This article is contributed. See the original author and article here.
To run a digital contact center effectively, supervisors need up-to-the-minute insights on all the activity between agents and customers. With new enhancements to Microsoft Dynamics 365 Customer Service, it’s easier than ever to find and customize the historical analytics you need to identify key areas for improvement. Last month, we released four new features that will change the way you view Customer Service data:
Unified reporting across Power Virtual Agents and Omnichannel
Bookmarks for frequently used reports
Contact center operations monitoring in near real-time (preview)
Data model customization (preview)
Unified reporting of customer service data across Power Virtual Agents and Omnichannel
As a contact center supervisor, you need to know how your customers are navigating the support funnel. This information helps you take corrective steps at each leg of the customer journey to increase customer satisfaction and reduce cost. When customer journey data is fragmented across different applications, it’s hard to understand what actions to take to improve.
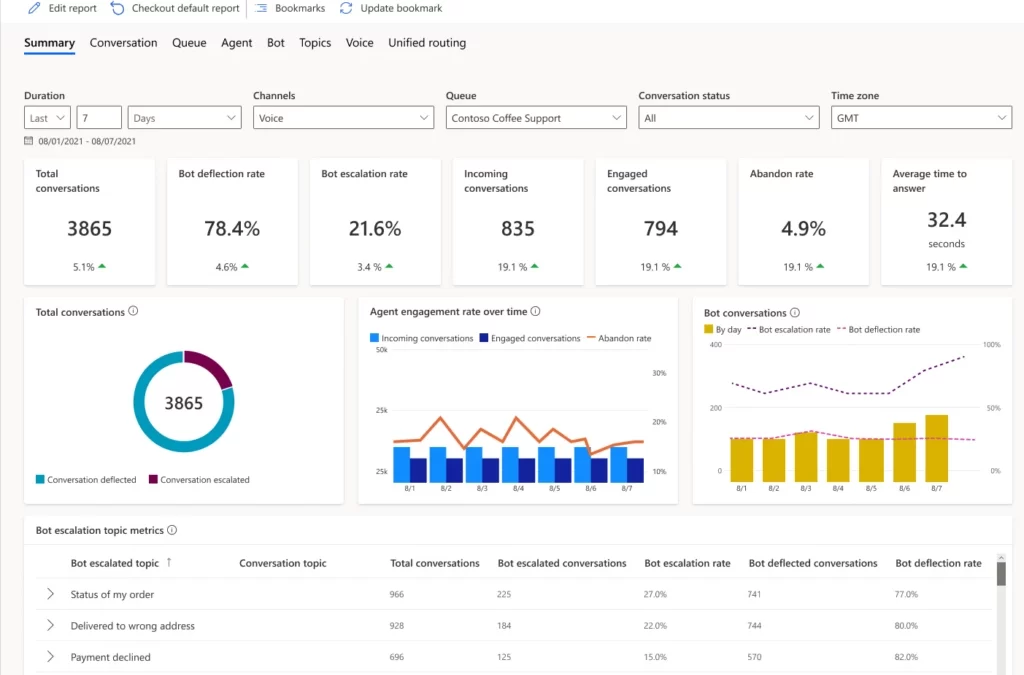
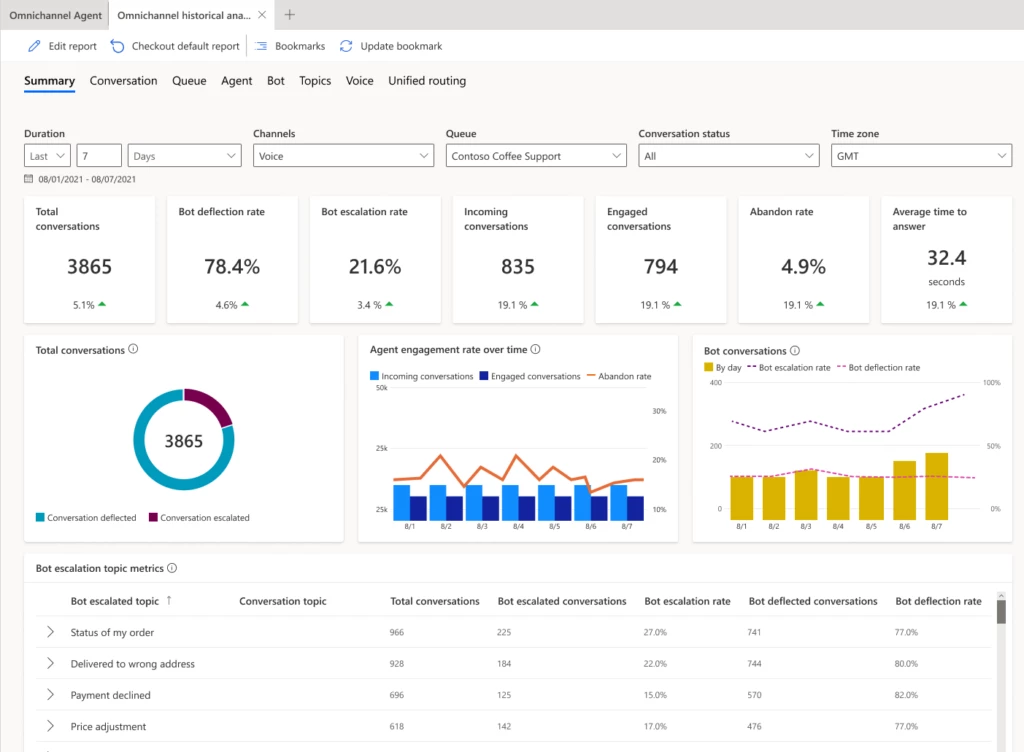
Dynamics 365 Customer Service now provides a unified report with Power Virtual Agents and Omnichannel analytics. You can easily monitor escalations from bots to human agents. These integrated insights help you more efficiently handle case volumes. Revise Power Virtual Agents bots based on the agent resolution steps of escalated conversations to increase the deflection rate.
