how many devices are already running the latest security updates. You can slice and dice the data per channel or drill down to a list of devices missing security updates for the Microsoft 365 Apps. The report can be customized by setting your own goals for security currency and get a near-real time view of how close you are to these goals, such as having 90% of all devices running the latest security update within five days.
Both features are true cloud services providing you, as an admin, unparalleled insight into channels, releases, security and support status. Paired with the fact that both features span all Microsoft 365 Apps instances activated by your tenant, regardless of the management or directory domain of the device, this gives admins a more complete picture.
Overview
As mentioned, the Inventory in the Microsoft 365 Apps admin center is loaded with detailed reports and insights which are specifically built for the Microsoft 365 Apps. Onboarding is simple. Just visit Inventory on config.office.com and click, “Get started.” This enables devices to register to the service, and admins can get a full overview of their devices with Microsoft 365 Apps installed within a few hours. The landing page highlights key insights, flagging how many different releases are deployed, which update channels are in use, what the architecture split looks like, and what the most installed add-ins are:
Inventory – Providing easy overview of e.g. different releases of the Microsoft 365 Apps
Each insight has rich data behind it, which you can explore in greater detail by navigating into the different sections. You can get a full breakdown of all releases down to the device level. Or, see additional information about a given device and its Microsoft 365 Apps installation:
 Detail pane of a devices, showing device name, memory, installed version of Windows and Office and more
Detail pane of a devices, showing device name, memory, installed version of Windows and Office and more
Maybe you are interested in getting a better understanding of which Component Object Model (COM)-based add-ins are installed in your environment or how many installs of different versions are out there:
 Add-in view in Inventory, showing a list of add-ins and version breakdown
Add-in view in Inventory, showing a list of add-ins and version breakdown
Based on the same near-real time data from devices powering Inventory, you can also assess your security stance using the Security Update Status page:
 Security Update Status page giving an overview how many devices are running the latest updates as well as a detailed breakdown by channel
Security Update Status page giving an overview how many devices are running the latest updates as well as a detailed breakdown by channel
On a high level, you get an immediate insight into the share of devices which are already running the latest security update. You then can drill through this data by breaking the status down per channel or getting a full list of devices missing important security updates.
As mentioned before, this not only includes managed devices, but all devices which have a Microsoft 365 Apps installation that has been activated and used by an Azure Active Directory (AAD) user from your tenant. This way, you could also identify Bring Your Own Devices (BYOD), which would pose a risk to your tenant by missing important security updates.
From our early adopters
Since Ignite 2020, when these features were released into preview, our engineering and Microsoft 365 Apps Ranger teams have partnered with customers around the world, ranging in size from 10,000 to 300,000 seats across the enterprise and education spaces. While we shaped and improved the service during the preview phase, we consistently heard the following feedback from those early adopters:
Putting the new Inventory as well as the Security Update Status feature to work is as easy as can be. As true cloud services, there is no need to set up on-premises infrastructure, deploy software agents or policies to devices. Within minutes after the activation, admins were able to see the inventory populate automatically. Leveraging the unified integration into the Office product, it can be run side-by-side with other inventory solutions. For example, a device can report to Microsoft Endpoint Configuration Manager while the Microsoft 365 Apps installation reports its inventory directly to the Microsoft 365 Apps admin center.
The second important aspect was that Inventory, as well as the Security Update Status page, are specifically tailored to the Microsoft 365 Apps and are available in one place. Instead of having to build custom reports in a management solution which might be operated and owned by another team, the admin team owning the Microsoft 365 Apps get pre-build reports which they can access at any time.
Finally, customers valued the deep insights into which add-ins and versions are installed on devices. Often, add-ins can influence the user experience dramatically when it comes to performance and stability of the Microsoft 365 Apps. Several customers used this data to consolidate a wide version spread for an add-in or kicked off uninstall campaigns for add-ins which are out of support and should no longer be used.
