This article is contributed. See the original author and article here.
Azure HDInsight Spark 5.0 to HDI 5.1 Migration
A new version of HDInsight 5.1 is released with Spark 3.3.1. This release improves join query performance via Bloom filters, increases the Pandas API coverage with the support of popular Pandas features such as datetime.timedelta and merge_asof, simplifies the migration from traditional data warehouses by improving ANSI compliance and supporting dozens of new built-in functions.
In this article we will discuss about the migration of user applications from HDInsight 5.0(Spark 3.1) to HDInsight 5.1 (Spark 3.3). The sections include,
1. Changes which are compatible with minor changes
2. Changes in Spark that require application changes
Application Changes with backport.
The below changes are part of HDI 5.1 release. If these functions are used in applications, the given steps can be taken to avoid the changes in application code.
Since Spark 3.3, the histogram_numeric function in Spark SQL returns an output type of an array of structs (x, y), where the type of the ‘x’ field in the return value is propagated from the input values consumed in the aggregate function. In Spark 3.2 or earlier, x’ always had double type. Optionally, use the configuration spark.sql.legacy.histogramNumericPropagateInputType since Spark 3.3 to revert to the previous behavior.
Spark 3.1 (pyspark)
Spark 3.3:
In Spark 3.3, the timestamps subtraction expression such as timestamp ‘2021-03-31 23:48:00’ – timestamp ‘2021-01-01 00:00:00’ returns values of DayTimeIntervalType. In Spark 3.1 and earlier, the type of the same expression is CalendarIntervalType. To restore the behavior before Spark 3.3, you can set spark.sql.legacy.interval.enabled to true.
Since Spark 3.3, the functions lpad and rpad have been overloaded to support byte sequences. When the first argument is a byte sequence, the optional padding pattern must also be a byte sequence and the result is a BINARY value. The default padding pattern in this case is the zero byte. To restore the legacy behavior of always returning string types, set spark.sql.legacy.lpadRpadAlwaysReturnString to true.
> SELECT hex(lpad(x’1020′, 5, x’05’))
0505051020
SELECT hex(rpad(x’1020′, 5, x’05’)) 1020050505
Since Spark 3.3, Spark turns a non-nullable schema into nullable for API DataFrameReader.schema(schema: StructType).json(jsonDataset: Dataset[String]) and DataFrameReader.schema(schema: StructType).csv(csvDataset: Dataset[String]) when the schema is specified by the user and contains non-nullable fields. To restore the legacy behavior of respecting the nullability, set spark.sql.legacy.respectNullabilityInTextDatasetConversion to true.
Since Spark 3.3, nulls are written as empty strings in CSV data source by default. In Spark 3.2 or earlier, nulls were written as empty strings as quoted empty strings, “”. To restore the previous behavior, set nullValue to “”, or set the configuration spark.sql.legacy.nullValueWrittenAsQuotedEmptyStringCsv to true.
Sample Data:
Spark 3.1:
Spark 3.3:
Since Spark 3.3, Spark will try to use built-in data source writer instead of Hive serde in INSERT OVERWRITE DIRECTORY. This behavior is effective only if spark.sql.hive.convertMetastoreParquet or spark.sql.hive.convertMetastoreOrc is enabled respectively for Parquet and ORC formats. To restore the behavior before Spark 3.3, you can set spark.sql.hive.convertMetastoreInsertDir to false.
Spark logs:
INFO ParquetOutputFormat [Executor task launch worker for task 0.0 in stage 0.0 (TID 0)]: ParquetRecordWriter [block size: 134217728b, row group padding size: 8388608b, validating: false]INFO ParquetWriteSupport [Executor task launch worker for task 0.0 in stage 0.0 (TID 0)]: Initialized Parquet WriteSupport with Catalyst schema:{ “type” : “struct”, “fields” : [ { “name” : “fname”, “type” : “string”, “nullable” : true, “metadata” : { } }, {
Since Spark 3.3.1 and 3.2.3, for SELECT … GROUP BY a GROUPING SETS (b)-style SQL statements, grouping__id returns different values from Apache Spark 3.2.0, 3.2.1, 3.2.2, and 3.3.0. It computes based on user-given group-by expressions plus grouping set columns. To restore the behavior before 3.3.1 and 3.2.3, you can set spark.sql.legacy.groupingIdWithAppendedUserGroupBy
In Spark 3.3, spark.sql.adaptive.enabled is enabled by default. To restore the behavior before Spark 3.3, you can set spark.sql.adaptive.enabled to false.
In Spark3.1, AQE is set to false by default.
In Spark3.3, AQE is enabled by default.
Adaptive Query Execution (AQE) is an optimization technique in Spark SQL that makes use of the runtime statistics to choose the most efficient query execution plan, which is enabled by default since Apache Spark 3.3.0. Spark SQL can turn on and off AQE by spark.sql.adaptive.enabled as an umbrella configuration. As of Spark 3.0, there are three major features in AQE: including coalescing post-shuffle partitions, converting sort-merge join to broadcast join, and skew join optimization.
