This article is contributed. See the original author and article here.
Hi!
Ready to meet your new best friend? Say hello to GitHub Copilot, the AI pair programmer that’s about to change the way you code. It’s like having a super-smart friend who’s always ready to help. No matter the scenario, writing code, fixing bugs, or just trying to remember that one command you always forget.
We’ve got a brand-new GitHub Copilot Fundamentals Learning Path all about GitHub Copilot. What’s a Learning Path, you may ask? Well, it’s a sequence of courses that guides you step-by-step to learn new skills and discover the power of Microsoft products. You can find all sorts of Learning Paths on Microsoft Learn.
Our new Learning Path is split into two parts: “Introduction to GitHub Copilot” and “Introduction to GitHub Copilot for Business“.
In the first part, you’ll get to know GitHub Copilot and all its cool features. It’s like having a ChatGPT friend right in your editor, helping you out with code, error messages, and even generating unit tests. Plus, it’s got your back when you’re working on pull requests or need help with documentation. And let’s not forget about the command line – GitHub Copilot CLI is like the ultimate cheat sheet!
The second part is all about GitHub Copilot for Business. (Spoiler: this is where things get serious). We’re going to review business scenarios like: AI-based security vulnerability filtering, VPN proxy support, and a super simple sign-up process. Imagine having a complete squad of Coding experts ready to help your business code faster and smarter.
This article is contributed. See the original author and article here.
‘Offline-first’ with the Dynamics 365 Field Service Mobile application offers many advantages for frontline workers. The offline-enabled application will allow frontline workers to perform functions while they are in the field, without depending on an internet connection. This keeps them productive even in environments without high quality network coverage, which can be a common problem in rural locations or even remote urban areas where network coverage is poor.
In this blog post we will share details on recent enhancements to the Dynamics 365 ‘Offline-first’ as well as some new capabilities to help your organization debug customizations with the offline application. Let’s go!
Wave 1 2023 enhancements
With the release of Wave 1 2023, frontline workers will have a faster sync experience and better visibility into the sync status of their offline-enabled Field Service Mobile application.
The offline sync icon is now moved from the sitemap to the header of the application providing an ever-present status of their offline app.
Based on states of the icon, the offline-enabled frontline worker can see if their application is connected to Dataverse, a sync is actively running, an up-sync in pending, or if the previous sync resulted in an error. This will allow the user to make informed decisions while in the field. For example, if an up-sync is pending after a period of being without network access, they will know to connect and allow that sync to complete so all their changes can be viewed by the back office.
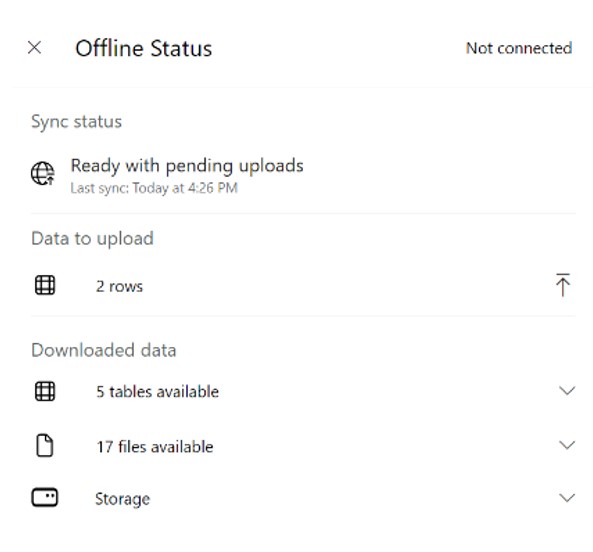
The offline status page is also enhanced with more details on the sync, the size on disk and app connectivity status.
In addition to offline-related interface update, the sync experience is faster and more reliable. This includes optimizations to intelligently sync table or metadata changes, and improved parallelization to bring down data faster – including when the application is accessed in a way which forces a record sync such as launching the app via push notification.
Debugging the offline application
Debugging on a mobile application can be a difficult task, which is made more challenging when introducing unique aspects of ‘Offline’ mode. To help support customers who require customizations and enhancements while working offline we have introduced debugging capabilities for the model driving applications running on Android and Windows platforms, iOS platform compatibility is coming soon.
This article is contributed. See the original author and article here.