Get started today
We encourage you to start evaluating the Inventory and the Security Update Status page. It only takes a few minutes to enable the new feature. It does not block other management solutions and the registration into Inventory is silent to the user. Just navigate to the Inventory overview page, enable the feature and see devices trickle in within minutes. To learn more, check out our documentation or watch the video from Ignite.
This is just the starting point
Today, there are more than 18 million devices registered into Inventory. We’ve gotten overwhelmingly positive feedback on today’s capabilities, but we’re not stopping anytime soon . We are working on even more features built on top of Inventory, like security vulnerability reporting, historical uptake trends for the Security Update Status, insights into add-in usage as well as cross-update channel comparisons, to name a few.

by Contributed | Jun 30, 2021 | Dynamics 365, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Today, we’re announcing that use rights for Dynamics 365 Field Service (on-premises) will be retired on June 30, 2022. If your organization is currently using an on-premises version, this blog post gives you information to help you understand and plan for this change.
What is Dynamics 365 Field Service (on-premises)?
Dynamics 365 Field Service (on-premises) allows organizations to install and run Field Service version 7 and applications on computers located on site rather than as a service in the cloud. On-premises implementations of the Field Service application will no longer be supported after June 30, 2022.
How will this change affect my organization?
If your organization is currently using Dynamics 365 Field Service (on-premises), you’ll need to migrate to Dynamics 365 Field Service.
Are there any resources to help me move to the cloud?
Yes. The Dynamics 365 Migration Program is available to assist our customers with migrating from on-premises to the cloud. If you have questions specifically related to a Field Service migration, send us an email.
What will happen to the mobile app that works with Dynamics 365 Field Service (on-premises)?
Field Service Mobile (Xamarin) is also being retired June 30, 2022, and it will no longer be available. For more information about the Field Service mobile apps, go to the documentation.
What will happen with my organization’s Dynamics 365 Field Service (on-premises) license?
Licensing for Dynamics 365 Field Service (on-premises) is provided through dual use licenses, per the Dynamics 365 on-premises licensing guide. Organizations currently using Field Service licenses for on-premises implementations can use those same licenses for Field Service online.
When is this change taking place?
Availability of Dynamics 365 Field Service (on-premises) will end June 30, 2022.
When will the download package for the on-premises version become unavailable?
The download package to install Dynamics 365 Field Service (on-premises) will no longer be available after Dec 31, 2021.
What will happen to my Field Service (on-premises) implementation after June 30, 2022?
If you’ve already installed the on-premises version, it will still be available for your organization. However, new installations of Field Service (on-premises) will no longer be available from Microsoft. Also, the Field Service Mobile application that works with Field Service (on-premises) will be retired and no longer available after June 30, 2022.
I have a government implementation. Where is the Dynamics 365 sovereign cloud available?
The geographic regions where the Dynamics 365 sovereign cloud and Dynamics 365 Field Service are available is described in the Infrastructure and availability PDF.
Will I have to upgrade my version of Dynamics 365 Field Service when moving online?
Yes. The on-premises version will need to be updated through a proven upgrade process to the latest online version of Dynamics 365 Field Service.
Does this change also apply to other Dynamics 365 Customer Engagement (on-premises) apps?
No. This change does not apply to other Dynamics 365 on-premises apps.
Next steps
If you have any questions about this change, or need help with planning your Field Service (on-premises) migration, send us an email and we’ll connect you with the best resources to help you move forward.
Learn more about Dynamics 365 Field Service capabilities in the documentation.
The post Dynamics 365 Field Service (on-premises) use rights to retire on June 30, 2022 appeared first on Microsoft Dynamics 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | Jun 30, 2021 | Technology
This article is contributed. See the original author and article here.
Introduction:
Traditionally, one of the most powerful techniques used to accelerate query processing in data warehouses is the pre-computation of relevant summaries or materialized views.
