This article is contributed. See the original author and article here.
Microsoft aims to make mixed reality accessible and intuitive for frontline workers everywhere. With Dynamics 365 Guides, deskless workers use step-by-step holographic instructions to ensure process compliance, improve efficiency, and learn on the job. In 2022, new Microsoft Teams capabilities in Guides combined anyone, anywhere, seamless collaboration with the “see what I see” magic of HoloLens 2. In real-time, participants on a call could see what the HoloLens user saw, annotate their colleague’s three-dimensional space, and share files easily. We’ve just released another set of features in Guides to make this new experience even more intuitive and reliable.
Draw anywhere with digital 3Dannotations
Imagine being able to draw on any object, any surface, or in thin air. With our recent annotation improvements, you can. Previously, a HoloLens user could only draw on a flat or semi-flat surface some way off in the distance. Now HoloLens users can draw 3D images anywhere using digital inkand in Dynamics 365 Guides and Remote Assist, an expert working on a PC or mobile device on the other side of the world can draw in your world in 3D.
These drawings stick where they’re placed in the space and remain still. Users can walk around them and view them from different angles. On surfaces, the digital ink stays where intended, regardless of whether the user changes location or position. With HoloLens, the entire world is inkable, allowing you to annotate and share in real time.
Join mixed reality Teams calls more securely
In Dynamics 365 Guides, HoloLens users now have more options when joining a Teams call. Before entering the call, you can turn video on or off and join muted or not. As before, you can also change these settings once you’re in the meeting. In spaces where confidentiality is core, this allows frontline workers to use HoloLens as their main calling devicewithout compromising on security.
Further driving our efforts to help you keep your company and your information secure, we also recently added restricted mode features that enable your admin to restrict who can log on to the device and make calls.
Link to Guides from inside a Guide
Navigating through the steps of a guide is as intuitive as paging through a document or scrolling through a file. What about jumping from one file to another? You can do that now, too. We’ve added the ability to navigate directly from one guide to another by linking the second guide in an action step. Navigating between different sets of training materials or guides is as easy as jumping to a new web page from a hyperlink.
What’s next?
Learn the details of all our recent additions in the Dynamics 365 Guides release notes.
Stay tuned for more updates coming soon as we continue to build on the intuitive and frontline worker-focused features in Dynamics 365 Guides!
This article is contributed. See the original author and article here.
Migrating databases. When your databases anchor applications, employees, and customers, migration plunks a big rock in the pond that is your business, creating lasting ripples. Ripples that force thoughtful, coordinated action across business units to prevent outages. Add moving to the cloud into the equation and the potential tide of complications rises.
In the past, undertaking migration often required you to refactor your databases to make them compatible with cloud database servers. Security policies needed thorough analysis and updating for cloud models. Factor in potential downtimes, and migration once loomed as a labor-intensive hit to business productivity. This made migrating an on-premises SQL Server to the cloud an ROI evaluation against the once heavy-lift tradeoffs required by moving to the cloud.
Azure SQL Managed Instance eliminates these tradeoffs with the broadest SQL Server engine compatibility offering available. Because of the compatibility level, Azure SQL Managed Instance doesn’t require you to compromise much, if anything, to deploy SQL Server within a fully managedaPlatform as a Service (PaaS) environment. Because the SQL Server 2022 Enterprise Edition and Azure SQL Managed Instance engines are almost one hundred percent identical, making it possible to migrate both ways. You don’t need to refactor databases or risk negative performance impacts to migrate to Azure SQL Managed Instance. Azure SQL Managed Instance is also compatible with earlier SQL Server editions.
Additionally, the storage engine format alignment between Azure SQL Managed Instance and SQL Server 2022 provides an easy way to copy or move databases from Azure SQL Managed Instance to a SQL Server 2022 instance. A back up from Azure SQL Managed Instance can be restored on SQL Server 2022. The standalone SQL Server can be hosted on-premises, on virtual machines in Azure, or in other clouds. This puts you in control of your data, ensuring data mobility regardless of SQL Server location.
