Cross region replication using Data-in replication with Azure Database for MySQL – Flexible Server
This article is contributed. See the original author and article here.
MySQL workloads are often read-heavy and support customers with operations in different geographical locations. To provide for Disaster Recovery (DR) in the rare event of a regional disaster, Azure Database for MySQL – Flexible Server offers Geo-restore. An alternate option for DR or read scaling across regions is to create an Azure Database for MySQL flexible server as the source server and then to replicate its data to a server in another region using Data-in replication. This set up helps improve the Recovery Time Objective (RTO) as compared to geo-restore and the Recovery Point Objective (RPO) will be equal to the replication lag between the primary server and the replica server.
Data-in replication, which is based on the binary log (binlog) file position, enables synchronization of data from one Azure Database for MySQL flexible service to another. To learn more about binlog replication, see MySQL binlog replication overview.
In this blog post, I’ll use mydumper/myloader and Data-in replication to create cross region replication from one Azure Database for MySQL flexible server to another in a different region, and then I’ll synchronize the data.
Prerequisites
To complete this tutorial, I need:
- A primary and secondary Azure Database for MySQL flexible server, one in each of two different regions, running either version 5.7 or 8.0 (it is recommended to have the same version running on the two servers. For more information, see Create an Azure Database for MySQL flexible server.
Note: Currently, this procedure is supported only on flexible servers that are not HA enabled.
- An Azure VM running Linux that can connect to both the primary and replica servers in different regions. The VM should have the following client tools installed.
- The . In this post, we’ll use the mysql client.
- mydumper/myloader. For more information about using mydumper/myloader, see https://centminmod.com/mydumper.html.
Tip: After setting up replication, this VM can be deleted.
- A sample database for testing the replication. Download mysqlsampledatabase.zip, and then run the included script on the primary server to create the sample classicmodels database.
- The binlog_expire_logs_seconds parameter on the primary server configured to ensure that binlogs aren’t purged before the replica commits the changes.
- The gtid_mode parameter set to same value on both the primary and replica servers. Configure this on the Server parameters page.
- Networking configured to ensure that primary server and replica server can communicate with each other.
- For Public access, on the Networking page, under Firewall rules, ensure that the primary server firewall allows connection from the replica server by verifying that the Allow public access from any Azure service…check box is selected. For more information, in the article Public Network Access for Azure Database for MySQL – Flexible Server, see Firewall rules.
- For Private access, ensure that the replica server can resolve the FQDN of the primary server and connect over the network. To accomplish this, use VNet peering or VNet-to-VNet VPN gateway connection.
Configure Data-in replication between the primary and replica servers
To configure Data-in replication, I’ll perform the following steps:
- On the Azure VM, use the mysql client tool to connect to the primary and replica servers.
- On the primary server, verify that log_bin is enabled by using the mysql client tool to run the following command:
SHOW VARIABLES LIKE 'log_bin';
3. On the source server, create a user with the replication permission by running the appropriate command, based on SSL enforcement.
If you’re using SSL, run the following command:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword';
GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%' REQUIRE SSL;
If you’re not using SSL, run the following command:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword';
GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%';
4. On the Azure VM, use mydumper to back up the primary server database by running the following command:
mydumper --host=<primary_server>.mysql.database.azure.com --user=<username> --password=<Password> --outputdir=./backup --rows=100 -G -E -R -z --trx-consistency-only --compress --build-empty-files --threads=16 --compress-protocol --ssl --regex '^(classicmodels.)' -L mydumper-logs.txt
–host: Name of the primary server
–user: Name of a user having permission to dump the database.
–password: Password of the user above
–trx-consistency-only: Required for transactional consistency during backup.
For more information about using mydumper, see mydumper/myloader.
5. Restore the database using myloader by running the following command:
myloader --host=<servername>.mysql.database.azure.com --user=<username> --password=<Password> --directory=./backup --queries-per-transaction=100 --threads=16 --compress-protocol --ssl --verbose=3 -e 2>myloader-logs.txt
–host: Name of the replica server.