The initial implementation introduced in Apache Hive 3.0.0 focuses on introducing materialized views and automatic query rewriting based on those materializations in the project. Materialized views can be stored natively in Hive or in other custom storage handlers (ORC), and they can seamlessly exploit exciting new Hive features such as LLAP acceleration. Then, the optimizer relies in Apache Calcite to automatically produce full and partial rewritings for a large set of query expressions comprising projections, filters, join, and aggregation operations.
In this document, we provide details about materialized view creation and management in Hive against the source parquet tables.
Materialized views creation:
The syntax to create a materialized view in Hive is very similar to the CTAS statement syntax, supporting common features such as partition columns, custom storage handler, or passing table properties.
Standard Syntax:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db_name.]materialized_view_name
[DISABLE REWRITE]
[COMMENT materialized_view_comment]
[PARTITIONED ON (col_name, ...)]
[CLUSTERED ON (col_name, ...) | DISTRIBUTED ON (col_name, ...) SORTED ON (col_name, ...)]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
AS
<query>;
Example wrt Parquet source tables:
Table description:
0: jdbc:hive2://zk0-hdilla.xi2kmm3bon0engqedn> desc formatted hive_parquet;
+-------------------------------+----------------------------------------------------+-----------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------------+
| # col_name | data_type | comment |
| clientid | string | |
| querytime | string | |
| market | string | |
| deviceplatform | string | |
| devicemake | string | |
| devicemodel | string | |
| state | string | |
| country | string | |
| querydwelltime | double | |
| sessionid | bigint | |
| sessionpagevieworder | bigint | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | default | NULL |
| OwnerType: | USER | NULL |
| Owner: | anonymous | NULL |
| CreateTime: | Mon Jun 21 11:38:49 UTC 2021 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | abfs://hdillap-2021-06-09t16-52-55-399z@hiverepl.dfs.core.windows.net/hive/warehouse/managed/hive_parquet | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {"BASIC_STATS":"true"} |
| | bucketing_version | 2 |
| | numFiles | 1 |
| | numRows | 59793 |
| | rawDataSize | 657723 |
| | totalSize | 1419783 |
| | transactional | true |
| | transactional_properties | insert_only |
| | transient_lastDdlTime | 1624275529 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe | NULL |
| InputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+----------------------------------------------------+-----------------------------+
Example 1: Create materialized view on parquet table with partition on country column:
CREATE MATERIALIZED VIEW hivemv1
PARTITIONED ON (country)
STORED AS ORC
AS
SELECT * FROM hive_parquet;
Example 2: Create MV parquet table with partition on country column and sort defined on one column
CREATE MATERIALIZED VIEW hivemv3
PARTITIONED ON (country)
STORED AS ORC
AS
SELECT * FROM hive_parquet order by deviceplatform;
Other operations for materialized view management:
Currently we support the following operations that aid at managing the materialized views in Hive:
-- Drops a materialized view
DROP MATERIALIZED VIEW [db_name.]materialized_view_name;
-- Shows materialized views (with optional filters)
SHOW MATERIALIZED VIEWS [IN database_name] ['identifier_with_wildcards’];
-- Shows information about a specific materialized view
DESCRIBE [EXTENDED | FORMATTED] [db_name.]materialized_view_name;
Example:
0: jdbc:hive2://zk0-hdilla.xi2kmm3bon0engqedn> show materialized views;
+------------+--------------------+-----------------+
| mv_name | rewrite_enabled | mode |
+------------+--------------------+-----------------+
| # MV Name | Rewriting Enabled | Mode |
| hivemv | Yes | Manual refresh |
| hivemv1 | Yes | Manual refresh |
| hivemv2 | Yes | Manual refresh |
| | NULL | NULL |
+------------+--------------------+-----------------+
Materialized view-based query rewriting:
Once a materialized view has been created, the optimizer will be able to exploit its definition semantics to automatically rewrite incoming queries using materialized views, and hence, accelerate query execution.