Compatibility between the Azure SQL Managed Instance and SQL Server 2022 engines extends to the database engine settings and the database settings. As with the standalone version of SQL Server, with Azure SQL Managed Instance, you decide what server configuration best serves your business needs. To get started with Azure SQL Managed Instance, you choose the performance tier, service tier, and the reserved compute, along with data and backup storage options, that make the most sense for your applications and your data.
Since Azure SQL Managed Instance is built on the latest SQL Server engine, it’s always up to date with the latest features and functionality, including online operations, automatic plan corrections, and other enterprise performance enhancements. A comparison of the available features is explained in Feature comparison: Azure SQL Managed Instance versus SQL Server.
Azure SQL Managed Instance offers two performance tiers:
General purpose - for applications with typical performance, I/O latency requirements, and built-in High Availability (HA).
Business Critical - for applications requiring low I/O latency and higher HA requirements. It provides two non-readable secondaries and one readable secondary along with the readable/writable primary replica. The readable secondary allows you to distribute reporting workloads off your primary.
Once you’re running on Azure SQL Managed Instance, changing your service tier (CPU vCores or reserved storage changes) occurs online and incurs little to no downtime. To optimize performance of transaction processing, data ingestion, data load, and transient data, leverage In-Memory OLTP, available in the Business Critical tier.
Migrate from your on-premises SQL Server to Azure SQL Managed Instance with ease. Leverage the fully automated Azure Data Migration Service or set up an Azure SQL Managed Instance link. The link feature uses an expanded version of distributed availability groups to extend your on-prem SQL Server availability group to Azure SQL Managed Instance safely, replicating data in near real-time. With Azure SQL Managed Instance link feature, you can migrate, test, and then perform a simple, controlled fail-over.
While Azure SQL Managed Instance provides nearly one hundred percent compatibility with SQL Server, you will notice some changes in the transition from SQL Server standalone editions. These differences are based on architectural dissimilarities. Certain SQL features (audits, for instance) operate in a fashion that optimizes cloud architecture. Cloud architecture is designed to maximize resource utilization and minimize costs while ensuring high levels of availability, reliability, and security. Azure architecture leverages resource sharing while guaranteeing security and isolation. This resource sharing provides you with a flexible environment that can scale rapidly in response to customer needs. Because high availability is built into Azure SQL Managed Instance, it cannot be configured or controlled by users as it can be in SQL Server 2022.
What’s more, Azure SQL Managed Instance is backed by Intel® Xeon® Scalable processors, ensuring that your environment is performant and secure from the silicon layer. With 8 to 40 powerful cores and a wide range of frequency, feature, and power levels Intel® Xeon® Scalable processors are a part of an end-to-end solution for your data.
Come delve into Azure SQL Server Managed Instance. The depth and breadth of SQL engine compatibility provides you with a safe, simple, full-featured, and flexible migration path. Azure SQL Managed Instance puts you in complete control of your data, your databases, your performance, and your business. Microsoft’s continued commitment to improvement means you can take advantage of the benefits of the cloud with Azure SQL Managed Instance and modernize your on-premises SQL Server databases.
This article is contributed. See the original author and article here.
Modern applications require the capability to retrieve modified data from a database in real time to operate effectively. Usually, developers need to create a customized tracking mechanism in their applications, utilizing triggers, timestamp columns, and supplementary tables, to identify changes in data. The development of such applications typically requires significant effort and can result in schema updates resulting in considerable performance overhead.
Real-time data processing is a crucial aspect of nearly every modern data warehouse project. However, one of the biggest hurdles to overcome in real-time processing solutions is the ability to ingest efficiently and effectively, process, and store messages in real-time, particularly when dealing with high volumes of data. To ensure optimal performance, processing must be conducted in a manner that does not interfere with the ingestion pipeline. In addition to non-blocking processing, the data store must be capable of handling high-volume writes. Further challenges such as the ability to quickly act on the data, generating real-time alerts or business needs where dashboard that needs to be updated in real-time or near real-time. In many cases, the source systems utilize traditional relational database engines, such as MySQL, that do not offer event-based interfaces.
Azure Database for MySQL – Flexible Server is a cloud-based solution that provides a fully managed MySQL database service. This service is built on top of Azure’s infrastructure and offers greater flexibility.MySQL uses binary log (binlog) to record all the transactions in the order in which they are committed on the database. This includes changes to table schemas as well as changes to the rows in the tables. MySQL uses binlog mainly for purposes of replication and recovery.