The Omnichannel Summary dashboard provides integrated analytics. You’ll find key metrics across Power Virtual Agents and agent conversations across channels. Use the Omnichannel Bot dashboard to see detailed bot session-level metrics and identify why the conversation was escalated to a human agent.
You can also drill down into specific bot pages and view topic-specific metrics. Make changes to the bot to enhance its performance, including modifying the topic name and trigger phrases and adding more trigger phrases if needed.
Bookmarks for frequently used customer service data reports
Bookmark frequently used out-of-the-box historical analytics reports to personalize your workspace. You can set a default bookmark that will be loaded every time you start a new session. Navigate between bookmarks in the bookmarks side panel, update the corresponding report with filters, and delete bookmarks you no longer need.
Contact center operations monitoring in near real-time (preview)
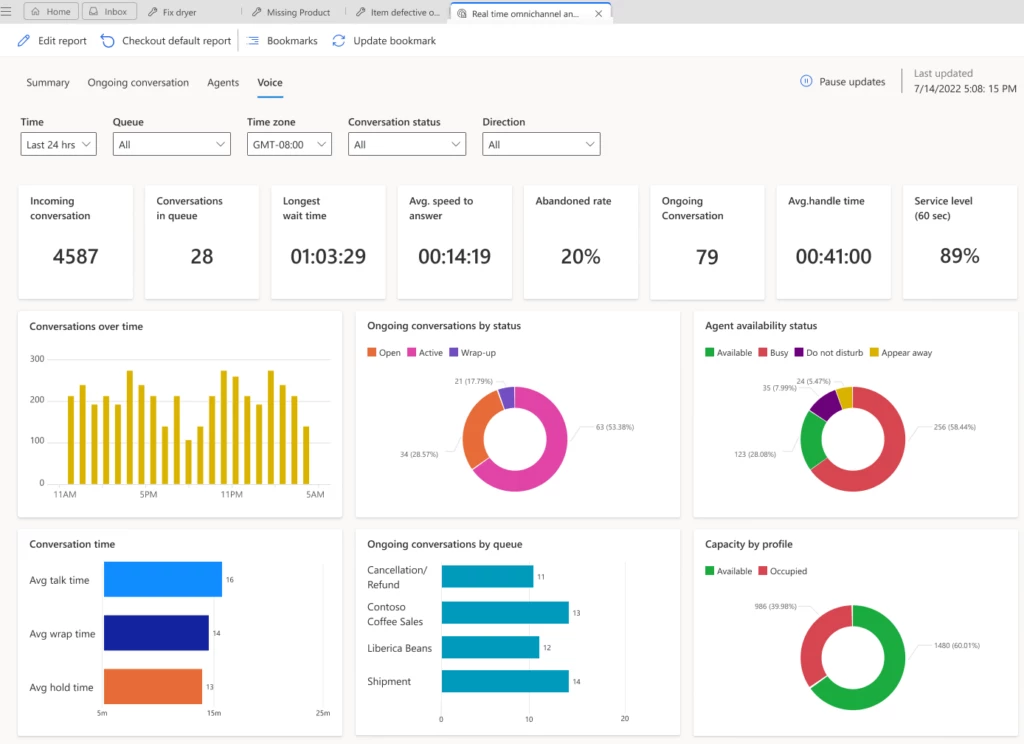
One of the biggest challenges supervisors face is the constantly changing nature of the digital contact center. You must handle everything from spikes in incoming customer requests to new agent training to unexpected absences in your workforce. With near real-time visibility into your overall support organization, you can make quick decisions and allocate your agents appropriately.