In Spark 3.3, the output schema of SHOW TABLES becomes namespace: string, tableName: string, isTemporary: boolean. In Spark 3.1 or earlier, the namespace field was named database for the builtin catalog, and there is no isTemporary field for v2 catalogs. To restore the old schema with the builtin catalog, you can set spark.sql.legacy.keepCommandOutputSchema to true.
In Spark3.1, Field is termed as database:-
In Spark3.3, Field is termed as Namespace: –
We can restore the behavior by setting the below property.
In Spark 3.3, the output schema of SHOW TABLE EXTENDED becomes namespace: string, tableName: string, isTemporary: boolean, information: string. In Spark 3.1 or earlier, the namespace field was named database for the builtin catalog, and no change for the v2 catalogs. To restore the old schema with the builtin catalog, you can set spark.sql.legacy.keepCommandOutputSchema to true.
Show similar screenshot details in both spark-sql shell for spark3.1 and spark3.3 versions.
In Spark3.1, Field is termed as database:
In Spark3.3, Field is termed as Namespace: –
We can restore the behavior by setting the below property.
In Spark 3.3, CREATE TABLE AS SELECT with non-empty LOCATION will throw AnalysisException. To restore the behavior before Spark 3.2, you can set spark.sql.legacy.allowNonEmptyLocationInCTAS to true.
In spark 3.3, we are able to CTAS with non-empty location, as shown below
In spark 3.3 also we are able to create tables without the above property change
In Spark 3.3, special datetime values such as epoch, today, yesterday, tomorrow, and now are supported in typed literals or in cast of foldable strings only, for instance, select timestamp’now’ or select cast(‘today’ as date). In Spark 3.1 and 3.0, such special values are supported in any casts of strings to dates/timestamps. To keep these special values as dates/timestamps in Spark 3.1 and 3.0, you should replace them manually, e.g. if (c in (‘now’, ‘today’), current_date(), cast(c as date)).
In spark 3.3 and 3.1 below code works exactly same.
Application Changes Expected
There are some changes in the spark functions between HDI 5.0 and 5.1. The changes depend on whether the applications use below functionalities and APIs.
Since Spark 3.3, DESCRIBE FUNCTION fails if the function does not exist. In Spark 3.2 or earlier, DESCRIBE FUNCTION can still run and print “Function: func_name not found”.
Spark 3.1:
Spark 3.3:
Since Spark 3.3, DROP FUNCTION fails if the function name matches one of the built-in functions’ name and is not qualified. In Spark 3.2 or earlier, DROP FUNCTION can still drop a persistent function even if the name is not qualified and is the same as a built-in function’s name.
Since Spark 3.3, when reading values from a JSON attribute defined as FloatType or DoubleType, the strings “+Infinity”, “+INF”, and “-INF” are now parsed to the appropriate values, in addition to the already supported “Infinity” and “-Infinity” variations. This change was made to improve consistency with Jackson’s parsing of the unquoted versions of these values. Also, the allowNonNumericNumbers option is now respected so these strings will now be considered invalid if this option is disabled.
Since Spark 3.3, when reading values from a JSON attribute defined as FloatType or DoubleType, the strings “+Infinity”, “+INF”, and “-INF” are now parsed to the appropriate values, in addition to the already supported “Infinity” and “-Infinity” variations. This change was made to improve consistency with Jackson’s parsing of the unquoted versions of these values. Also, the allowNonNumericNumbers option is now respected so these strings will now be considered invalid if this option is disabled.
Spark 3.3:
Spark 3.1:
Spark 3.3 introduced error handling functions like below:
TRY_SUBTRACT – behaves as an “-” operator but returns null in case of an error.
TRY_MULTIPLY – is a safe representation of the “*” operator.
TRY_SUM – is an error-handling implementation of the sum operation.
TRY_AVG – is an error handling-implementation of the average operation.
TRY_TO_BINARY – eventually converts an input value to a binary value.
Example of ‘try_to_binary’ function:
When correct value given for base64 decoding:
When wrong value given for base64 decoding it doesn’t throw any error.
Since Spark 3.3, ADD FILE/JAR/ARCHIVE commands require each path to be enclosed by ” or ‘ if the path contains whitespaces.
In spark3.3:
In spark3.1: Multiple jars adding not working, only at a time can be added.
16.In Spark 3.3, the following meta-characters are escaped in the show() action. In Spark 3.1 or earlier, the following metacharacters are output as it is.
n (new line)
r (carrige ret)
t (horizontal tab)
f (form feed)
b (backspace)
u000B (vertical tab)
u0007 (bell)
In Spark3.3, meta-characters are escaped in the show() action.
In Spark3.1, the meta-characters are actually interpreted as their define functions.
In Spark 3.3, the output schema of DESCRIBE NAMESPACE becomes info_name: string, info_value: string. In Spark 3.1 or earlier, the info_name field was named database_description_item and the info_value field was named database_description_value for the builtin catalog. To restore the old schema with the builtin catalog, you can set spark.sql.legacy.keepCommandOutputSchema to true.