Debezium is a powerful CDC (Change Data Capture) tool that is built on top of Kafka Connect. It is designed to stream the binlog, produces change events for row-level INSERT, UPDATE, and DELETE operations in real-time from MySQL into Kafka topics, leveraging the capabilities of Kafka Connect. This allows users to efficiently query only the changes from the last synchronization and upload those changes to the cloud. After this data is stored in Azure Data Lake storage, it can be processed using Azure Synapse Serverless SQL Pools. Business users can then monitor, analyse, and visualize the data using Power BI.
Solution overview
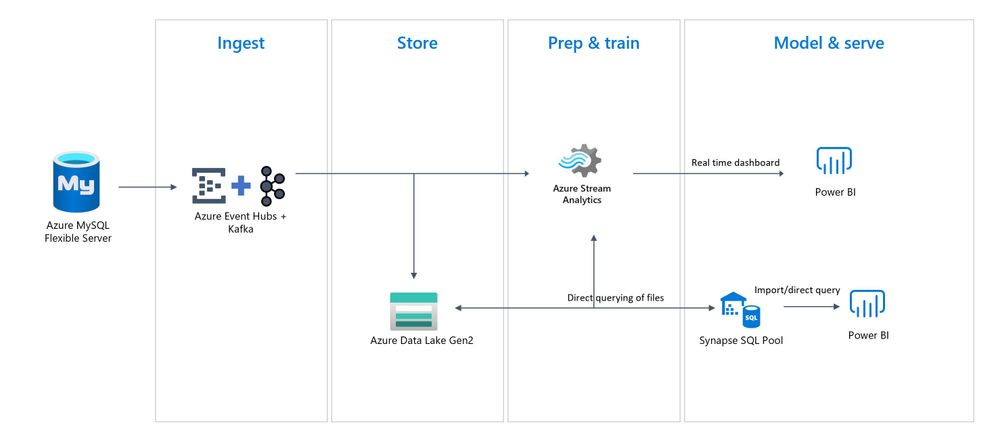
This solution entails ingesting MySQL data changes from the binary logs and converting the changed rows into JSON messages, which are subsequently sent to Azure Event Hub. After the messages are received by the Event Hub, an Azure Stream Analytics (ASA) Job distributes the changes into multiple outputs, as shown in the following diagram.
End-to-end serverless streaming platform with Azure Event Hubs for data ingestion
Components and Services involved
In this blog post, following are the services used for streaming the changes from Azure Database for MySQL to Power BI.
A Microsoft Azure account
An Azure Database for MySQL Flexible server
A Virtual Machine running Linux version 20.04
Kafka release (version 1.1.1, Scala version 2.11), available from kafka.apache.org
Debezium 1.6.2
An Event Hubs namespace
Azure Stream Analytics
Azure Data Lake Storage Gen2
Azure Synapse Serverless SQL pools
A Power BI workspace
Dataflow
The following steps outline the process to set up the components involved in this architecture to stream data in real time from the source Azure Database for MySQL flexible Server.
Provisioning and configuring Azure Database for MYSQL- Flexible Server & a Virtual Machine
Configure and run Kafka Connect with a Debezium MySQL connector
Reading CDC Messages Downstream from Azure Event Hub and capture data in an Azure Data Lake Storage Gen2 account in Parquet format
Create External Table with Azure Synapse Serverless SQL Pool
Use Serverless SQL pool with Power BI Desktop & create a report.
Build real-time dashboard with Power BI dataset produced from Stream Analytics
Each of the above steps is outlined in detail in the upcoming sections.
Your Azure Event Hubs and Azure Data Lake Storage Gen2 resources must be publicly accessible and can’t be behind a firewall or secured in an Azure Virtual Network.
The data in your Event Hubs must be serialized in either JSON, CSV, or Avro format.
You must have access to the workspace with at least the Storage Blob Data Contributor access role to the ADLS Gen2 account or Access Control Lists (ACL) that enable you to query the files.