Using four new reports, you can monitor the volume of customer interactions, wait time, and other key metrics across multiple channels. Reports automatically refresh in real-time. However, you can pause the process to analyze the metrics and then resume automatic refresh when you’re finished. Near real-time analytics are in the following reports:
Summary report: View key performance indicators (KPIs) across the volume of customer interactions and service levels, along with the available capacity. You can filter metrics by time, channels, queue, time zone, or conversation status.
Ongoing conversation report: View a list of all current conversations along with the wait time and handle time, and drill down to the conversation form.
Agents report: View agent performance across all channels or a single channel. You can also see the current agent capacity and what each agent is working on, with detailed metrics for each agent.
Voice report: Shows key metrics across the voice channel, if the voice channel is configured in your Omnichannel environment. You can filter metrics by time, queue, time zone, conversation status, or direction.
Digital contact centers have diverse needs and goals, so they need metrics that are relevant to their industry and business. When out-of-the-box metrics don’t fit your unique business needs, you might build a separate analytics infrastructure to integrate and store your data. This leads to higher overhead and maintenance costs.
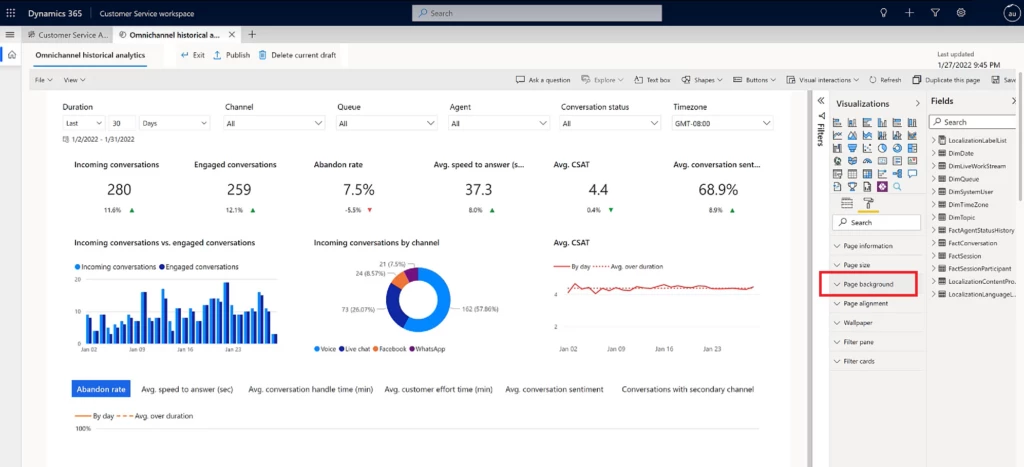
With data model customization, administrators can extend the out-of-the-box Customer Service Power BI data model. To track what matters most to your business, add new custom metrics, custom entities from Dataverse or any other data source, or integrate with an external data set. Customized reports can be embedded in the Customer Service workspace application.
Report authors can also customize fields containing measurements and attributes, and visualizations such as filters, page size, and page background.
By extending out-of-the-box analytics available natively in Dynamics 365 Customer Service, every organization can handle its unique business requirements in a fraction of the time instead of reengineering and maintaining costly data warehouses.
This article is contributed. See the original author and article here.
TheAzure Well-Architected Framework (WAF) helps ensure that Azure workloads are reliable, stable, and secure while meeting SLAs for performance and cost. The WAF tenets are:
Security– Protecting applications and data from threats.
Applying the Azure WAF to your Azure Data Factory (ADF) workloads is critical and should be considered during initial architecture design and resource deployment. If you haven’t already, check out this companion blog on Azure Data Factory Patterns and Features for the Azure Well-Architected Framework. But how do you ensure that your ADF environment still meets WAF as workloads grow and evolve?
All Azure resources offer the capability to build dashboards over costs, but don’t necessarily give you the detail needed or have the alerting capabilities when an issue arises. You can view pipeline activity within the Data Factory itself, but this does not allow you to create aggregated reports over activities and pipelines over time.
Create alerts over ADF metrics, leverage Azure Monitor and Log Analytics for detailed and/or summarized information about your Data Factory activities and/or create your own notification framework within Data Factory, helping your Data Factories to continue to be optimized for cost, performance and reliability.