The rewriting algorithm can be enabled and disabled globally using the hive.materializedview.rewriting configuration property (default value is true) and at materialized view level as below:
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name ENABLE|DISABLE REWRITE;
Materialized view maintenance:
When data in the source tables used by a materialized view changes, the rebuild operation for a materialized view needs to be triggered by the user. In particular, the user should execute the following statement:
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name REBUILD;
Hive supports incremental view maintenance, i.e., only refresh data that was affected by the changes in the original source tables. Incremental view maintenance will decrease the rebuild step execution time. In addition, it will preserve LLAP cache for existing data in the materialized view.
FYI, Hive will attempt to rebuild a materialized view incrementally, falling back to full rebuild if it is not possible. Current implementation only supports incremental rebuild when there were INSERT operations over the source tables, while UPDATE and DELETE operations will force a full rebuild of the materialized view.
To execute incremental maintenance, following conditions should be met:
- The materialized view should only use transactional tables, either micromanaged or ACID.
- If the materialized view definition contains a Group By clause, the materialized view should be stored in an ACID table, since it needs to support MERGE operation. For materialized view definitions consisting of Scan-Project-Filter-Join, this restriction does not exist.
A rebuild operation acquires an exclusive write lock over the materialized view, i.e., for a given materialized view, only one rebuild operation can be executed at a given time.
Materialized view lifecycle:
If the materialized view uses non-transactional tables and hence, we cannot verify whether its contents are outdated, however we still want to use the automatic rewriting. For such occasions, we can combine a rebuild operation run periodically, e.g., every 5 minutes, and define the required freshness of the materialized view data using the hive.materializedview.rewriting.time.window configuration parameter, for instance:
SET hive.materializedview.rewriting.time.window=10min;
The parameter value can be also overridden by a concrete materialized view just by setting it as a table property when the materialization is created.
Please note: By default, hive.materializedview.rewriting.time.window will be set to 0min which means auto rebuild is disabled. To enable at global level add the same with specific time interval under Ambari -> Hive config -> Custom hive-site. Also, the change will be applicable to the MVs created post this change.
Post the rewrite window, the update with MV could be validated by `desc formatted mv_name`.
....
Rewrite Enabled: | Yes | NULL
Outdated for Rewriting: | Yes | NULL
....
Example:
CREATE MATERIALIZED VIEW hivemv3
PARTITIONED ON (country)
STORED AS ORC
TBLPROPERTIES (hive.materializedview.rewriting.time.window"="10min")
AS
SELECT * FROM hive_parquet;
Examples with outputs:
Materialized view with sort on specific column
With distributed on or sort by on roadmap, to sort the data within materialized view – create the mv with order by clause with the select query.
CREATE MATERIALIZED VIEW hivemv14
PARTITIONED ON (country)
STORED AS ORC
AS
SELECT * FROM hive_parquet ORDER BY (devicemake);
The data stored in the ORC file is sorted and could be validated with command `/usr/bin/hive –orcfiledump -d <location_of_orc_file>`.
Refer: Attached sample ORC data file.
