
by Contributed | Feb 19, 2024 | Dynamics 365, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Last year, we released a revolutionary set of Copilot capabilities within Dynamics 365 Customer Service. With Copilot, agents can get quick answers, draft emails, and summarize cases and conversations using information that already exists in Dynamics 365, as well as your preferred data sources.
Now there’s Copilot for Service, which lets you connect all your data sources without replacing your existing CRM. Just like Copilot in Dynamics 365 Customer Service, Copilot for Service enables agents to easily manage customer inquiries, track service requests, and provide personalized support. It integrates Microsoft 365 experiences with external systems, such as Salesforce, Zendesk, and ServiceNow.
Why Copilot for Service is the right solution
Today, it is possible to build your own copilots using Copilot Studio, formerly known as Power Virtual Agents. With Copilot Studio, you can create a bot that addresses a specific topic (for example, “get order status”) or you can use plugins to leverage copilots and bots you have already built. Plugins let you connect to external data sources, and you can use them across Copilots to ensure agents have a consistent experience anywhere they ask a service-related question. Agents don’t have to move between systems to find answers, which reduces the time to resolution.
Customers can use Copilot Studio within Copilot for Service to customize and publish plugins for Copilot for Microsoft 365. For example, you can use Copilot Studio to add proprietary knowledge bases for the copilot’s real-time responses or set up authentication to ensure only authorized agents can use Copilot. Building and publishing standalone Copilot experiences for any internal or external channel requires a standalone Copilot Studio license.
Copilot for Service removes the development overhead and will build specific copilot experiences tailored to your organization’s needs. Additionally, if you’re already using Copilot for Microsoft 365, it’s easy to extend it with role-based capabilities for agents through prebuilt connectors to other CRMs.
Try Copilot for Service features
This month, we’re releasing four new features in preview:
- Draft an email response in Outlook: Agents can select from the predefined intents for the email to be drafted and provide their own custom intent. Copilot uses the context of the email conversation and case details to produce personalized and contextual emails.
- Email summary in Outlook: Copilot provides an email summary capturing all the important information for agents to understand the context of the case they’re working on. Agents can save the generated summary to the connected CRM system.
- Case summary in Outlook: Agents can access case summaries as they work on emails from customers. They can also save the case summary to the CRM system.
- Meeting recap in Teams: Copilot provides a meeting summary and action items that integrate with the Teams recap, providing all the relevant follow-up items. Agents can also create CRM tasks right from the Teams recap section.
Get started with Copilot for Service
First, create a copilot instance in your environment by navigating to https://servicecopilot.microsoft.com/ and following the prompts. You need to give it a name, a description, and a target system that you want to connect to. For example, you can create a copilot named Microsoft that can access information from Salesforce. The portal will then guide you through creating the connection and deploying the copilot.
The second step is to test your copilot in the demo agent desktop that is automatically generated for you. You can ask your copilot questions related to the target system, such as “What products does Microsoft sell?” or “How do I create a case in Salesforce?”
In summary, Microsoft Copilot for Service is a powerful tool that can help your agents provide better support to your customers. By leveraging the power of AI, it can provide quick and accurate answers to common questions, freeing up your agents to focus on more complex issues. To learn more, be sure to check out the partner workshop and try it out for yourself.
Learn more
For pricing information, see Microsoft Copilot for Service—Contact Center AI | Microsoft AI
Extend Copilot for Service with Copilot Studio: Extend your agent-facing copilot | Microsoft Learn
Overview of Copilot for Microsoft 365: Copilot for Microsoft 365 – Microsoft Adoption
If you are a Dynamics 365 Customer Service user, you can start using Copilot capabilities right away: Enable Copilot features in Customer Service | Microsoft Learn
The post Use Microsoft Copilot for Service with your external CRM appeared first on Microsoft Dynamics 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