Using metrics and alerts in Data Factory
Metrics are essentially performance counters, always returning a number, and are leveraged when you configure alerts.
Configure alerts for failures
Configure ADF metrics and alerts to send notifications when triggers, pipelines, activities or SSIS packages fail. In the example below, an alert will be issued whenever the activity name “cdCopyTextToSQL” fails:
If the pipeline runtime exceeds the duration defined in the Elapsed time metric Pipeline Settings, an alert will be issued.
Set Alerts on Self-Hosted Integration Runtimes
Self-Hosted Integration Runtimes (SHIRs) are used to move and transform data that resides in an on-premises network or VNet. Set alerts to ensure resources are not overutilized or queuing data movement requests:
The following metrics are available:
Integration runtime available memory (IntegrationRuntimeAvailableMemory) – be notified when there are any dips in available memory
Integration runtime available node count (IntegrationRuntimeAvailableNodeNumber) – be notified when nodes in a SHIR cluster are not available or not being fully utilized
Integration runtime CPU Utilization (IntegrationRuntimeCpuPercentage) – be notified when there are spikes in CPU or when CPU is being maxed out
Integration runtime queue duration (IntegrationRuntimeAverageTaskPickupDelay) – be notified when the average activity queue duration exceeds a limit
Integration runtime queue length (IntegrationRuntimeQueueLength) – be notified when there are long waits between activities
ADF has resources limits per Azure subscription. If you expect a Data Factory will have a large number of pipelines, datasets, triggers, linked services, private endpoints and other entities, set alerts on the count of Total entities to be notified when Data Factories start approaching the limit (Default Limit is 5000). For example:
You can also set an alert or query on Total factory size (GB unit) to ensure the Data Factory will not exceed the data factory size limit (2 GB default).
Leveraging alerts in ADF allows you to be immediately notified when pipelines are failing or when resources are reaching their limits, supporting WAF tents of Cost Optimization, Reliability, Operational Excellence, and Performance Efficiency.
Use Azure Monitor with Log Analytics over Data Factory
Azure Monitor provides verbose information about your ADF triggers, pipelines, and activities for further analysis.
Add diagnostic settings
Add diagnostic settings to your Data Factory, enabling Azure Monitor to provide detailed information such as activity duration, trends, and failure information.
Send this data to Log Analytics to query in with the Kusto Query Language(KQL), build Azure workbooks from KQL queries, or export to Power BI for further transformation and analysis.
(In my Data Factories, I do not use SSIS therefore I do not have them configured.)
Explore logs with KQL
In the Azure Portal for the Data Factory where you configured the diagnostic settings, go to Monitoring -> Logs to query the corresponding Log Analytics tables containing the run information about my Data Factory:
Detailed Failure Information
Run queries to get detailed information or aggregated information around failures, as in the example below:
ADFActivityRun
| where Status == 'Failed'
| project ActivityName, TimeGenerated, Error, Input, Output
Extrapolate costs for orchestration
Costs in Azure Data Factory are based upon Usage. Costs are based upon the number of activities run or triggered, the type of Integration Runtime (IR) used, the number of cores used in an IR, and the type of activity. Get the latest pricing details here
Calculations for Orchestration activities are simple: sum up the number of failed or successful activities (ADFActivityRun) plus the number of triggers executed (ADFTriggerRun) plus the number of debug runs (ADFSandboxPipelineRun). The table below summarizes the cost per 1000 runs (as of 11/14/2022):
Activity Type
Azure IR
VNet Managed IR
Self-Hosted IR
Orchestration
$1/1000 Runs
$1/1000 Runs
$1.50/1000 Runs
Here’s a sample query to the number of activity runs, where you can apply the cost per IR:
ADFActivityRun
| where Status != "Queued" and Status != "InProgress"
| where EffectiveIntegrationRuntime != ""
| summarize count() by EffectiveIntegrationRuntime
Costs are also accrued based upon the type of activity, the activity run duration, and the Integration Runtime used. This data is available in the ADFActivityRun table. Below are the cost details for pipeline activities by IR (for West US 2, as of 11/14/2022):
Activity Type
Azure IR
VNet Managed IR
Self-Hosted IR
Data movement activities
$0.25/DIU-hour
$0.25/DIU-hour
$0.10/hour
Pipeline activities
$0.005/hour
$1/hour
$0.002/hour
External pipeline activities
$0.00025/hour
$1/hour
$0.0001/hour
The example query below derives the elements highlighted above that contribute to the Activity cost:
ADFActivityRun
| where Status != "Queued" and Status != "InProgress"
| project ActivityJson = parse_json(Output)
| project billing = parse_json(ActivityJson.billingReference.billableDuration[0]), ActivityType = parse_json(ActivityJson.billingReference.activityType)
| where ActivityType =="PipelineActivity"
| evaluate bag_unpack(billing)
| project duration, meterType, unit
Dataflow activity costs are based upon whether the cluster is General Purpose or Memory optimized as well as the data flow run duration (Cost as of 11/14/2022 for West US 2):
General Purpose
Memory Optimized
$0.274 per vCore-hour
$0.343 per vCore-hour
Here’s an example query to get elements for Dataflow costs:
ADFActivityRun
| where Status != "Queued" and Status != "InProgress" and ActivityType =="ExecuteDataFlow"
| project ActivityJson = parse_json(Output), InputJSon = parse_json(Input)
| project billing = parse_json(ActivityJson.billingReference.billableDuration[0]), compute = parse_json(InputJSon.compute)
| evaluate bag_unpack(billing)
| evaluate bag_unpack(compute)
Costs on Data Factory operations are also incurred, but these are generally insignificant (costs as of 11/14/2022, US West 2):
Some organizations prefer to build their own monitoring platform, extracting pipeline input, output, or error information to SQL or their data platform of choice. You can also send email notificationswhen an activity fails.