In Spark 3.1, we see the below headers before we set the property to false and check.
In Spark 3.3, we see the Info name and Info value before we set the property to true.
In Spark 3.3, DataFrameNaFunctions.replace() no longer uses exact string match for the input column names, to match the SQL syntax and support qualified column names. Input column name having a dot in the name (not nested) needs to be escaped with backtick `. Now, it throws AnalysisException if the column is not found in the data frame schema. It also throws IllegalArgumentException if the input column name is a nested column. In Spark 3.1 and earlier, it used to ignore invalid input column name and nested column name.
In Spark 3.3, CREATE TABLE .. LIKE .. command can not use reserved properties. You need their specific clauses to specify them, for example, CREATE TABLE test1 LIKE test LOCATION ‘some path’. You can set spark.sql.legacy.notReserveProperties to true to ignore the ParseException, in this case, these properties will be silently removed, for example: TBLPROPERTIES(‘owner’=’yao’) will have no effect. In Spark version 3.1 and below, the reserved properties can be used in CREATE TABLE .. LIKE .. command but have no side effects, for example, TBLPROPERTIES(‘location’=’/tmp’) does not change the location of the table but only creates a headless property just like ‘a’=’b’.
In spark 3.3 we got the same parse exceptions, post setting the property we were able to create the table
In spark 3.1 , we didn’t get any exceptions or errors:
In Spark 3.3, the unit-to-unit interval literals like INTERVAL ‘1-1’ YEAR TO MONTH and the unit list interval literals like INTERVAL ‘3’ DAYS ‘1’ HOUR are converted to ANSI interval types: YearMonthIntervalType or DayTimeIntervalType. In Spark 3.1 and earlier, such interval literals are converted to CalendarIntervalType. To restore the behavior before Spark 3.3, you can set spark.sql.legacy.interval.enabled to true.
In spark 3.3, post setting up this spark.sql.legacy.interval.enabled to true these literals are converted to ANSI interval types: YearMonthIntervalType or DayTimeIntervalType.
In Spark 3.1, there are no changes due to the change in property.
In Spark 3.3, the TRANSFORM operator can’t support alias in inputs. In Spark 3.1 and earlier, we can write script transform like SELECT TRANSFORM(a AS c1, b AS c2) USING ‘cat’ FROM TBL.
In Spark 3.1 we are able use direct transforms but , In spark 3.3, direct transform is prohibited , but can be use with below workaround.
Dynamics 365 Commerce is a comprehensive omnichannel solution that empowers retailers to deliver personalized, seamless, and differentiated shopping experiences across physical and digital channels. In the 2024 release Wave 1, Dynamics 365 Commerce continues to innovate and enhance its capabilities to improve store associate productivity and meet the evolving needs of customers and businesses. Here are some of the highlights of the new features coming soon:
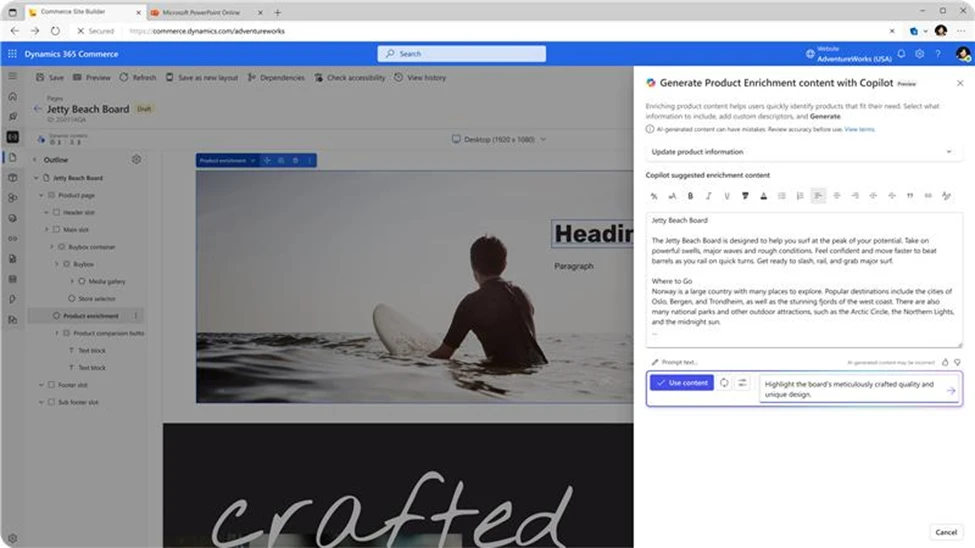
Copilot in Site builder is going global and multi-lingual:
Copilot in Site builder is a generative AI assistant that helps users create engaging and relevant content for their e-commerce sites. Copilot uses the product information and the user’s input to generate product enrichment content that is crafted using brand tone and tailored for targeted customer segments.