Since Azure Stack HCI 21H2, customers have used Network ATC to:
Reduce host networking deployment time, complexity, and errors
Deploy the latest Microsoft validated and supported best practices
Ensure configuration consistency across the cluster
Eliminate configuration drift
Network ATC has led to HUGE reductions in customer support cases which means increased uptime for your business applications and less headaches for you! But what if you already deployed your cluster? How do you take advantage now that you’re travelled through that trepidatious train of thought against taking on new technology?
With minimal alliteration, this article will show you how to migrate an existing cluster to Network ATC so you can take advantage of all the benefits mentioned above. Once completed, you could easily cookie-cut this configuration across all new deployments using our previous blog; so this would be a one-time migration, and all new clusters will gain the benefits!
Before you begin
Since this is a live cluster with running VMs, we’ll take some precautions to ensure we’re never working on a host with a running VM on it. If you don’t have running workloads on these nodes, you don’t need these instructions. Just add your intent command as if this was a brand-new cluster.
As some background, Network ATC stores information in the cluster database which is then replicated to other nodes in the cluster. The Network ATC service on the other nodes in the cluster see the change in the cluster database and implements the new intent. So we setup the cluster to receive a new intent, but we can also control the rollout of the new intent by stopping or disabling the Network ATC service on nodes that have virtual machines on them.
Procedure
Step 1: Install the Network ATC feature
First, let’s install Network ATC on EVERY node in the cluster using the following command. This does not require a reboot.
Install-WindowsFeature -Name NetworkATC
Step 2: Pause one node in the cluster
Pause one node in the cluster. This node will be migrated to Network ATC. We’ll repeat this step later for other nodes in the cluster too. As a result of this pause, all workloads will migrate to other nodes in the cluster leaving this machine available for changes. To do this, you can use the command:
Suspend-ClusterNode
Step 3: Stop the Network ATC service
For all nodes that are not paused, stop and disable the Network ATC service. As a reminder, this is to prevent Network ATC from implementing the intent while there are running virtual machines. To do this, you can use the commands:
Next, we’ll remove any previous configurations that might interfere with Network ATC’s ability to implement the intent. An example of this might be a Data Center Bridging (NetQos) policy for RDMA traffic. Network ATC will also deploy this, and if it sees a conflicting policy, Network ATC is wise enough not to interfere with it until you make it clear which policies you want to keep. While Network ATC will attempt to “adopt” the existing configuration if the names match (whether it be NetQos or other settings) it’s far simpler to just remove the existing configuration and let Network ATC redeploy.
Network ATC deploys a lot more than these items, but these are the items that need to be resolved before implementing the new intent.
VMSwitch
If you have more than one VMSwitch on this system, ensure you specify the switch attached to the adapters that will be used in this intent.
If you accidentally deployed an LBFO team, we’ll need to remove that as well. As you might have read, LBFO is not supported on Azure Stack HCI at all. Don’t worry, Network ATC will prevent these types of accidental oversights in the future as it will never deploy a solution that we do not support.
If the nodes were configured via VMM, these configuration objects may need to be removed from VMM as well.
Step 5: Add the Network ATC intent
It’s now time to add a Network ATC intent. You’ll only need to do this once since Network ATC intents are implemented cluster wide. However, we have taken some precautions to control the speed of the rollout. In step 2, we paused this node so there are no running workloads on it. In step 3, we stopped and disabled the Network ATC service on nodes where there are running workloads.
If you stopped and disabled the Network ATC service, you should start this service on this node only. To do this, run the following command:
Now, add your Network ATC intent(s). There are some example intents listed on our documentation here.
Step 6: Verify deployment on one node
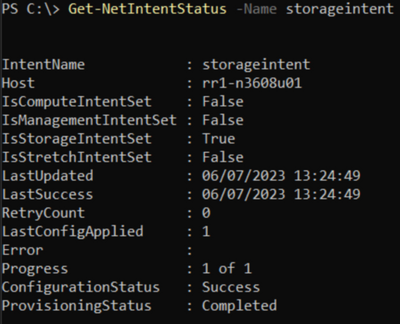
To verify that the node has successfully deployed the intent submitted in step 5, use the Get-NetIntentStatus command as shown below.
Get-NetIntentStatus -Name
The Get-NetIntentStatus command will show the deployment status of the requested intents. Eventually, there will be one object per intent returned from each node in the cluster. As a simple example, if you had a 3-node cluster with 2 intents, you would see 6 objects returned by this command, each with their own status.