Monitoring your data factories, whether it is with the built-in features of Azure Metrics, Azure Monitor and Log Analytics or through your own auditing framework, helps ensure your workloads continue to be optimized for cost, performance and reliability to meet the tenets of the WAF. New features are continually added to Azure Data Factory and new ideas evolve as well. Please post your comments and feedback with other features or patterns that have helped you monitor your data factories!
This article is contributed. See the original author and article here.
Summary
Actions to Take Today to Mitigate Cyber Threats from Ransomware:
• Prioritize remediating known exploited vulnerabilities. • Enable and enforce multifactor authentication with strong passwords • Close unused ports and remove any application not deemed necessary for day-to-day operations.
Note: This joint Cybersecurity Advisory (CSA) is part of an ongoing #StopRansomware effort to publish advisories for network defenders that detail various ransomware variants and ransomware threat actors. These #StopRansomware advisories include recently and historically observed tactics, techniques, and procedures (TTPs) and indicators of compromise (IOCs) to help organizations protect against ransomware. Visit stopransomware.gov to see all #StopRansomware advisories and to learn more about other ransomware threats and no-cost resources.
The Federal Bureau of Investigation (FBI), the Cybersecurity and Infrastructure Security Agency (CISA), and the Department of Health and Human Services (HHS) are releasing this joint CSA to disseminate known Hive IOCs and TTPs identified through FBI investigations as recently as November 2022.
FBI, CISA, and HHS encourage organizations to implement the recommendations in the Mitigations section of this CSA to reduce the likelihood and impact of ransomware incidents. Victims of ransomware operations should report the incident to their local FBI field office or CISA.
Download the PDF version of this report: pdf, 852.9 kb.
For a downloadable copy of IOCs, see AA22-321A.stix (STIX, 43.6 kb).
Technical Details
Note: This advisory uses the MITRE ATT&CK® for Enterprise framework, version 12. See MITRE ATT&CK for Enterprise for all referenced tactics and techniques.
As of November 2022, Hive ransomware actors have victimized over 1,300 companies worldwide, receiving approximately US$100 million in ransom payments, according to FBI information. Hive ransomware follows the ransomware-as-a-service (RaaS) model in which developers create, maintain, and update the malware, and affiliates conduct the ransomware attacks. From June 2021 through at least November 2022, threat actors have used Hive ransomware to target a wide range of businesses and critical infrastructure sectors, including Government Facilities, Communications, Critical Manufacturing, Information Technology, and especially Healthcare and Public Health (HPH).
The method of initial intrusion will depend on which affiliate targets the network. Hive actors have gained initial access to victim networks by using single factor logins via Remote Desktop Protocol (RDP), virtual private networks (VPNs), and other remote network connection protocols [T1133]. In some cases, Hive actors have bypassed multifactor authentication (MFA) and gained access to FortiOS servers by exploiting Common Vulnerabilities and Exposures (CVE) CVE-2020-12812. This vulnerability enables a malicious cyber actor to log in without a prompt for the user’s second authentication factor (FortiToken) when the actor changes the case of the username.