Description on the MV created: (desc formatted hivemv1)
+----------------------------------+----------------------------------------------------+-----------------------------+
| col_name | data_type | comment |
+----------------------------------+----------------------------------------------------+-----------------------------+
| # col_name | data_type | comment |
| clientid | string | |
| querytime | string | |
| market | string | |
| deviceplatform | string | |
| devicemake | string | |
| devicemodel | string | |
| state | string | |
| querydwelltime | double | |
| sessionid | bigint | |
| sessionpagevieworder | bigint | |
| | NULL | NULL |
| # Partition Information | NULL | NULL |
| # col_name | data_type | comment |
| country | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | default | NULL |
| OwnerType: | USER | NULL |
| Owner: | anonymous | NULL |
| CreateTime: | Mon Jun 21 11:44:00 UTC 2021 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | abfs://hdillap-2021-06-09t16-52-55-399z@hiverepl.dfs.core.windows.net/hive/warehouse/managed/hivemv1 | NULL |
| Table Type: | MATERIALIZED_VIEW | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {"BASIC_STATS":"true"} |
| | bucketing_version | 2 |
| | numFiles | 88 |
| | numPartitions | 88 |
| | numRows | 59793 |
| | rawDataSize | 39334953 |
| | totalSize | 841901 |
| | transient_lastDdlTime | 1624275840 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.ql.io.orc.OrcSerde | NULL |
| InputFormat: | org.apache.hadoop.hive.ql.io.orc.OrcInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| | NULL | NULL |
| # Materialized View Information | NULL | NULL |
| Original Query: | select * from hive_parquet | NULL |
| Expanded Query: | SELECT `clientid`, `querytime`, `market`, `deviceplatform`, `devicemake`, `devicemodel`, `state`, `querydwelltime`, `sessionid`, `sessionpagevieworder`, `country` FROM (select `hive_parquet`.`clientid`, `hive_parquet`.`querytime`, `hive_parquet`.`market`, `hive_parquet`.`deviceplatform`, `hive_parquet`.`devicemake`, `hive_parquet`.`devicemodel`, `hive_parquet`.`state`, `hive_parquet`.`country`, `hive_parquet`.`querydwelltime`, `hive_parquet`.`sessionid`, `hive_parquet`.`sessionpagevieworder` from `default`.`hive_parquet`) `hivemv1` | NULL |
| Rewrite Enabled: | Yes | NULL |
| Outdated for Rewriting: | No | NULL |
+----------------------------------+----------------------------------------------------+-----------------------------+
Data validation on materialized view:
0: jdbc:hive2://zk0-hdilla.xi2kmm3bon0engqedn> select * from hivemv1 limit 5;
INFO : Compiling command(queryId=hive_20210621163758_1a523251-bfd0-40ca-a9fd-ef463120b3d8): select * from hivemv1 limit 5
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:hivemv1.clientid, type:string, comment:null), FieldSchema(name:hivemv1.querytime, type:string, comment:null), FieldSchema(name:hivemv1.market, type:string, comment:null), FieldSchema(name:hivemv1.deviceplatform, type:string, comment:null), FieldSchema(name:hivemv1.devicemake, type:string, comment:null), FieldSchema(name:hivemv1.devicemodel, type:string, comment:null), FieldSchema(name:hivemv1.state, type:string, comment:null), FieldSchema(name:hivemv1.querydwelltime, type:double, comment:null), FieldSchema(name:hivemv1.sessionid, type:bigint, comment:null), FieldSchema(name:hivemv1.sessionpagevieworder, type:bigint, comment:null), FieldSchema(name:hivemv1.country, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20210621163758_1a523251-bfd0-40ca-a9fd-ef463120b3d8); Time taken: 1.111 seconds
INFO : Executing command(queryId=hive_20210621163758_1a523251-bfd0-40ca-a9fd-ef463120b3d8): select * from hivemv1 limit 5
INFO : Completed executing command(queryId=hive_20210621163758_1a523251-bfd0-40ca-a9fd-ef463120b3d8); Time taken: 0.01 seconds
INFO : OK
+-------------------+--------------------+-----------------+-------------------------+---------------------+----------------------+----------------+-------------------------+--------------------+-------------------------------+----------------------+
| hivemv1.clientid | hivemv1.querytime | hivemv1.market | hivemv1.deviceplatform | hivemv1.devicemake | hivemv1.devicemodel | hivemv1.state | hivemv1.querydwelltime | hivemv1.sessionid | hivemv1.sessionpagevieworder | hivemv1.country |
+-------------------+--------------------+-----------------+-------------------------+---------------------+----------------------+----------------+-------------------------+--------------------+-------------------------------+----------------------+
| 11786 | 22:33:53 | en-US | Android | Motorola | Quench XT5 | Saint John | 7.0328606 | 0 | 1 | Antigua And Barbuda |
| 11786 | 22:30:29 | en-US | Android | Motorola | Quench XT5 | Saint John | 68.3177076 | 0 | 0 | Antigua And Barbuda |
| 11786 | 22:35:02 | en-US | Android | Motorola | Quench XT5 | Saint John | 8.1046491 | 0 | 2 | Antigua And Barbuda |
| 11786 | 22:35:25 | en-US | Android | Motorola | Quench XT5 | Saint John | 26.3155831 | 0 | 3 | Antigua And Barbuda |
| 11786 | 22:36:00 | en-US | Android | Motorola | Quench XT5 | Saint John | 3.8841237 | 0 | 4 | Antigua And Barbuda |
+-------------------+--------------------+-----------------+-------------------------+---------------------+----------------------+----------------+-------------------------+--------------------+-------------------------------+----------------------+
5 rows selected (1.851 seconds)
Compute statistics:
One of the key use cases of statistics is query optimization. Statistics serve as the input to the cost functions of the optimizer so that it can compare different plans and choose among them.