Image: Copilot Site Builder
In the 2024 release wave 1, Copilot in Site builder is expanding its language support to include support for 23 additional locales including German, French, Spanish, and more. This feature demonstrates Microsoft’s commitment to making Copilot accessible globally and empowering users to create multilingual content with ease and efficiency.
Strengthening our dedication to creating a comprehensive B2B solution for Digital Commerce by supporting B2B indirect commerce
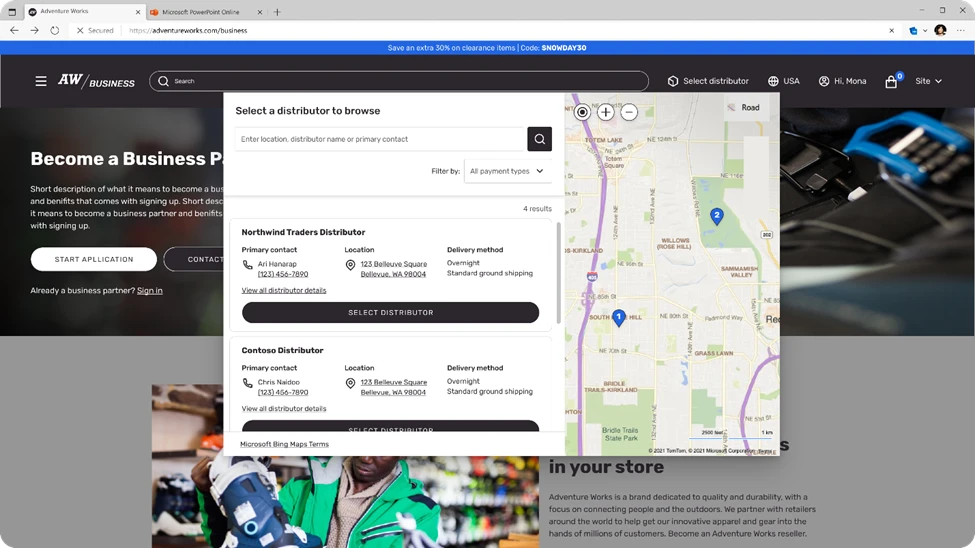
Dynamics 365 Commerce supports both B2C and B2B commerce scenarios, enabling retailers to sell directly to consumers and businesses. In the 2024 release wave 1, Dynamics 365 Commerce fortifies its B2B investments by introducing support for B2B indirect commerce, which enables manufacturers selling through a network of distributors to get complete visibility into their sales and inventory.
Image: New distributor capabilities
New distributor capabilities enable manufacturers to provide a self-service platform that simplifies distributor operations and builds meaningful, long-lasting business relationships through efficient and transparent transactions. Distributors can access product catalogs and pricing specific to their partner agreements, manufacturers can place orders on behalf of their customers with specific distributor, and outlets can track order status and history.
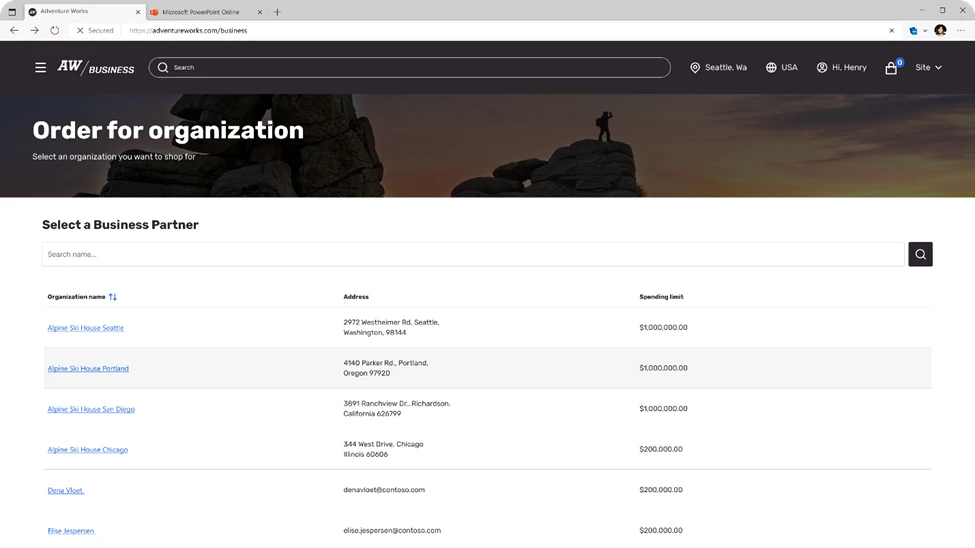
Dynamics 365 Commerce also streamlines multi-outlet ordering, enabling business buyers that are associated with more than one outlet organization to buy for all of them. Commerce provides the ability to seamlessly buy for multiple organizations using the same email account, enabling buyers to be more efficient.