Hive actors have also gained initial access to victim networks by distributing phishing emails with malicious attachments [T1566.001] and by exploiting the following vulnerabilities against Microsoft Exchange servers [T1190]:
CVE-2021-31207 – Microsoft Exchange Server Security Feature Bypass Vulnerability
CVE-2021-34473 – Microsoft Exchange Server Remote Code Execution Vulnerability
CVE-2021-34523 – Microsoft Exchange Server Privilege Escalation Vulnerability
After gaining access, Hive ransomware attempts to evade detention by executing processes to:
Identify processes related to backups, antivirus/anti-spyware, and file copying and then terminating those processes to facilitate file encryption [T1562].
Stop the volume shadow copy services and remove all existing shadow copies via vssadmin on command line or via PowerShell [T1059] [T1490].
Delete Windows event logs, specifically the System, Security and Application logs [T1070].
Prior to encryption, Hive ransomware removes virus definitions and disables all portions of Windows Defender and other common antivirus programs in the system registry [T1112].
Hive actors exfiltrate data likely using a combination of Rclone and the cloud storage service Mega.nz [T1537]. In addition to its capabilities against the Microsoft Windows operating system, Hive ransomware has known variants for Linux, VMware ESXi, and FreeBSD.
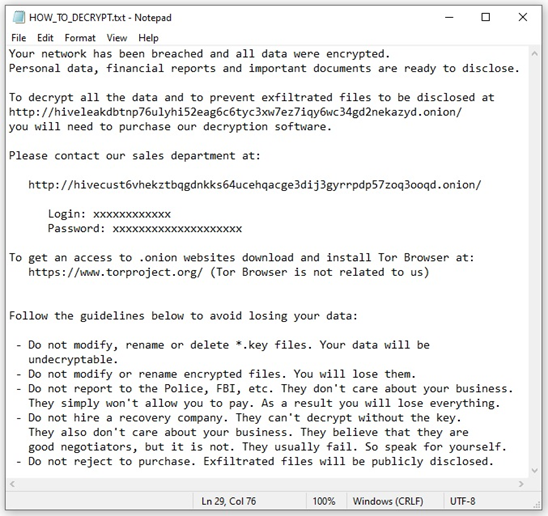
During the encryption process, a file named *.key (previously *.key.*) is created in the root directory (C: or /root/). Required for decryption, this key file only exists on the machine where it was created and cannot be reproduced. The ransom note, HOW_TO_DECRYPT.txt is dropped into each affected directory and states the *.key file cannot be modified, renamed, or deleted, otherwise the encrypted files cannot be recovered [T1486]. The ransom note contains a “sales department” .onion link accessible through a TOR browser, enabling victim organizations to contact the actors through a live chat panel to discuss payment for their files. However, some victims reported receiving phone calls or emails from Hive actors directly to discuss payment.
The ransom note also threatens victims that a public disclosure or leak site accessible on the TOR site, “HiveLeaks”, contains data exfiltrated from victim organizations who do not pay the ransom demand (see figure 1 below). Additionally, Hive actors have used anonymous file sharing sites to disclose exfiltrated data (see table 1 below).
Figure 1: Sample Hive Ransom Note
Table 1: Anonymous File Sharing Sites Used to Disclose Data
Once the victim organization contacts Hive actors on the live chat panel, Hive actors communicate the ransom amount and the payment deadline. Hive actors negotiate ransom demands in U.S. dollars, with initial amounts ranging from several thousand to millions of dollars. Hive actors demand payment in Bitcoin.
Hive actors have been known to reinfect—with either Hive ransomware or another ransomware variant—the networks of victim organizations who have restored their network without making a ransom payment.
Indicators of Compromise
Threat actors have leveraged the following IOCs during Hive ransomware compromises. Note: Some of these indicators are legitimate applications that Hive threat actors used to aid in further malicious exploitation. FBI, CISA, and HHS recommend removing any application not deemed necessary for day-to-day operations. See tables 2–3 below for IOCs obtained from FBI threat response investigations as recently as November 2022.
Table 2: Known IOCs as of November 2022
Known IOCs – Files
HOW_TO_DECRYPT.txt typically in directories with encrypted files
*.key typically in the root directory, i.e., C: or /root
hive.bat
shadow.bat
asq.r77vh0[.]pw – Server hosted malicious HTA file
asq.d6shiiwz[.]pw – Server referenced in malicious regsvr32 execution
asq.swhw71un[.]pw – Server hosted malicious HTA file
asd.s7610rir[.]pw – Server hosted malicious HTA file
Windows_x64_encrypt.dll
Windows_x64_encrypt.exe
Windows_x32_encrypt.dll
Windows_x32_encrypt.exe
Linux_encrypt
Esxi_encrypt
Known IOCs – Events
System, Security and Application Windows event logs wiped
Microsoft Windows Defender AntiSpyware Protection disabled
Microsoft Windows Defender AntiVirus Protection disabled
Table 3: Potential IOC IP Addresses as of November 2022
Note: Some of these observed IP addresses are more than a year old. FBI and CISA recommend vetting or investigating these IP addresses prior to taking forward-looking action like blocking.