You must have access to the workspace with at least the Storage Blob Data Contributor access role to the ADLS Gen2 account or Access Control Lists (ACL) that enable you to query the files.
Provisioning and configuring Azure Database for MYSQL- Flexible Server & a Virtual Machine
It is important to create an Azure Database for MySQL Flexible Server instance and a Virtual Machine as outlined below before proceeding to the next step. To do so, perform the following steps:
Under server parameters blade, configure binlog_expire_logs_seconds parameter, as per your requirements (e.g.: 86400 seconds for 24Hrs) on the server to make sure that binlogs are not purged quickly. For more information, see How to Configure server parameters.
Under the same server parameter blade, also configure and set binlog_row_image parameter to a value of FULL.
Use a command line client or download and install MySQL Workbench or another third-party MySQL client tool to connect to the Azure Database for MySQL Flexible Server.
Maintain enough disk space on the Azure VM to copy binary logs remotely.
For this example, the “orders_info” table has been created in Azure Database for MySQL Flexible Server
Configure and run Kafka Connect with a Debezium MySQL connector
To track row-level changes in response to insert, update and delete operations in database tables, Change Data Capture (CDC) is a technique that you use to track these changes, Debezium is a distributed platform that provides a set of Kafka Connect connectors that can convert these changes into event streams and send those events to Apache Kafka.
Reading CDC Messages Downstream from Event Hub and capture data in an Azure Data Lake Storage Gen2 account in Parquet format
Azure Event Hubs is a fully managed Platform-as-a-Service (PaaS) Data streaming and Event Ingestion platform, capable of processing millions of events per second. Event Hubs can process, and store events, data, or telemetry produced by distributed software and devices. Data sent to an event hub can be transformed and stored by using any real-time analytics provider or batching/storage adapters. Azure Events Hubs provides an Apache Kafka endpoint on an event hub, which enables users to connect to the event hub using the Kafka protocol.
Select the event hub created for the “orders_info” table.
Select Features > Process Data, and then select Start on the Capture data to ADLS Gen2 in Parquet format card.
3. Enter a name to identify your Stream Analytics job. Select Create.
4. Specify the Serialization type of your data in the Event Hubs and the Authentication method that the job will use to connect to Event Hubs. Then select Connect.
5. Then the connection is established successfully, you’ll see:
Fields that are present in the input data. You can choose Add field or you can select the three dots symbol next to a field to optionally remove, rename, or change its name.
A live sample of incoming data in the Data preview table under the diagram view. It refreshes periodically. You can select Pause streaming preview to view a static view of the sample input.
Select the Azure Data Lake Storage Gen2 tile to edit the configuration.
On the Azure Data Lake Storage Gen2 configuration page, follow these steps: a. Select the subscription, storage account name and container from the drop-down menu. b. After the subscription is selected, the authentication method and storage account key should be automatically filled in. c. For streaming blobs, the directory path pattern is expected to be a dynamic value. It’s required for the date to be a part of the file path for the blob – referenced as {date}. To learn about custom path patterns, see to Azure Stream Analytics custom blob output partitioning.
d. Select Connect
When the connection is established, you’ll see fields that are present in the output data.
Select Save on the command bar to save your configuration.
On the Stream Analytics job page, under the Job Topology heading, select Query to open the Query editor window.
To test your query with incoming data, select Test query.
After the events are sampled for the selected time range, they appear in the Input preview tab.
Stop the job before you make any changes to the query for any desired output. In many cases, your analysis doesn’t need all the columns from the input stream. You can use a query to project a smaller set of returned fields than in the pass-through query.
When you make changes to your query, select Save query to test the new query logic. This allows you to iteratively modify your query and test it again to see how the output changes.
After you verify the results, you’re ready to Start the job.
Select Start on the command bar to start the streaming flow to capture data. Then in the Start Stream Analytics job window:
Choose the output start time.
Select the number of Streaming Units (SU) that the job runs with. SU represents the computing resources that are allocated to execute a Stream Analytics job. For more information, see Streaming Units in Azure Stream Analytics.
In the Choose Output data error handling list, select the behavior you want when the output of the job fails due to data error. Select Retry to have the job retry until it writes successfully or select another option.
verify that the Parquet files are generated in the Azure Data Lake Storage container.