Image: Order for Organizations
Additionally, Dynamics 365 Commerce supports advance ordering, which is a common practice in some businesses to order products in advance to ensure they have adequate stock when needed. This feature enables customers to specify the desired delivery date and include additional order notes.
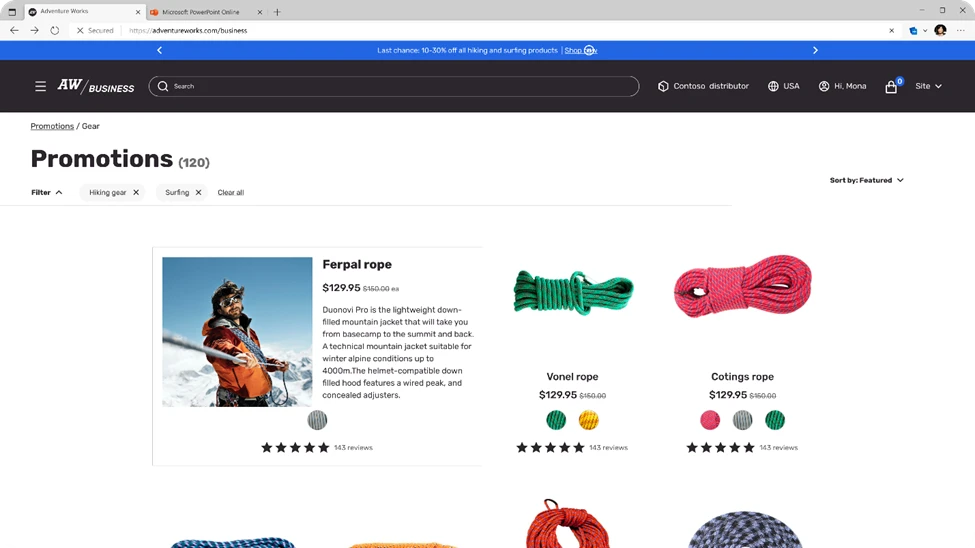
Also, introducing support for a promotions page on an e-commerce site that serves as a hub to showcase various deals and promotions that shoppers can take advantage of. The promotions page can display active and upcoming promotions.
Image : Promotions Page
Adyen Tap to Pay is coming to Store Commerce app on iOS
The Store Commerce app is a mobile point of sale (POS) solution that enables store associates to complete transactions through a mobile device on the sales floor, pop-up store, or remote location. The Store Commerce app supports various payment methods, such as cash, card, gift card, and loyalty points.
Image: Adyen Tap to Pay
In the 2024 release wave 1, Dynamics 365 Commerce is introducing Adyen Tap to Pay capabilities into the Store Commerce app for iOS, so that retailers everywhere can accept payments directly on Apple iPhones. Adyen Tap to Pay enhances the utility and versatility of the Store Commerce app, as it eliminates the need for additional hardware or peripherals to process payments. It also enables retailers to offer a more customer-centric and engaging in-store retail experience, as store associates can interact with customers anywhere in the store and complete transactions on the spot.
Speed up your checkout process with simplified and consistent payment workflows for different payment methods on Store Commerce app
Efficiency and predictability are key to the smooth operation of a point of sale (POS) system, especially when it comes to payment processing. When store associates can process customer payments across a variety of payment types with minimal friction, customers spend less time waiting and more time shopping.
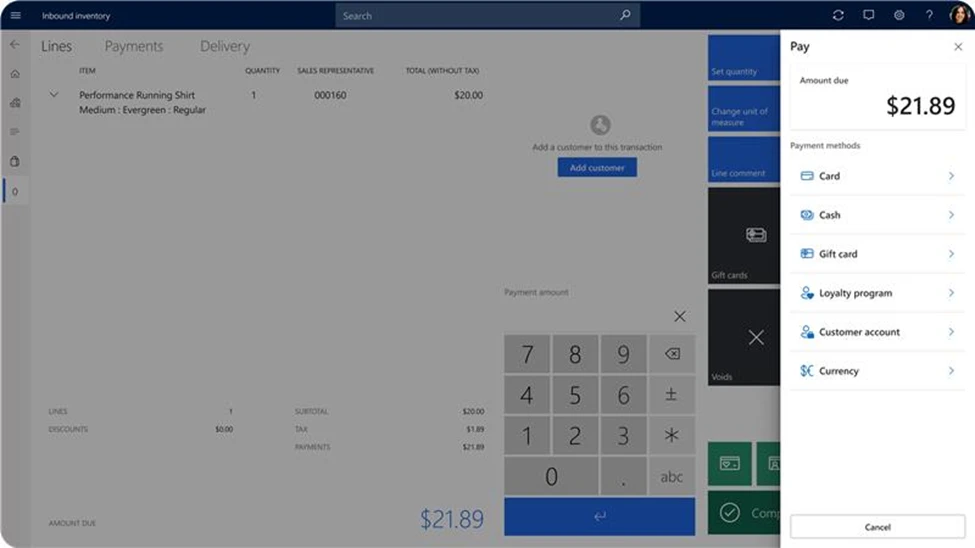
In the 2024 release wave 1, Dynamics 365 Commerce is improving the POS payment processing user experience to create more consistent workflows across payment types. The new user experience simplifies the payment selection and confirmation process, reduces the number of clicks and screens, and provides clear feedback and guidance to the store associate. The new user experience also supports split tendering, which allows customers to pay with multiple payment methods in a single transaction.