Hive actors gain access to victim network by exploiting the following Microsoft Exchange vulnerabilities: CVE-2021-34473, CVE-2021-34523, CVE-2021-31207, CVE-2021-42321.
Hive actors deploy a ransom note HOW_TO_DECRYPT.txt into each affected directory which states the *.key file cannot be modified, renamed, or deleted, otherwise the encrypted files cannot be recovered.
Hive actors looks to stop the volume shadow copy services and remove all existing shadow copies via vssadmin via command line or PowerShell.
Mitigations
FBI, CISA, and HHS recommend organizations, particularly in the HPH sector, implement the following to limit potential adversarial use of common system and network discovery techniques and to reduce the risk of compromise by Hive ransomware:
Verify Hive actors no longer have access to the network.
Install updates for operating systems, software, and firmware as soon as they are released. Prioritize patching VPN servers, remote access software, virtual machine software, and known exploited vulnerabilities. Consider leveraging a centralized patch management system to automate and expedite the process.
Require phishing-resistant MFA for as many services as possible—particularly for webmail, VPNs, accounts that access critical systems, and privileged accounts that manage backups.
If used, secure and monitor RDP.
Limit access to resources over internal networks, especially by restricting RDP and using virtual desktop infrastructure.
After assessing risks, if you deem RDP operationally necessary, restrict the originating sources and require MFA to mitigate credential theft and reuse.
If RDP must be available externally, use a VPN, virtual desktop infrastructure, or other means to authenticate and secure the connection before allowing RDP to connect to internal devices.
Monitor remote access/RDP logs, enforce account lockouts after a specified number of attempts to block brute force campaigns, log RDP login attempts, and disable unused remote access/RDP ports.
Be sure to properly configure devices and enable security features.
Disable ports and protocols not used for business purposes, such as RDP Port 3389/TCP.
Maintain offline backups of data, and regularly maintain backup and restoration. By instituting this practice, the organization ensures they will not be severely interrupted, and/or only have irretrievable data.
Ensure all backup data is encrypted, immutable (i.e., cannot be altered or deleted), and covers the entire organization’s data infrastructure. Ensure your backup data is not already infected.,
Monitor cyber threat reporting regarding the publication of compromised VPN login credentials and change passwords/settings if applicable.
Install and regularly update anti-virus or anti-malware software on all hosts.
Enable PowerShell Logging including module logging, script block logging and transcription.
Install an enhanced monitoring tool such as Sysmon from Microsoft for increased logging.
Review the following additional resources.
The joint advisory from Australia, Canada, New Zealand, the United Kingdom, and the United States on Technical Approaches to Uncovering and Remediating Malicious Activity provides additional guidance when hunting or investigating a network and common mistakes to avoid in incident handling.
The Cybersecurity and Infrastructure Security Agency-Multi-State Information Sharing & Analysis Center Joint Ransomware Guide covers additional best practices and ways to prevent, protect, and respond to a ransomware attack.
StopRansomware.gov is the U.S. Government’s official one-stop location for resources to tackle ransomware more effectively.
If your organization is impacted by a ransomware incident, FBI, CISA, and HHS recommend the following actions.
Isolate the infected system. Remove the infected system from all networks, and disable the computer’s wireless, Bluetooth, and any other potential networking capabilities. Ensure all shared and networked drives are disconnected.
Turn off other computers and devices. Power-off and segregate (i.e., remove from the network) the infected computer(s). Power-off and segregate any other computers or devices that share a network with the infected computer(s) that have not been fully encrypted by ransomware. If possible, collect and secure all infected and potentially infected computers and devices in a central location, making sure to clearly label any computers that have been encrypted. Powering-off and segregating infected computers and computers that have not been fully encrypted may allow for the recovery of partially encrypted files by specialists.
Secure your backups. Ensure that your backup data is offline and secure. If possible, scan your backup data with an antivirus program to check that it is free of malware.
In addition, FBI, CISA, and HHS urge all organizations to apply the following recommendations to prepare for, mitigate/prevent, and respond to ransomware incidents.
Preparing for Cyber Incidents
Review the security posture of third-party vendors and those interconnected with your organization. Ensure all connections between third-party vendors and outside software or hardware are monitored and reviewed for suspicious activity.