by Contributed | Feb 19, 2024 | Technology
This article is contributed. See the original author and article here.
How should your Tier 0 Protection look like?
Almost every attack on Active Directory you hear about today – no matter if ransomware is involved or not – (ab)uses credential theft techniques as the key factor for successful compromise. Microsoft’s State of Cybercrime report confirms this statement: “The top finding among ransomware incident response engagements was insufficient privilege access and lateral movement controls.”
Despite the fantastic capabilities of modern detection and protection tools (like the Microsoft Defender family of products), we should not forget that prevention is always better than cure (which means that accounts should be protected against credential theft proactively). Microsoft’s approach to achieving this goal is the Enterprise Access Model. It adds the aspect of hybrid and multi-cloud identities to the Active Directory Administrative Tier Model. Although first published almost 10 years ago, the AD Administrative Tier Model is still not obsolete. Not having it in place and enforced is extremely risky with today’s threat level in mind.
Most attackers follow playbooks and whatever their final goal may be, Active Directory Domain domination (Tier 0 compromise) is a stopover in almost every attack. Hence, securing Tier 0 is the first critical step towards your Active Directory hardening journey and this article was written to help with it.
AD Administrative Tier Model Refresher
The AD Administrative Tier Model prevents escalation of privilege by restricting what Administrators can control and where they can log on. In the context of protecting Tier 0, the latter ensures that Tier 0 credentials cannot be exposed to a system belonging to another Tier (Tier 1 or Tier 2).
Tier 0 includes accounts (Admins-, service- and computer-accounts, groups) that have direct or indirect administrative control over all AD-related identities and identity management systems. While direct administrative control is easy to identify (e.g. members of Domain Admins group), indirect control can be hard to spot: e.g. think of a virtualized Domain Controller and what the admin of the virtualization host can do to it, like dumping the memory or copying the Domain Controller’s hard disk with all the password hashes. Consequently, virtualization environments hosting Tier 0 computers are Tier 0 systems as well. This also applies to the virtualization Admin accounts.
The three Commandments of AD Administrative Tier Model
Rule #1: Credentials from a higher-privileged tier (e.g. Tier 0 Admin or Service account) must not be exposed to lower-tier systems (e.g. Tier 1 or Tier 2 systems).
Rule #2: Lower-tier credentials can use services provided by higher-tiers, but not the other way around. E.g. Tier 1 and even Tier 2 system still must be able to apply Group Policies.
Rule #3: Any system or user account that can manage a higher tier is also a member of that tier, whether originally intended or not.

Implementing the AD Administrative Tier Model
Most guides describe how to achieve these goals by implementing a complex cascade of Group Policies (The local computer configuration must be changed to avoid that higher Tier level administrators can expose their credentials to a down-level computer). This comes with the downside that Group Policies can be bypassed by local administrators and that the Tier Level restriction works only on Active Directory joined Windows computers. The bad news is that there is still no click-once deployment for Tiered Administration, but there is a more robust way to get things done by implementing Authentication policies. Authentication Policies provide a way to contain high-privilege credentials to systems that are only pertinent to selected users, computers, or services. With these capabilities, you can limit Tier 0 account usage to Tier 0 hosts. That’s exactly what we need to achieve to protect Tier 0 identities from credential theft-based attacks.
To be very clear on this: With Kerberos Authentication Policies you can define a claim which defines where the user is allowed to request a Kerberos Granting Ticket from.
Optional: Deep Dive in Authentication Policies
Authentication Policies are based on a Kerberos extension called FAST (Flexible Authentication Secure Tunneling) or Kerberos Armoring. FAST provides a protected channel between the Kerberos client and the KDC for the whole pre-authentication conversation by encrypting the pre-authentication messages with a so-called armor key and by ensuring the integrity of the messages.
Kerberos Armoring is disabled by default and must be enabled using Group Policies. Once enabled, it provides the following functionality:
- Protection against offline dictionary attacks. Kerberos armoring protects the user’s pre-authentication data (which is vulnerable to offline dictionary attacks when it is generated from a password).
- Authenticated Kerberos errors. Kerberos armoring protects user Kerberos authentications from KDC Kerberos error spoofing, which can downgrade to NTLM or weaker cryptography.
- Disables any authentication protocol except Kerberos for the configured user.
- Compounded authentication in Dynamic Access Control (DAC). This allows authorization based on the combination of both user claims and device claims.
The last bullet point provides the basis for the feature we plan to use for protecting Tier 0: Authentication Policies.
Restricting user logon from specific hosts requires the Domain Controller (specifically the Key Distribution Center (KDC)) to validate the host’s identity. When using Kerberos authentication with Kerberos armoring, the KDC is provided with the TGT of the host from which the user is authenticating. That’s what we call an armored TGT, the content of which is used to complete an access check to determine if the host is allowed.