Image: Check out process
The improved POS payment processing user experience will contribute to efficiencies in the checkout process and more satisfied customers. It will also reduce the training time and effort for store associates, as they can easily learn and master the payment workflows.
Enabling retailers to effectively monitor and track inventory of Batch-controlled products via Store Commerce app
Batch-controlled products are products that are manufactured in batches and associated with unique identifiers for quality control and traceability. Batch-controlled products are commonly used in food, chemical, and electronics industries, where the quality and safety of the products are critical.
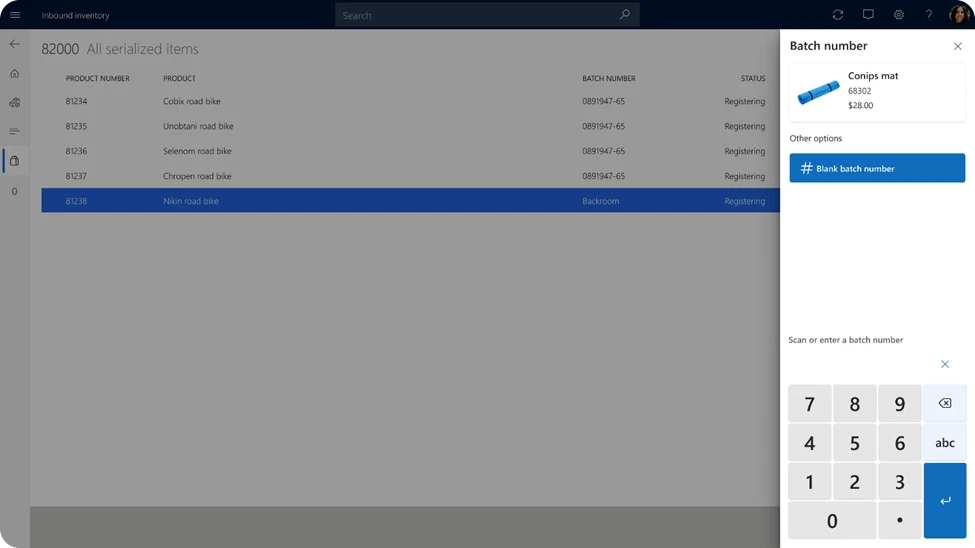
Image: Batch Control Products
In the 2024 release wave 1, Dynamics 365 Commerce enhances the Store Commerce app to support batch-controlled products. This feature enables store associates to scan or enter the batch number of the products during the sales or return transactions and validate the batch information against the inventory records. This feature also enables store associates to view the batch details of the products, such as the expiration date, manufacture date, and lot number.
With these new features, Dynamics 365 Commerce aims to provide you with the best tools and solutions to grow your business and delight your customers. Whether you want to create engaging and relevant content for your e-commerce site, automate and integrate your order management workflows, expand your B2B commerce opportunities, or improve your payment processing and inventory management, Dynamics 365 Commerce has something new for you.
To learn more about Dynamics 365 Commerce:
Learn more about additional investments and timeline for these investments here in release plans.
This article is contributed. See the original author and article here.
While onboarding customers to Azure they ask what permissions do we need to assign to our IT Ops or to partners and I’ve seen customer gets confused when we ask them for Azure AD permission for some task and they say we’ve provided owner access on Azure Subscription why Azure AD permission is required and how this is related. So thought of writing this blog to share how many permission domains are there when you use Azure.
We will talk about these RBAC Domain:
Classic Roles
Azure RBAC Roles
Azure AD Roles
EA RBAC
MCA RBAC
Reserved Instance RBAC
Classic Roles
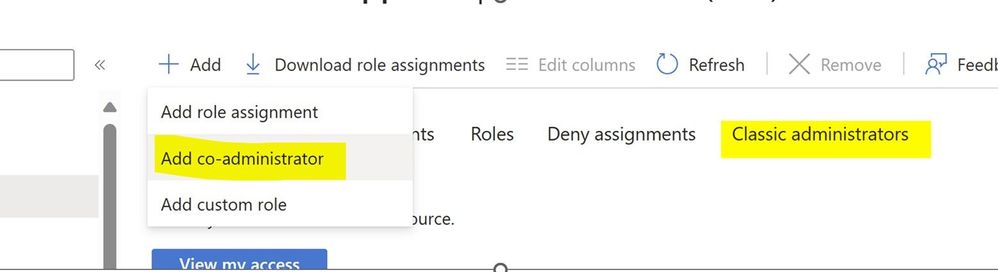
So let us talk about RBAC first – When I used to work in Azure Classic portal it used to be fewer roles. Mostly Account Admin, Co-Admin and Service Admin. The person who created subscription would become service Admin and if that person wanted to share the admin privilege, then he used to assign co-administrator role to the other guy
So when you go to Subscription -> IAM blade you’ll still see this. I have seen customers trying to provide owner access just try to use this Add Co-administrator button. Now you know the difference. This is not mean for providing someone access to ARM resource.