Before moving on from this step, ensure that each intent you added has an entry for the host you’re working on, and the ConfigurationStatus shows Success. If the ConfigurationStatus shows “Failed” you should look to see if the Error message indicates why it failed. We have some quick resolutions listed in our documentation here.
Step 7: Rename the VMSwitch on other nodes
Now that one node is deployed with Network ATC, we’ll get ready to move on to the next node. To do this, we’ll migrate the VMs off the next node. This requires that the nodes have the same VMSwitch name as the node deployed with Network ATC. This is a non-disruptive change and can be done on all nodes at the same time.
Why don’t we change the Network ATC VMSwitch? Two reasons, the first is that Network ATC ensures that all nodes in the cluster have the same name to ensure live migrations and symmetry. The second is that you really shouldn’t need to worry about the VMSwitch name. This is simply a configuration artifact and just one more thing you’d need to ensure is perfectly deployed. Instead of that, Network ATC implements and controls the names of configuration objects.
Step 8: Resume the cluster node
This node is now ready to re-enter the cluster. Run this command to put it back into service:
Resume-ClusterNode
Step 9: Rinse and Repeat
Each node will need to go through the procedure outlined above. To complete the migration to Network ATC across the cluster, repeat steps 1 – 4, 6 and 8.
Summary
Migrating your existing clusters to Network ATC can be a game-changer for your cluster infrastructure and management. By automating and simplifying your network management, Network ATC can help you save time, increase efficiency, improve overall performance and avoid cluster downtime.
If you have any further questions or would like to learn more about Network ATC, please don’t hesitate to reach out to us!
This article is contributed. See the original author and article here.
Customer service agents in a digital contact center interact with multiple customers daily through live chat, phone calls, and social media channels. During customer interactions, often they find themselves searching for relevant information on various screens or other systems, resulting in increased wait time for the end customer. Also, they want to quickly capture or update the information about their conversation, in real time without having to create or link a case to a conversation. Recent enhancements to the Active Conversation form allow agents to access and edit relevant information without any screen switching.
Now, agents have all the relevant information at their fingertips, so that they spend less time looking for information on different screens or systems and help customers quickly. This leads to a reduction in average wait time and better customer satisfaction.
Customize the Active Conversation form
This feature allows administrators to add custom fields on the conversation form and embed canvas apps to display the information from external sources. To ensure agents can capture information quickly, it offers agents the flexibility to view pre-filled information and update it as needed while interacting with the customer. They can view the records related to the conversation on the sub-grids.
Access the enhanced Active Conversation form
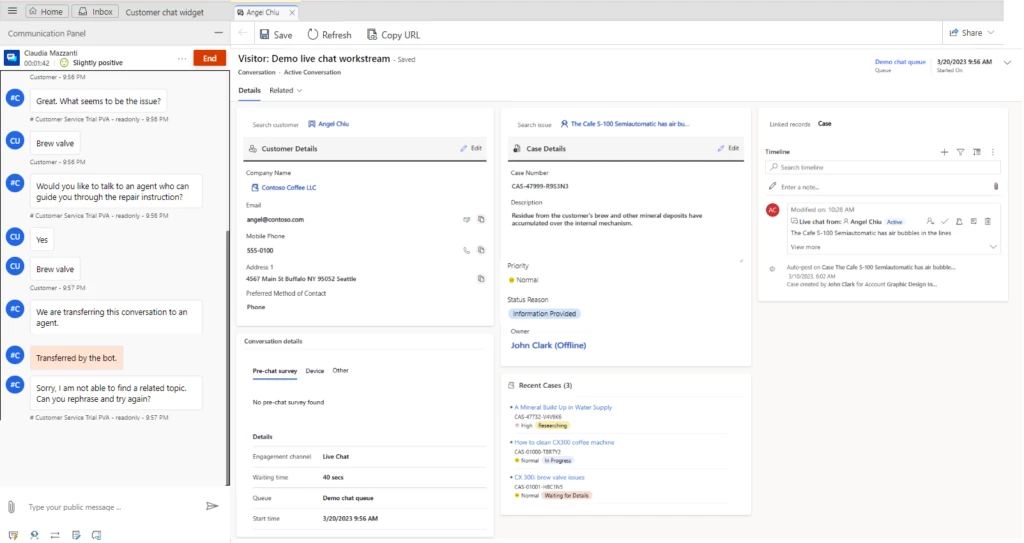
The Active Conversation form now displays the Customer 360 card. This allows agents to view information related to the customer. They can also make inline edits without having to navigate to contact or account form. Similarly, it shows case details with information related to the case linked to the conversation and allows agents to make inline edits as needed. Administrators can configure the fields they want to show on both these cards.