Kerberos armoring logon flow (simplified):
- The computer has already received an armored TGT during computer authentication to the domain.
- The user logs on to the computer:
- An unarmored AS-REQ for a TGT is sent to the KDC.
- The KDC queries for the user account in Active Directory and determines if it is configured with an Authentication Policy that restricts initial authentication that requires armored requests.
- The KDC fails the request and asks for Pre-Authentication.
- Windows detects that the domain supports Kerberos armoring and sends an armored AS-REQ to retry the sign-in request.
- The KDC performs an access check by using the configured access control conditions and the client operating system’s identity information in the TGT that was used to armor the request. If the access check fails, the domain controller rejects the request.
- If the access check succeeds, the KDC replies with an armored reply (AS-REP) and the authentication process continues. The user now has an armored TGT.
Looks very much like a normal Kerberos logon? Not exactly: The main difference is the fact that the user’s TGT includes the source computer’s identity information. Requesting Service Tickets looks similar to what we described above, except that the user’s armored TGT is used for protection and restriction.
Implementing a Tier 0 OU Structure and Authentication Policy
The following steps are required to limit Tier 0 account usage (Admins and Service accounts) to Tier 0 hosts:
- Enable Kerberos Armoring (aka FAST) for DCs and all computers (or at least Tier 0 computers).
- Before creating an OU structure similar to the one pictured below, you MUST ensure that Tier 0 accounts are the only ones having sensitive permissions on the root level of the domain. Keep in mind that all ACLs configured on the root-level of fabrikam.com will be inherited by the OU called “Admin” in our example.

3. Create the following security groups:
– Tier 0 Users
– Tier 0 Computer
4. Constantly update the Authentication policy to ensure that any new T0 Admin or T0 service account is covered.
5. Ensure that any newly created T0 computer account is added to the T0 Computers security group.
6. Configure an Authentication Policy with the following parameters and enforce the Kerberos Authentication policy:
(User) Accounts |
Conditions (Computer accounts/groups) |
User Sign On |
|---|
T0 Admin accounts |
(Member of each({ENTERPRISE DOMAIN CONTROLLERS}) Or Member of any({Tier 0 computers (FABRIKAMTier 0 computers)}))
|
Kerberos only |
The screenshot below shows the relevant section of the Authentication Policy:

Find more details about how to create Authentication Policies at https://learn.microsoft.com/en-us/windows-server/identity/ad-ds/manage/how-to-configure-protected-accounts#create-a-user-account-audit-for-authentication-policy-with-adac.
Tier 0 Admin Logon Flow: Privileged Access Workstations (PAWs) are a MUST
As explained at the beginning of the article, attackers can sneak through an open (and MFA protected) RDP connection when the Admin’s client computer is compromised. To protect from this type of attack Microsoft has been recommending using PAWs since many years.
In case you ask yourself, what the advantage of restricting the source of a logon attempt through Kerberos Policies is: Most certainly you do not want your T0 Admins to RDP from their – potentially compromised – workplace computers to the DC. Instead, you want them to use a Tier 0 Administrative Jump Host or – even better – a Privileged Access Workstation. With a compromised workplace computer as a source for T0 access it would be easy for an attacker to either use a keylogger to steal the T0 Admin’s password, or to simply sneak through the RDP channel once it is open (using a simple password or MFA doesn’t make a big difference for this type of attack). Even if an attacker would be able to steal the credential of a Tier 0 user, the attacker could use those credentials from a computer which is defined in the claim. On any other computer, Active Directory will not approve a TGT, even if the user provides the correct credentials. This will give you the easy possibility to monitor the declined requests and react properly.
There are too many ways of implementing the Tier 0 Admin logon flow to describe all of them in a blog. The “classic” (some call it “old-fashioned”) approach is a domain-joined PAW which is used for T0 administrative access to Tier 0 systems.

The solution above is straightforward but does not provide any modern cloud-based security features.
“Protecting Tier 0 the modern way” not only refers to using Authentication Policies, but also leverages modern protection mechanisms provided by Azure Entra ID, like Multi-Factor-Authentication, Conditional Access or Identity Protection (to cover just the most important ones).
Our preferred way of protecting the Tier 0 logon flow is via an Intune-managed PAW and Azure Virtual Desktop because this approach is easy to implement and perfectly teams modern protection mechanisms with on-premises Active Directory:

Logon to the AVD is restricted to come from a compliant PAW device only, Authentication Policies do the rest.
Automation through PowerShell
Still sounds painful? While steps 1 – 3 (enable Kerberos FAST, create OU structure, create Tier 0 groups) of Implementing a Tier 0 OU Structure and Authentication Policy are one-time tasks, step 4 and 6 (keep group membership and Authentication policy up-to-date) have turned out to be challenging in complex, dynamic environments. That’s why Andreas Lucas (aka Kili69) has developed a PowerShell-based automation tool which …
- creates the OU structure described above (if not already exists)
- creates the security groups described above (if not already exist)
- creates the Authentication policy described above (if not already exists)
- applies the Tier 0 authentication policy to any Tier 0 user object
- removes any object from the T0 Computers group which is not located in the Tier 0 OU
- removes any user object from the default Active directory Tier 0 groups, if the Authentication policy is not applied (except Built-In Administrator, GMSA and service accounts)
Additional Comments and Recommendations
Prerequisites for implementing Kerberos Authentication Policies
Kerberos Authentication Policies were introduced in Windows Server 2012 R2, hence a Domain functional level of Windows Server 2012 R2 or higher is required for implementation.
Authentication Policy – special Settings
Require rolling NTLM secret for NTLM authentication
Configuration of this feature was moved to the properties of the domain in Active Directory Administrative Center. When enabled, for users with the “Smart card is required for interactive logon” checkbox set, a new random password will be generated according to the password policy. See https://learn.microsoft.com/en-us/windows-server/security/credentials-protection-and-management/whats-new-in-credential-protection#rolling-public-key-only-users-ntlm-secrets for more details.
Allow NTLM network authentication when user is restricted to selected devices
We do NOT recommend enabling this feature because with NTLM authentication allowed the capabilities of restricting access through Authentication Policies are reduced. In addition to that, we recommend adding privileged users to the Protected Users security group. This special group was designed to harden privileged accounts and introduces a set of protection mechanisms, one of which is making NTLM authentication impossible for the members of this group. See https://learn.microsoft.com/en-us/windows-server/security/credentials-protection-and-management/authentication-policies-and-authentication-policy-silos#about-authentication-policies for more details.
Have Breakglass Accounts in place
Break Glass accounts are emergency access accounts used to access critical systems or resources when other authentication mechanisms fail or are unavailable. In Active Directory, Break Glass accounts are used to provide emergency access to Active Directory in case normal T0 Admin accounts do not work anymore, e.g. because of a misconfigured Authentication Policy.
Clean Source Principle
The clean source principle requires all security dependencies to be as trustworthy as the object being secured. Implementation of the clean source principle is beyond the scope of this article, but explained in detail at Success criteria for privileged access strategy | Microsoft Learn.
Review ACLs on the Root-level of your Domain(s)
The security implications of an account having excessive privileges (e.g. being able to modify permissions at the root-level of the domain are massive. For that reason, before creating the new OU (named “Admin” in the description above), you must ensure that there are no excessive ACLs (Access Control List) configured on the Root-level of the domain. In addition to that, consider breaking inheritance on the OU called “Admin” in our example.

by Contributed | Feb 17, 2024 | Technology
This article is contributed. See the original author and article here.
In the previous series of articles, we learned about the basic concepts of AI agents and how to use AutoGen or Semantic Kernel combined with the Azure OpenAI Service Assistant API to build AI agent applications. For different scenarios and workflows, powerful tools need to be assembled to support the operation of the AI agent. If you only use your own tool chain in the AI agent framework to solve enterprise workflow, it will be very limited. AutoGen supports defining tool chains through Function Calling, and developers can define different methods to assemble extended business work chains. As mentioned before, Semantic Kernel has good business-based plug-in creation, management and engineering capabilities. Through AutoGen + Semantic Kernel, powerful AI agent solutions can be built.
Scenario 1 – Constructing a single AI agent for writing technical blogs

As a cloud advocate, I often need to write some technical blogs. In the past, I needed a lot of supporting materials. Although I could write some of the materials through Prompt + LLMs, some professional content might not be enough to meet the requirements. For example, I want to write based on the recorded YouTube video and the syllabus. As shown in the picture above, combine the video script and outline around the three questions as basic materials, and then start writing the blog.