Create External Table with Azure Synapse Serverless SQL Pool
Select the file that you would like to create the external table from and right click -> New SQL Script -> Create External table
3. In the New External Table, change Max string length to 250 and continue
4. A dialog window will open. Select or create new database and provide database table name and select Open script
5. A new SQL Script opens, and you run the script against the database, and it will create a new External table.
6. Making a pointer to a specific file. You can only point to folder not the files too
7. Point to enriched folder in Data Lake Storage
8. Save all the work by clicking Publish All
9. Verify the external table created in Data -> Workspace -> SQL Database
External tables encapsulate access to files making the querying experience almost identical to querying local relational data stored in user tables. Once the external table is created, you can query it just like any other table:
SELECT TOP 100 * FROM dbo.orders_info
GO
SELECT COUNT(*) FROM dbo.orders_info
GO
10. END
Use serverless SQL pool with Power BI Desktop & create a report
Navigate to Azure Synapse Analytics Workspace. Starting from Synapse Studio, click Manage.
2. Under External Connections, click Linked services. Click + New. Click Power BI and click Continue.
3. Enter a name for the linked service and select an existing workspace which you want to use to publish. Provide any name in the “Name” field. Then you will see Power BI linked connection with the name.
4. Click Create.
5. View Power BI workspace in Synapse Studio
After your workspaces are linked, you can browse your Power BI datasets, edit/create new Power BI Reports from Synapse Studio.
Navigate to develop hub. Create Power BI linked service will be here.
Expand Power BI and the workspace you wish to use.
6. New reports can be created clicking + at the top of the Develop tab. Existing reports can be edited by clicking on the report name. Any saved changes will be written back to the Power BI workspace.
Summary
Overall, Debezium, Kafka Connect, Azure Event Hubs, Azure Data Lake Storage, Azure Stream Analytics, Synapse SQL Serverless, and Power BI work together to create a comprehensive, end-to-end data integration, analysis, and visualization solution that can handle real-time data streams from databases, store them in a scalable and cost-effective manner, and provide insights through a powerful BI tool.
To learn more about the services used in this post, check out the following resources:
This article is contributed. See the original author and article here.
Join Microsoft at Hannover Messe 2023 to learn how the latest enhancements to Microsoft Teams help frontline workers streamline communication and increase productivity.
This article is contributed. See the original author and article here.
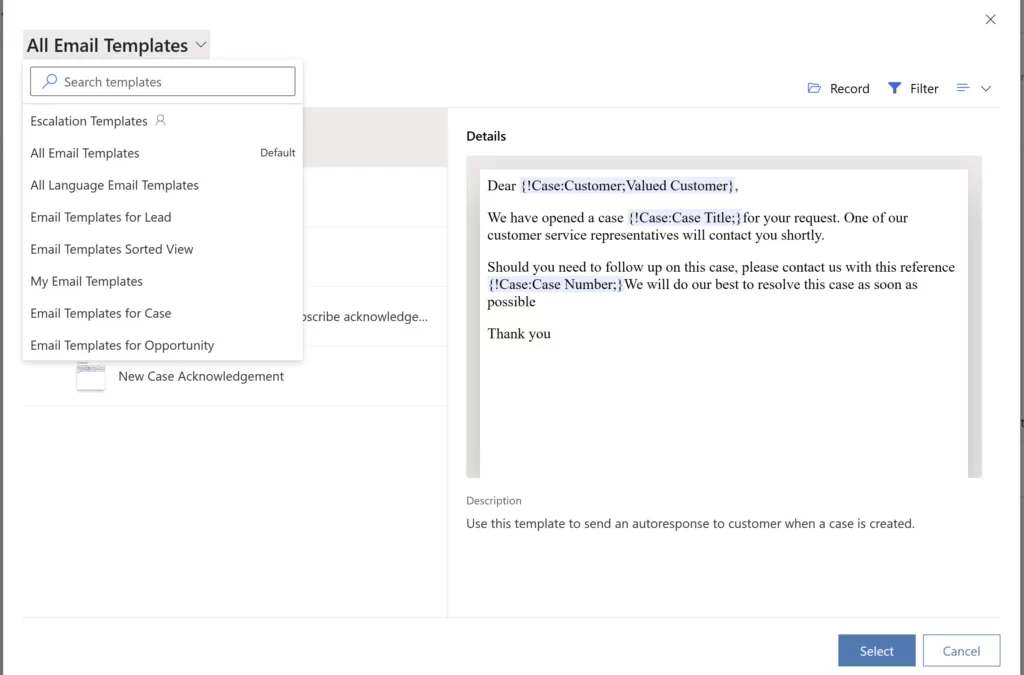
If you are a customer service agent, you know how important it is to respond to your customers quickly and effectively. You also know how frustrating it can be to waste time searching for the right email template to use for each situation. That is why you need to use email template views while selecting an email template.