Azure RBAC
Let us talk about ARM RBAC now. When we moved to Azure RBAC from classic. We started with more fine-grained access control. With each service there was a role e.g. virtual machine contributor for managing VMs, Network contributor for managing network and so on. So, the user gets stored in Azure AD itself, but the permissions are maintained at subscription, resource group, management group level or resource level.
In each RBAC we have Actions which basically tells the role what it can perform.
The actions are part of the control plane. Which you get access to manage the service and its settings or configurations. We also have data plane actions. Which provides you the actual data access. Let us take an example of Azure Blob storage, if you get reader role you would be able to see the resource itself but will not be able to see the actual data in blob storage if you authenticate via Azure AD. If you want to see the actual data, then you can get storage blob data contributor role assigned to the ID and you can see the actual data. Similarly, there are services which expose data actions e.g. Azure Key vault, Service Bus.
Getting into where this RBAC roles can be assigned at Resource, Resource Group level or management group level is another discussion which I will cover in another blog post.
Azure AD Roles
This is used when you deal with Azure AD itself or services of which roles are stored in Azure AD like SharePoint, Exchange, or Dynamics 365. Dealing with Azure AD roles might be required during multiple instances, for example using service which creates service principals in the backend like app registration. Azure Migrate, Site recovery etc. would require Azure AD permissions to be assigned to your ID.
This RBAC Domain is separate from the Azure RBAC, this gets stored in Azure AD itself and managed centrally from roles and administrator’s blade.
The person who created the tenant gets a global admin role and then we have fine grained access based on the roles.
Though Azure AD roles are different than Azure RBAC which we assign to subscriptions, a global admin can elevate himself and get access to all the subscriptions in his tenant through a toggle.
Once you enable this toggle you get the user access administrator role at the root scope under which all the management group gets created. So eventually you can access all the subscriptions.
This is a rare and exceptional procedure that requires consultation with your internal team and a clear justification for its activation.
EA RBAC
If you are an enterprise customer and have signed up for the EA Agreement from Microsoft, as a customer in order to create subscriptions and manage billing you need to log on to EA portal which is now moved to Azure portal. Hence we’ve set of 6 RBAC permissions which can be used from cost management + billing section in Azure portal.
Enterprise administrator
EA purchaser
Department administrator
Account owner
Service administrator
Notification contact
Which set of permission is assigned at specific hierarchy can be explained through the below image. this is copied from Microsoft learn documentation mentioned below.
Below is the sample screenshot which you see when you click on cost management + billing portal. Here you will see Accounts, Departments, subscriptions.
MCA RBAC
If you have purchased MCA, then you get hierarchy for permissions to be assigned. Top level permissions are assigned at the billing scope and then billing profile level.
Billing account owner and Billing profile owner are the most common role you will use. More roles are mentioned in the article below which you can go through.
Reserved Instance RBAC
A common request from customers I get, I have got contributor/owner access to the subscription still I do not see the reserved Instance which is purchased by my colleague. Few years back the person who purchased reservation used to be the one who provided access to others by going to individual reservation. This is still possible but now you can get access to all reservations in the tenant.
Reservations when purchased by an admin he can see/manage it and seen by EA Admin or a person with reservation administrator role.
You can do this via PowerShell too, check this document for more information.
More information regarding who got access to RI is mentioned in the article below.
This article is contributed. See the original author and article here.
Hack Together: The Microsoft Fabric Global AI Hack
The Microsoft Fabric Global AI Hack is your playground for creating and experimenting with Microsoft Fabric. With mentorship from Microsoft experts and access to the latest tech, you will learn how to build AI solutions with Microsoft Fabric! The possibilities are endless for what you can create… plus you can submit your hack for a chance to win exciting prizes! ?
Learn how to create amazing apps with RAG and Azure Open AI
Are you ready to hack and build a RAG Application using Fabric and Azure Open AI?
?Join us for the Fabric AI Hack Together event and learn the concepts behind RAG and how to use them effectively to empower with your data with AI.
? You’ll get to hear from our own experts Pamela Fox (Principal Cloud Advocate at Microsoft) and Alvaro Videla Godoy (Senior Cloud Advocate at Microsoft) who will introduce you to the challenge, provide links to get started, and give you ideas an inspiration so you can start creating amazing AI solutions with minimal code and maximum impact. :fire:
?? You’ll also get to network with other hackers, mentors, and experts who will help you along the way. Come with ideas or come for inspiration, we’d love to hear what you’re planning to build!
This article is contributed. See the original author and article here.