Implement listing policies for applications and remote access that only allow systems to execute known and permitted programs under an established security policy.
Document and monitor external remote connections. Organizations should document approved solutions for remote management and maintenance, and immediately investigate if an unapproved solution is installed on a workstation.
Implement a recovery plan to maintain and retain multiple copies of sensitive or proprietary data and servers in a physically separate, segmented, and secure location (i.e., hard drive, storage device, the cloud).
Refrain from requiring password changes more frequently than once per year unless a password is known or suspected to be compromised. Note: NIST guidance suggests favoring longer passwords instead of requiring regular and frequent password resets. Frequent password resets are more likely to result in users developing password “patterns” cyber criminals can easily decipher.
Require administrator credentials to install software.
Require phishing-resistant multifactor authentication for all services to the extent possible, particularly for webmail, virtual private networks, and accounts that access critical systems.
Review domain controllers, servers, workstations, and active directories for new and/or unrecognized accounts.
Audit user accounts with administrative privileges and configure access controls according to the principle of least privilege.
Implement time-based access for accounts set at the admin level and higher. For example, the Just-in-Time (JIT) access method provisions privileged access when needed and can support enforcement of the principle of least privilege (as well as the Zero Trust model). This is a process where a network-wide policy is set in place to automatically disable admin accounts at the Active Directory level when the account is not in direct need. Individual users may submit their requests through an automated process that grants them access to a specified system for a set timeframe when they need to support the completion of a certain task.
Protective Controls and Architecture
Segment networks to prevent the spread of ransomware. Network segmentation can help prevent the spread of ransomware by controlling traffic flows between—and access to—various subnetworks and by restricting adversary lateral movement.
Identify, detect, and investigate abnormal activity and potential traversal of the indicated ransomware with a networking monitoring tool. To aid in detecting the ransomware, implement a tool that logs and reports all network traffic, including lateral movement activity on a network. Endpoint detection and response (EDR) tools are particularly useful for detecting lateral connections as they have insight into common and uncommon network connections for each host.
Install, regularly update, and enable real time detection for antivirus software on all hosts.
Vulnerability and Configuration Management
Consider adding an email banner to emails received from outside your organization.
Disable command-line and scripting activities and permissions. Privilege escalation and lateral movement often depend on software utilities running from the command line. If threat actors are not able to run these tools, they will have difficulty escalating privileges and/or moving laterally.
Ensure devices are properly configured and that security features are enabled.
Restrict Server Message Block (SMB) Protocol within the network to only access necessary servers and remove or disable outdated versions of SMB (i.e., SMB version 1). Threat actors use SMB to propagate malware across organizations.
REFERENCES
INFORMATION REQUESTED
The FBI, CISA, and HHS do not encourage paying a ransom to criminal actors. Paying a ransom may embolden adversaries to target additional organizations, encourage other criminal actors to engage in the distribution of ransomware, and/or fund illicit activities. Paying the ransom also does not guarantee that a victim’s files will be recovered. However, the FBI, CISA, and HHS understand that when businesses are faced with an inability to function, executives will evaluate all options to protect their shareholders, employees, and customers. Regardless of whether you or your organization decide to pay the ransom, the FBI, CISA, and HHS urge you to promptly report ransomware incidents to your local FBI field office, or to CISA at report@cisa.gov or (888) 282-0870. Doing so provides investigators with the critical information they need to track ransomware attackers, hold them accountable under US law, and prevent future attacks.
The FBI may seek the following information that you determine you can legally share, including:
Recovered executable files
Live random access memory (RAM) capture
Images of infected systems
Malware samples
IP addresses identified as malicious or suspicious
Email addresses of the attackers
A copy of the ransom note
Ransom amount
Bitcoin wallets used by the attackers
Bitcoin wallets used to pay the ransom
Post-incident forensic reports
DISCLAIMER
The information in this report is being provided “as is” for informational purposes only. FBI, CISA, and HHS do not endorse any commercial product or service, including any subjects of analysis. Any reference to specific commercial products, processes, or services by service mark, trademark, manufacturer, or otherwise, does not constitute or imply endorsement, recommendation, or favoring by FBI, CISA, or HHS.
The guidance released today, along with its accompanying fact sheet, provides recommended practices for software customers to ensure the integrity and security of software during the procuring and deployment phases.
The Securing Software Supply Chain Series is an output of the Enduring Security Framework (ESF), a public-private cross-sector working group led by NSA and CISA. This series complements other U.S. government efforts underway to help the software ecosystem secure the supply chain, such as the software bill of materials (SBOM) community.















Recent Comments