analyze table hivemv1 partition(country) compute statistics for columns;
Table description post stats collection:
+----------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+----------------------------------+----------------------------------------------------+----------------------------------------------------+
| # col_name | data_type | comment |
| clientid | string | |
| querytime | string | |
| market | string | |
| deviceplatform | string | |
| devicemake | string | |
| devicemodel | string | |
| state | string | |
| country | string | |
| querydwelltime | double | |
| sessionid | bigint | |
| sessionpagevieworder | bigint | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | default | NULL |
| OwnerType: | USER | NULL |
| Owner: | anonymous | NULL |
| CreateTime: | Fri Jun 18 05:48:03 UTC 2021 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | abfs://hdillap-2021-06-09t16-52-55-399z@hiverepl.dfs.core.windows.net/hive/warehouse/managed/hivemv2 | NULL |
| Table Type: | MATERIALIZED_VIEW | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {"BASIC_STATS":"true","COLUMN_STATS":{"clientid":"true","country":"true","devicemake":"true","devicemodel":"true","deviceplatform":"true","market":"true","querydwelltime":"true","querytime":"true","sessionid":"true","sessionpagevieworder":"true","state":"true"}} |
| | bucketing_version | 2 |
| | numFiles | 1 |
| | numRows | 59793 |
| | rawDataSize | 45057355 |
| | totalSize | 737187 |
| | transient_lastDdlTime | 1623995315 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.ql.io.orc.OrcSerde | NULL |
| InputFormat: | org.apache.hadoop.hive.ql.io.orc.OrcInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| | NULL | NULL |
| # Materialized View Information | NULL | NULL |
| Original Query: | select * from hivesampletable | NULL |
| Expanded Query: | select `hivesampletable`.`clientid`, `hivesampletable`.`querytime`, `hivesampletable`.`market`, `hivesampletable`.`deviceplatform`, `hivesampletable`.`devicemake`, `hivesampletable`.`devicemodel`, `hivesampletable`.`state`, `hivesampletable`.`country`, `hivesampletable`.`querydwelltime`, `hivesampletable`.`sessionid`, `hivesampletable`.`sessionpagevieworder` from `default`.`hivesampletable` | NULL |
| Rewrite Enabled: | Yes | NULL |
| Outdated for Rewriting: | No | NULL |
+----------------------------------+----------------------------------------------------+----------------------------------------------------+
Known limitations:
- Support defining a CLUSTERED ON/DISTRIBUTED ON+SORTED ON specification for materialized views – HIVE-18842
- Creation on partitioned ACID materialized view. The data movement fails with error `Write id is not set in the config by open txn task for migration` – HIVE-21678
References:
https://cwiki.apache.org/confluence/display/Hive/Materialized+views
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.4/materialized-view/content/hive_alter_materialized_view_rebuild.html
https://cwiki.apache.org/confluence/display/Hive/StatsDev

Recent Comments