We have upgraded enhanced email template selection to help agents efficiently use email templates. With integrated record selection and email template views, finding the right email template is easier than before.
With email template views, just create a view with your choice of filters and then have it available when selecting the templates. Creating a view with your favorite or most used templates will help save a lot of time when working with emails.
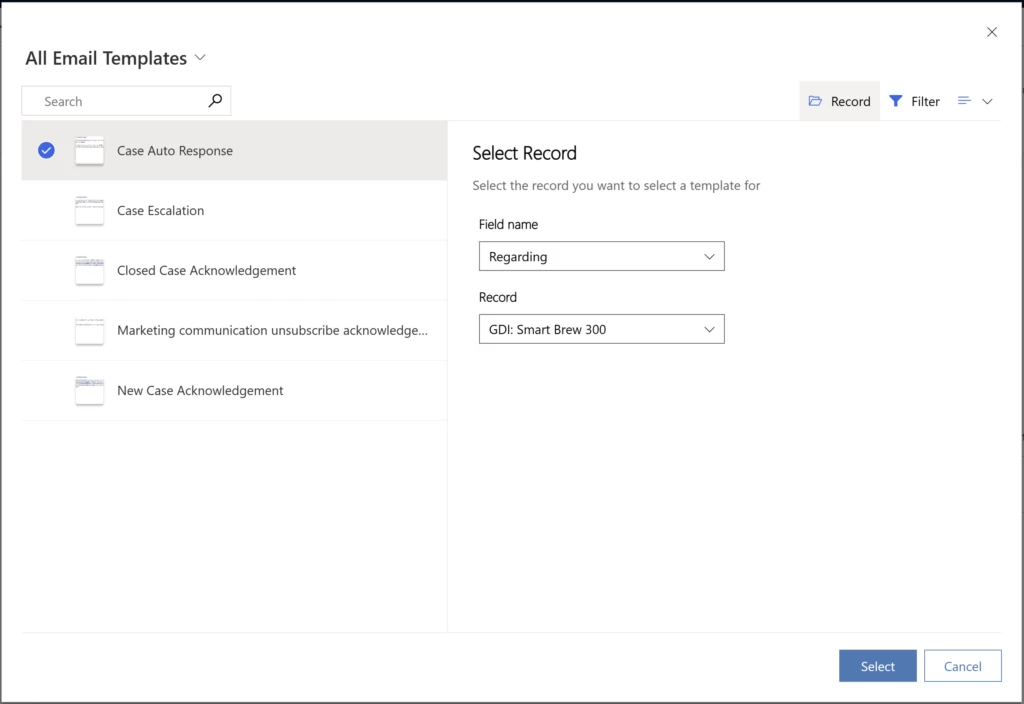
In Customer Service workspace and Customer Service Hub, the enhanced template dialog is enabled by default. Administrators can disable the enhanced email template selection option if they want to display the default email selection dialog. When using enhanced email template selection, admins can determine whether to show the record selection within the email template selection window. This saves the agent extra clicks when selecting a template. Regarding is selected by default and can be easily changed by navigating to the record tab. The list of templates will automatically get refreshed when Record is changed.
In short, when agents use email template views, they can use preconfigured views to find the right templates quickly, switch between views of templates that have persisting filters, and save time with the integrated record selection in the template selection dialog box.


























Recent Comments