Note: We need to save the data as vector first. There are many methods. You can choose to use different frameworks for embedded vector processing. Here we use Semantic Kernel combined with Qdrant. Of course, the more ideal step is to add this part to the entire technical blog writing agent, which we will introduce in the next scenario.
Because the AI agent simulates human behavior, when designing the AI agent, the steps that need to be set are the same as in my daily work.
- Find relevant content based on the question
- Set a blog title, extended content and related guidance, and write it in markdown
- Save
We can complete steps 1 and 2 through Semantic Kernel. As for step 3, we can directly use the traditional method of reading and writing files. We need to define these three functions ask, writeblog, and saveblog here. After completion, we need to configure Function Calling and set the parameters and function names corresponding to these three functions.
llm_config={
“config_list”: config_list,
“functions”: [
{
“name”: “ask”,
“description”: “ask question about Machine Learning, get basic knowledge”,
“parameters”: {
“type”: “object”,
“properties”: {
“question”: {
“type”: “string”,
“description”: “About Machine Learning”,
}
},
“required”: [“question”],
},
},
{
“name”: “writeblog”,
“description”: “write blogs in markdown format”,
“parameters”: {
“type”: “object”,
“properties”: {
“content”: {
“type”: “string”,
“description”: “basic content”,
}
},
“required”: [“content”],
},
},
{
“name”: “saveblog”,
“description”: “save blogs”,
“parameters”: {
“type”: “object”,
“properties”: {
“blog”: {
“type”: “string”,
“description”: “basic content”,
}
},
“required”: [“blog”],
},
}
],
}
Because this is a single AI agent application, we only need to define an Assistant and a UserProxy. We only need to define our goals and inform the relevant steps to run.
assistant = autogen.AssistantAgent(
name=“assistant”,
llm_config=llm_config,
)
user_proxy = autogen.UserProxyAgent(
name=“user_proxy”,
is_termination_msg=lambda x: x.get(“content”, “”) and x.get(“content”, “”).rstrip().endswith(“TERMINATE”),
human_input_mode=“NEVER”,
max_consecutive_auto_reply=10,
code_execution_config=False
)
user_proxy.register_function(
function_map={
“ask”: ask,
“writeblog”: writeblog,
“saveblog”: saveblog
}
)
with Cache.disk():
await user_proxy.a_initiate_chat(
assistant,
message=“””
I’m writing a blog about Machine Learning. Find the answers to the 3 questions below and write an introduction based on them. After preparing these basic materials, write a blog and save it.
1. What is Machine Learning?
2. The difference between AI and ML
3. The history of Machine Learning
Let’s go
““”
)
We tried running it and it worked fine. For specific effects, please refer to:
Scenario 2 – Building a multi-agent interactive technical blog editor solution.
In the above scenario, we successfully built a single AI agent for technical blog writing. We hope that our technology will be more intelligent. From content search to writing and saving to translation, it is all completed through AI agent interaction. We can use different job roles to achieve this goal. This can be done by generating code from LLMs in AutoGen, but the uncertainty of this is a bit high. Therefore, it is more reliable to define additional methods through Function Calling to ensure the accuracy of the call. The following is a structural diagram of the division of labor roles:

Notice
Admin – Define various operations through UserProxy, including the most important methods.
Collector KB Assistant – Responsible for downloading relevant subtitle scripts of technical videos from YouTube, saving them locally, and vectorizing them by extracting different knowledge points and saving them to the vector database. Here I only made a video subtitle script. You can also add local documents and support for different types of audio files.
Blog Editor Assistant – When the data collection assistant completes its work, it can hand over the work to the blog writing assistant, who will write the blog as required based on a simple question outline (title setting, content expansion, and usage markdown format, etc.), and automatically save the blog to the local after writing.
Translation Assistant – Responsible for the translation of blogs in different languages. What I am talking about here is translating Chinese (can be expanded to support more languages)
Based on the above division of labor, we need to define different methods to support it. At this time, we can use SK to complete related operations.
Here we use AutoGen’s group chat mode to complete related blog work. You can clearly see that you have a team working, which is also the charm of the agent. Set it up with the following code.
groupchat = autogen.GroupChat(
agents=[user_proxy, collect_kb_assistant, blog_editor_assistant,translate_assistant], messages=[],max_round=30)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config={‘config_list’: config_list})
“””
)
The code for group chat dispatch is as follows:
await user_proxy.a_initiate_chat(
manager,
message=“””
Use this link https://www.youtube.com/watch?v=1qs6QKk0DVc as knowledge with collect knowledge assistant. Find the answers to the 3 questions below to write blog and save and save this blog to local file with blog editor assistant. And translate this blog to Chinese with translate assistant.
1. What is GitHub Copilot ?
2. How to Install GitHub Copilot ?
3. Limitations of GitHub Copilot
Let’s go
“
“”
)
Different from a single AI agent, a manager is configured to coordinate the communication work of multiple AI agents. Of course, you also need to have clear instructions to assign work.
You can view the complete code on this Repo.
If you want to see the result about English blog, you can also click this link.
If you want to see the result about Chinese blog, you can also click this link.
More
AutoGen helps us easily define different AI agents and plan how different AI agents interact and operate. The Semantic Kernel is more like a middle layer to help support different ways for agents to solve tasks, which will be of great help to enterprise scenarios. When AutoGen appears, some people may think that it overlaps with Semantic Kernel in many places. In fact, it complements and does not replace it. With the arrival of the Azure OpenAI Service Assistant API, you can believe that the agent will have stronger capabilities as the technical framework and API are improved.
Resources
- Microsoft Semantic Kernel https://github.com/microsoft/semantic-kernel
- Microsoft Autogen https://github.com/microsoft/autogen
- Microsoft Semantic Kernel CookBook https://aka.ms/SemanticKernelCookBook
- Get started using Azure OpenAI Assistants. https://learn.microsoft.com/en-us/azure/ai-services/openai/assistants-quickstart
- What is an agent? https://learn.microsoft.com/en-us/semantic-kernel/agents
- What are Memories? https://learn.microsoft.com/en-us/semantic-kernel/memories/
by Contributed | Feb 16, 2024 | Technology
This article is contributed. See the original author and article here.
There was a recent erroneous system message on Feb 14th regarding the deprecation of Azure IoT Central. The error message stated that Azure IoT Central will be deprecated on March 31st, 2027 and starting April 1, 2024, you won’t be able to create new application resources. This message is not accurate and was presented in error.
Microsoft does not communicate product retirements using system messages. When we do announce Azure product retirements, we follow our standard Azure service notification process including a notification period of 3-years before discontinuing support. We understand the importance of product retirement information for our customers’ planning and operations. Learn more about this process here: 3-Year Notification Subset – Microsoft Lifecycle | Microsoft Learn
Our goal is to provide our customers with a comprehensive, secure, and scalable IoT platform. We want to empower our customers to build and manage IoT solutions that can adapt to any scenario, across any industry, and at any scale. We see our IoT product portfolio as a key part of the adaptive cloud approach.
The adaptive cloud approach can help customers accelerate their industrial transformation journey by scaling adoption of IoT technologies. It helps unify siloed teams, distributed sites, and sprawling systems into a single operations, security, application, and data model, enabling organizations to leverage cloud-native and AI technologies to work simultaneously across hybrid, edge, and IoT. Learn more about our adaptive cloud approach here: Harmonizing AI-enhanced physical and cloud operations | Microsoft Azure Blog
Our approach is exemplified in the public preview of Azure IoT Operations, which makes it easy for customers to onboard assets and devices to flow data from physical operations to the cloud to power insights and decision making. Azure IoT Operations is designed to simplify and accelerate the development and deployment of IoT solutions, while giving you more control over your IoT devices and data. Learn more about Azure IoT Operations here: https://azure.microsoft.com/products/iot-operations/
We will continue to collaborate with our partners and customers to transform their businesses with intelligent edge and cloud solutions, taking advantage of our full portfolio of Azure IoT products.
We appreciate your trust and loyalty and look forward to continuing to serve you with our IoT platform offerings.
by Contributed | Feb 16, 2024 | Technology
This article is contributed. See the original author and article here.
Overview
A global enterprise wants to migrate thousands of Nutanix AHV or VMware vSphere virtual machines (VMs) to Microsoft Azure as part of their application modernization strategy. The first step is to exit their on-premises data centers and rapidly relocate their legacy application VMs to the Nutanix Cloud Clusters on Azure (NC2 on Azure) service as a staging area for the first phase of their modernization strategy. How can they quickly size NC2 on Azure to meet their workload requirements?
NC2 on Azure is a third-party Azure service from Nutanix that provides private clouds containing Nutanix AHV clusters built from dedicated bare-metal Azure infrastructure. It enables customers to leverage their existing investments in Nutanix skills and tools, allowing them to focus on developing and running their Nutanix-based workloads on Azure.
In this post, I will introduce the typical customer workload requirements, describe the NC2 on Azure architectural components, and describe how to use Nutanix Sizer to quickly scope an NC2 on Azure solution.
In the next section, I will introduce the typical sizing requirements of a customer’s workload.
Customer Workload Requirements
A typical customer has multiple application tiers that have specific Service Level Agreement (SLA) requirements that need to be met. These SLAs are usually named by a tiering system such as Platinum, Gold, Silver, and Bronze or Mission-Critical, Business-Critical, Production, and Test/Dev. Each SLA will have different availability, recoverability, performance, manageability, and security requirements that need to be met.
For the initial sizing, customers will have CPU, RAM, Storage and Network requirements. This is normally documented for each application and then aggregated into the total resource requirements for each SLA. For example:
SLA Name
|
CPU
|
RAM
|
Storage
|
Network
|
Gold
|
Low vCPU:pCore ratio (<1 to 2),
Low VM to Host ratio (2-8)
|
No RAM oversubscription (<1)
|
High Throughput or High IOPS (for a particular I/O size), Low Latency, Low Capacity, RAID policy, Redundancy Factor
|
High Throughput, Low Latency
|
Silver
|
Medium vCPU:pCore ratio (5 to 8),
Medium VM to Host ratio (10-15)
|
Medium RAM oversubscription ratio (1.1-1.3)
|
Medium Latency, Medium Capacity
|
Medium Latency
|
Bronze
|
High vCPU:pCore ratio (10-15), High VM to Host ratio (20+)
|
High RAM oversubscription ratio (1.5-2)
|
High Latency, High Capacity
|
High Latency
|
Table 1 – Typical Customer SLA requirements for Performance
The concepts introduced in Table 1 have the following definitions:
- CPU: CPU model and speed (this can be important for legacy single threaded applications), number of cores, vCPU to physical core ratios.
- Memory: Random Access Memory size, Input/Output (I/O) speed and latency, oversubscription ratios.
- Storage: Capacity, Read/Write Input/Output per Second (IOPS) with Input/Output (I/O) size, Read/Write Input/Output Latency, RAID policy, RF policy.
- Network: In/Out Speed, Network Latency (Round Trip Time).
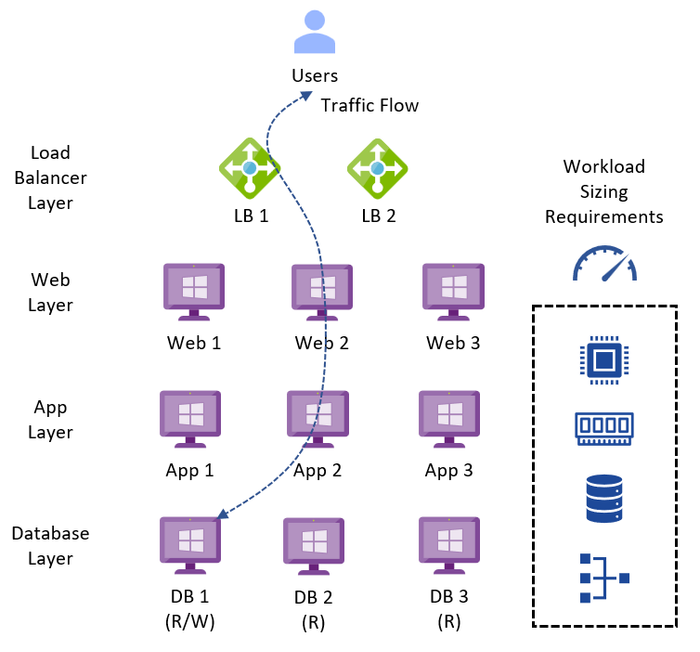
A typical legacy business-critical application will have the following application architecture:
- Load Balancer layer: Uses load balancers to distribute traffic across multiple web servers in the web layer to improve application availability.
- Web layer: Uses web servers to process client requests made via the secure Hypertext Transfer Protocol (HTTPS). Receives traffic from the load balancer layer and forwards to the application layer.
- Application layer: Uses application servers to run software that delivers a business application through a communication protocol. Receives traffic from the web layer and uses the database layer to access stored data.
- Database layer: Uses a relational database management service (RDMS) cluster to store data and provide database services to the application layer.
The application can also be classified as OLTP or OLAP, which have the following characteristics:
- Online Transaction Processing (OLTP) is a type of data processing that consists of executing several transactions occurring concurrently. For example, online banking, retail shopping, or sending text messages. OLTP systems tend to have a performance profile that is latency sensitive, choppy CPU demands, with small amounts of data being read and written.
- Online Analytical Processing (OLAP) is a technology that organizes large business databases and supports complex analysis. It can be used to perform complex analytical queries without negatively impacting transactional systems (OLTP). For example, data warehouse systems, business performance analysis, marketing analysis. OLAP systems tend to have a performance profile that is latency tolerant, requires large amounts of storage for records processing, has a steady state of CPU, RAM and storage throughput.
Depending upon the requirements for each service, the infrastructure design could be a mix of technologies used to meet the different application SLAs with cost efficiency.
Figure 1 – Typical Legacy Business-Critical Application Architecture
In the next section, I will introduce the architectural components of the NC2 on Azure service.
Architectural Components
The diagram below describes the architectural components of the NC2 on Azure service.