Additionally, the form includes the configurable recent cases card. This shows the color-coded priority and case status for easy discoverability by the agents. Moreover, switching from the active to the closed conversation form is restricted when the conversation is still active. The reverse is true as well.
Administrators can enable these enhancements in the Customer Service workspace application by navigating to the Customer Service Admin center > Workspaces > Active Conversation form settings.
This article is contributed. See the original author and article here.
On June 1, 2023, Microsoft Defender for IoT moved to site-based licensing for organizations looking to protect their operation technology (OT) environments. The previous Azure consumption model for this solution will no longer be available for purchase by new customers. Existing customers can choose to transition to site-based licensing or remain on the consumption model.
In today’s digital transformation, operational technology (OT) has become an important part of various industries, from power plants and manufacturing facilities to transportation systems and healthcare institutions. While OT systems play an essential role in smoothly operating critical infrastructure, adversaries often target vulnerabilities in these interconnected systems causing severe business and operational disruption, financial losses, reputational damage, and more. Microsoft Defender for IoT helps organizations reduce these risks by enabling security teams to identify and remediate vulnerable OT systems in their environment – limiting exposure to threats like ransomware and targeted malware attacks.
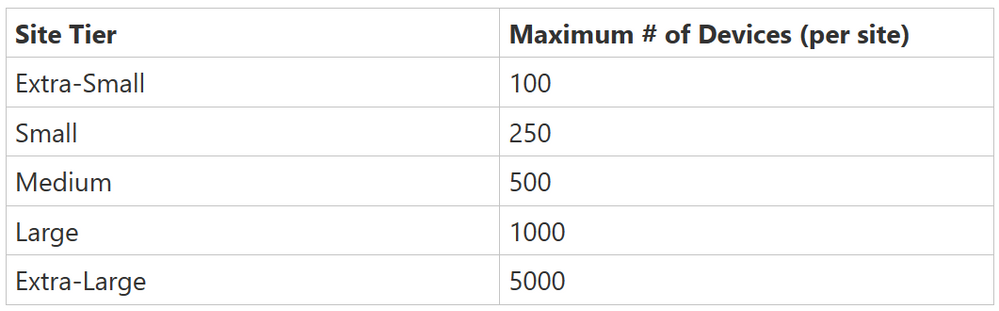
To help organizations evolve their defenses against the growing attacks on OT environments, we are thrilled to announce site-based licensing for Defender for IoT. This new model brings increased price predictability and flexibility to organizations with sites that vary in size by offering a tiered approach based on the maximum number of OT devices looking to be protected per site. With this solution, organizations can easily determine and manage the cost of securing their OT systems. We believe that by introducing site-based licensing, we are making it more convenient than ever for organizations to empower security teams with the tools needed to manage and protect their operational technology.
Note: A site is a physical location (facility, campus, office building, hospital, rig, etc.).
How site-based licensing works
Organizations that want to secure their OT environments with Defender for IoT will now be able to purchase annual licenses with standard pricing based on the maximum number of OT devices they wish to protect at each individual site. Prices are flat rates for each site size and are not prorated based on the numbers of devices. Site sizes are determined by the maximum number of devices per site.
Note: Defender for IoT site entitlement is licensed annually with standard pricing respective to each site tier.
For example, if an organization wanted to secure all OT devices with Defender for IoT across three of its sites – where site one has 90 OT devices, site two has 700 devices, and site three has 25 devices, the organization would have to buy an Extra-Small license for site one, a Large license for site two, and another Extra-Small license for site three.
Note: For scenarios where an organization wants to secure over 5000 OT devices at a single site, we ask that they contact their Microsoft sales representative.
Let us know what you think
We are excited to provide organizations with a more convenient way to consume Defender for IoT in a manner that is flexible enough to accommodate varying site sizes, while also being predictably priced. If you have any feedback, please feel free to let us know in the comments below.


Recent Comments