If you’re using Azure Database for MySQL and have encountered issues with name resolution or the Domain Name System (DNS) when attempting to connect to your server from different sources and networks, then this blog post is for you! In the next sections, I’ll explain the causes of these types of issues and what you need to do to resolve them.
What are DNS issues?
DNS is a service that translates domain names (e.g., servername.mysql.database.azure.com) into IP addresses (e.g., 10.0.0.4) to make it easier for us to identify remember and access websites and servers.
However, at time the DNS service can fail to resolve the domain name to the IP address, or it might resolve it to the wrong IP address. This can result in errors such as “Host not Known” or “Unknown host” when you specify the server name for making connections.
Diagnosing DNS issues
To diagnose DNS issues, use tools such as Ping or nslookup to verify that the host name is being resolved from the source. To test using ping, for example, on the source, run the following command:
ping servername.mysql.database.azure.com
If the server’s name is not resolving, a response similar to the following should appear:
Fig 1: Ping request not returning IP
To test using nslookup, on the source, run the following command:
nslookup servername.mysql.database.azure.com
Again, if the server name is not resolving, a response similar to the following should appear:
Fig 2: nslookup to DNS request not returning IP
If on the other hand the commands return the correct IP address of the server, then the DNS resolution is working properly. If the commands return an error or a different IP address, then there is a DNS issue.
To verify the correct IP address of the server, you can check the Private DNS zone of the Azure Database for MySQL Flexible server. The Private DNS zone is a service that provides name resolution for private endpoints within a virtual network (vNet). You can find the Private DNS zone in the properties of the overview blade of the server, as shown in the following figure:
Fig 3: Checking the private DNS zone in the Properties of overview blade
In the Private DNS zone, you can see the currently assigned IP address to the MySQL Flexible server, as shown in the following figure:
Fig 4: Private DNS Zone overview
Resolving DNS issues
The solution to fix DNS issues depends on the source and the network configuration of the server. In this blog, I will cover two common scenarios: when the source is using the default (Azure-provided) DNS, and when the source is using a custom DNS.
Scenario 1: Source is using the default (Azure-provided) DNS
The default (Azure-provided) DNS can only be used by sources in Azure that have private endpoint, vNet integration, or have IPs defined from a vNet. If you are using the default DNS and you are getting a DNS issue, you need to check the following:
vNet of the source: Check the vNet of the source (also check NIC level configuration in case of Azure VM) and make sure that it is set to Azure-provided DNS. You can check this on the vNet > DNS servers blade, as shown in the following figure:
Fig 5: DNS servers blade in virtual network
Private DNS zone of the server: Go to the Private DNS zone of the MySQL Flexible server and add the vNet of the source to the Virtual Network Link blade, as shown in the following figure:
Fig 6: Adding virtual network link to private DNS zone
After these steps, you should be able to ping and nslookup the server’s name from the source and get the correct IP address.
Scenario 2: Source is using a custom DNS
This is the most commonly used scenario by the users. This pattern can be used in a hub-and-spoke model and also for name resolution from on-premises servers. In this scenario, a custom DNS server is deployed in a hub vNet that is linked to the on-premises DNS server. It can also be deployed without having on-prem connectivity, as shown in the following figure:
Fig 7: Network diagram showing access through custom DNS server in Hub and Spoke network.
In this scenario, the MySQL Flexible server is deployed in a delegated subnet in Spoke2. Spoke1, Spoke2, and Spoke3 are connected through the Hub vNet. Spoke1 and Spoke3 have a custom DNS server configured which is deployed in the Hub vNet. Since both spoke vNets (1 and 3) are connected through the Hub vNet, clients can directly connect with the MySQL Flexible server with IP address only and DNS name resolution would not work.
To fix this issue, perform the following steps:
Conditional forwarder: Add a conditional forwarder on the custom DNS for mysql.database.azure.com domain. This conditional forwarder must point to the Azure DNS IP address: 168.63.129.16, as shown in the following figure:
Fig 8: Adding conditional forwarder for mysql.database.azure.com
Virtual network link: You need to add a virtual network link in the Private DNS zone for the custom DNS server’s vNet, as described in the previous scenario.
On-premises DNS: If you have clients on-premises that need to connect to the Flexible server FQDN, then you need to add a conditional forwarder in the on-premises DNS server pointing to the IP address of the custom DNS server in Azure for mysql.database.azure.com. Alternatively, you can use the same custom DNS IP in additional DNS servers on on-premises clients.
Conclusion
In this blog, I have shown you how to solve DNS issues with Azure Database for MySQL using different DNS scenarios. I hope this helps you to enjoy the benefits of using Azure Database for MySQL for your applications.
We are always interested in how you plan to use Flexible Server deployment options to drive innovation to your business and applications. Additional information on topics discussed above can be found in the following documents:
























































Recent Comments