–user: Name of a user. You can use server admin or a user with readwrite permission capable of restoring the schemas and data to the database.
–password: Password of the user above.
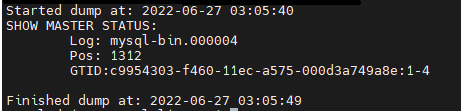
- Read the metadata file to determine the binary log file name and offset by running the following command:
cat ./backup/metadata
In this command, ./backup refers to the output directory specified in the command in the previous step.
The results should appear as shown in the following image:
- Depending on the SSL enforcement on the primary server, connect to the replica server using the mysql client tool, and then perform the following the steps.
If SSL enforcement is enabled, then:
a. Download the certificate needed to communicate over SSL with your Azure Database for MySQL server from here.
b. In Notepad, open the file, and then copy and paste the contents into the command below, replacing the text “PLACE PUBLIC KEY CERTIFICATE CONTEXT HERE“.SET @cert = ‘-----BEGIN CERTIFICATE----- PLACE PUBLIC KEY CERTIFICATE CONTEXT HERE -----END CERTIFICATE-----'
c. To configure Data-in replication, run the updated command above along with the following command to set @certCALL mysql.az_replication_change_master(‘<Primary_server>.mysql.database.azure.com’, ‘<username>’, ‘<Password>’, 3306, ‘<File_Name>’, <Position>, @cert);
If SSL enforcement isn’t enabled, then run the following command:
CALL mysql.az_replication_change_master(‘<Primary_server>.mysql.database.azure.com’, ‘<username>’, ‘<Password>’, 3306, ‘<File_Name>’, <Position>, ‘’);
–Primary_server: Name of the primary server
–username: Replica user created in step 4
–Password: Password of the replica user created in step 4
–File_Name and Position: From the information in step 7
8. On the replica server, to ensure that write traffic is not accepted, set the server parameter read_only to ON.
call mysql.az_replication_start;
- On the replica server, to ensure that write traffic is not accepted, set the server parameter read_only to ON.
Test the replication
On the replica server, to check the replication status, run the following command:
show slave status G;
In the results, if the state of Slave_IO_Running and Slave_SQL_Running shows “Yes” and Slave_IO_State is “Waiting for master to send event”, then replication is working well. You can also check Seconds_Behind_Master, which indicates how late the replica is. If the value is something other than 0, then the replica is still processing updates.
For more information on the output of the show slave status command, in the MySQL documentation, see SHOW SLAVE STATUS Statement.
For details on troubleshooting replication, see the following resources:
- Troubleshoot replication latency – Azure Database for MySQL
- Troubleshooting Replication latency in Azure Database for MySQL
- Troubleshooting Problems With MySQL Replication
Optional
To confirm that cross region is working properly, you can verify that the changes to the tables in primary have been replicated to the replica.
- Identify a table to use for testing, for example the Customers table, and then confirm that it contains the same number of entries on both the primary and replica servers by running the following command on each server:
select count(*) from customers;
- Make a note of the count of entries in each table for later comparison.
To confirm that replication is working properly, on the primary server, add some data to the Customer table. Next, run the select count command each of the primary and replica servers to verify that the entry count on the replica server has increased to match the entry count on the primary server.
Note: For more information about how to monitor Data-in replication and create alerts for potential replication failures, see Monitoring and creating alerts for Data-in replication with Azure Database for MySQL-Flexible Server.
Conclusion
We’ve now set up replication between Azure Database for MySQL flexible servers in two different regions. Any changes to primary instance in one region will be replicated to the server in the other region by using the native replication technique. Take advantage of this solution to scale read workloads or to address DR considerations for potential regional disasters.
If you have any feedback or questions about the information provided above, please leave a comment below or email us at AskAzureDBforMySQL@service.microsoft.com. Thank you!


Recent Comments