Figure 2 – NC2 on Azure Architectural Components
Each NC2 on Azure architectural component has the following function:
- Azure Subscription: Used to provide controlled access, budget, and quota management for the NC2 on Azure service.
- Azure Region: Physical locations around the world where we group data centers into Availability Zones (AZs) and then group AZs into regions.
- Azure Resource Group: Container used to place Azure services and resources into logical groups.
- NC2 on Azure: Uses Nutanix software, including Prism Central, Prism Element, Nutanix Flow software-defined networking, Nutanix Acropolis Operating System (AOS) software-defined storage, and Azure bare-metal Acropolis Hypervisor (AHV) hosts to provide compute, networking, and storage resources.
- Nutanix Move: Provides migration services.
- Nutanix Disaster Recovery: Provides Disaster Recovery automation and storage replication services.
- Nutanix Files: Filer services.
- Nutanix Objects: Object storage services.
- Nutanix Self Service: Application Lifecycle Management and Cloud Orchestration.
- Nutanix Cost Governance: Multi-Cloud Optimization to reduce cost & enhance Cloud Security.
- Azure Virtual Network (VNet): Private network used to connect Azure services and resources together.
- Azure Route Server: Enables network appliances to exchange dynamic route information with Azure networks.
- Azure Virtual Network Gateway: Cross premises gateway for connecting Azure services and resources to other private networks using IPSec VPN, ExpressRoute, and VNet to VNet.
- Azure ExpressRoute: Provides high-speed private connections between Azure data centers and on-premises or colocation infrastructure.
- Azure Virtual WAN (vWAN): Aggregates networking, security, and routing functions together into a single unified Wide Area Network (WAN).
In the next section, I will describe how to use the Nutanix Sizer to quickly scope the NC2 on Azure service for a customer workload.
Using the Nutanix Sizer
The Nutanix Sizer is available to Nutanix Employees and Nutanix Partners. If you are a Nutanix Customer, please reach out to your Nutanix, Microsoft, or Partner account team to engage an architect to size your NC2 on Azure solution. Customers also have access to Nutanix Sizer Basic.
Unless specified, all other settings can be left at the default values. Once the scenario is built, it can be later tweaked to meet the customer requirements.
Step 1: Access My Nutanix and select the Nutanix Sizer Launch button.

Figure 3 – My Nutanix Dashboard
Step 2: Select the Create Scenario button.

Figure 4 – Nutanix Sizer My Scenarios
Step 3: Enter the Scenario Name, Install Country, and select the Create button.

Figure 5 – Nutanix Sizer Create New Scenario
Optionally, if you have a good understanding of the problem the customer is trying to solve, you can fill out the Scenario Objectives (Executive Summary, Requirements, Constraints, Assumptions, and Risks) to start building out the design. This will also allow you to use the advanced export features at the end of the sizing process.
Step 4: Press the Add button in the Create Workloads pane. If you want Import a Nutanix Collector or RVTools files as the source file for workload, select the Import button instead.

Figure 6 – Nutanix Sizer Create Workloads
Step 5: Define the Workload Name, Workload Type, Server Profile Size, and Number of VMs. Then select the Save & Review Cluster button.

Figure 7 – Nutanix Sizer Add Workload
Step 6: Select NC2 on Azure from the Vendor section of the Platform Settings. Then scroll down to the Cluster Settings.

Figure 8 – Nutanix Sizer Platform Settings
Step 7: Select the Environment Type from the Cluster Settings and press the Apply button.

Figure 9 – Nutanix Sizer Cluster Settings
Step 8: In the Workloads Summary page, select the Solution tab.

Figure 10 – Nutanix Sizer Workloads Summary
Step 9: In the Solution Summary page, verify the NC2 on Azure tag is present in each cluster.

Figure 11 – Nutanix Sizer Solution Summary
Step 10: In the Solution Summary page, scroll down to the Sizing Details for the detailed breakdown.

Figure 12 – Nutanix Sizer Solution Sizing Details
Step 11: To share the Scenario with others:
- Select BOM, Download BOM
- Select Quote, Generate Budgetary Quote or Generate Frontline Quote
- Select More, Share Scenario or Create Proposal

Figure 13 – Nutanix Sizer Export & Sharing Options
In the following section, I will describe the next steps that need to be made to progress this high-level design estimate towards a validated detailed design.
Next Steps
The NC2 on Azure sizing estimate has been assessed using Nutanix Sizer. With large enterprise solutions for strategic and major customers, a Nutanix Solutions Architect from Azure, Nutanix, or a trusted Nutanix Partner should be engaged to ensure the solution is correctly sized to deliver business value with the minimum of risk. This should also include an application dependency assessment to understand the mapping between application groups and identify areas of data gravity, application network traffic flows, and network latency dependencies.
Summary
In this post, we took a closer look at the typical sizing requirements of a customer workload, the architectural building blocks, and the use of Nutanix Sizer to quickly scope the NC2 on Azure service. We also discussed the next steps to continue an NC2 on Azure design.
If you are interested in NC2 on Azure, please use these resources to learn more about the service:
Author Bio
René van den Bedem is a Principal Technical Program Manager at Microsoft. His background is in enterprise architecture with extensive experience across all facets of the enterprise, public cloud & service provider spaces, including digital transformation and the business, enterprise, and technology architecture stacks. René works backwards from the problem to be solved and designs solutions that deliver business value with the minimum of risk. In addition to being the first quadruple VMware Certified Design Expert (VCDX), he is also a Dell Technologies Certified Master Enterprise Architect, a Nutanix Platform Expert (NPX), an NPX Panelist, and a Nutanix Technology Champion.

Recent Comments