This article is contributed. See the original author and article here.
Pursuant to Section 8 of Executive Order (EO) 14028, “Improving the Nation’s Cybersecurity”, Federal Chief Information Officers (CIOs) and Chief Information Security Officers (CISOs) aim to comply with the U.S. Office of Management and Budget (OMB) Memorandum 21-31, which centers on system logs for services both within authorization boundaries and deployed on Cloud Service Offerings (CSOs). This memorandum not only instructs Federal agencies to provide clear guidelines for service providers but also offers comprehensive recommendations on logging, retention, and management to increase the Government’s visibility before, during and after a cybersecurity incident. Additionally, OMB Memorandum 22-09, “Moving the U.S. Government Toward Zero Trust Cybersecurity Principles”, references M-21-31 in its Section 3.
While planning to address and execute these requirements, Federal CIO and CISO should explore the use of Cyber Data Lake (CDL). A CDL is a capability to assimilate and house vast quantities of security data, whether in its raw form or as derivatives of original logs. Thanks to its adaptable, scalable design, a CDL can encompass data of any nature, be it structured, semi-structured, or unstructured, all without compromising quality. This article probes into the philosophy behind the Federal CDL, exploring topics such as:
The Importance of CDL for Agency Missions and Business
Strategy and Approach
CDL Infrastructure
Application of CDL
The Importance of CDL for Agency Missions and Business
The overall reduction in both capital and operational expenditures for hardware and software, combined with enhanced data management capabilities, makes CDLs an economically viable solution for organizations looking to optimize their data handling and security strategies. CDLs are cost-effective due to their ability to consolidate various data types and sources into a single platform, eliminating the need for multiple, specialized data management tools. This consolidation reduces infrastructure and maintenance costs significantly. CDLs also adapt easily to increasing data volumes, allowing for scalable storage solutions without the need for expensive infrastructure upgrades. By enabling advanced analytics and efficient data processing, they reduce the time and resources needed for data analysis, further cutting operational costs. Additionally, improved accuracy in threat detection and reduction in false positives lead to more efficient security operations, minimizing the expenses associated with responding to erroneous alerts and increasing the speed of detection and remediation.
However, CDLs are not without challenges. As technological advancements and the big data paradigm evolve, the complexity of network, enterprise, and system architecture escalates. This complexity is further exacerbated by the integration of tools from various vendors into Federal ecosystem, managed by diverse internal and external teams. For security professionals, maintaining pace with this intricate environment and achieving real-time transparency into technological activities is becoming an uphill battle. These professionals require a dependable, almost instantaneous source that adheres to the National Institute of Standards and Technology (NIST) core functions—identify, protect, detect, respond, and recover. Such a source empowers them to strategize, prioritize, and address any anomalies or shifts in their security stance. The present challenge lies in acquiring a holistic view of security risk, especially when large agencies might deploy hundreds of applications across the US and in some cases globally. The security data logs, scattered across these applications, clouds and environments, often exhibit conflicting classifications or categorizations. Further complicating matters are logging maturity levels at different cloud deployment models, infrastructure, platform, and software.
It is vital to scrutinize any irregularities to ensure the environment is secure, aligning with zero-trust principles which advocate for a dual approach: never automatically trust and always operate under the assumption that breaches may occur. As security breaches become more frequent and advanced, malicious entities will employ machine learning to pinpoint vulnerabilities across expansive threat landscape. Artificial intelligence will leverage machine learning and large language models to further enhance organizations’ abilities to discover and adapt to changing risk environments, allowing security professionals to do more with less.
Strategy and Approach
The optimal approach to managing a CDL depends on several variables, including leadership, staff, services, governance, infrastructure, budget, maturity, and other factors spanning all agencies. It is debatable whether a centralized IT team can cater to the diverse needs and unique challenges of every agency. We are seeing a shift where departments are integrating multi-cloud infrastructure into their ecosystem to support the mission. An effective department strategy is pivotal for success, commencing with systems under the Federal Information Security Modernization Act (FISMA) and affiliated technological environments. Though there may be challenges at the departmental level in a federated setting, it often proves a more effective strategy than a checklist approach.
Regarding which logs to prioritize, there are several methods. CISA has published a guide on how to prioritize deployment: Guidance for Implementing M-21-31: Improving the Federal Government’s Investigative and Remediation Capabilities. Some might opt to begin with network-level logs, followed by enterprise and then system logs. Others might prioritize logs from high-value assets based on FISMA’s security categorization, from high to moderate to low. Some might start with systems that can provide logs most effortlessly, allowing them to accumulate best practices and insights before moving on to more intricate systems.
Efficiently performing analysis, enforcement, and operations across data repositories dispersed across multiple cloud locations in a departmental setting involves adopting a range of strategies. This includes data integration and aggregation, cross-cloud compatibility, API-based connectivity, metadata management, cloud orchestration, data virtualization, and the use of cloud-agnostic tools to ensure seamless data interaction. Security and compliance should be maintained consistently, while monitoring, analytics, machine learning, and AI tools can enhance visibility and automate processes. Cost optimization and ongoing evaluation are crucial, as is investing in training and skill development. By implementing these strategies, departments can effectively manage their multi-cloud infrastructure, ensuring data is accessible, secure, and cost-effective, while also leveraging advanced technologies for analysis and operations.
CDL Infrastructure
One of the significant challenges is determining how a CDL aligns with an agency’s structure. The decision between a centralized, federated, or hybrid approach arises, with cost considerations being paramount. Ingesting logs in their original form into a centralized CDL comes with its own set of challenges, including accuracy, privacy, cost, and ownership. Employing a formatting tool can lead to substantial cost savings in the extract, transform, and load (ETL) process. Several agencies have experienced cost reductions of up to 90% and significant data size reductions by incorporating formatting in tables, which can be reorganized as needed during the investigation phase. A federated approach means the logs remain in place, analyses are conducted locally, and the results are then forwarded to a centralized CDL for further evaluation and dissemination.
For larger and more complex agencies, a multi-tier CDL might be suitable. By implementing data collection rules (DCR), data can be categorized during the collection process, with department-specific information directed at the respective department’s CDL, while still ensuring that high value and timely logs are forwarded to a centralized CDL at the agency level, prioritizing privileged accounts. Each operating division or bureau could establish its own CDL, reporting on to the agency’s headquarters’ CDL. The agency’s Office of Inspector General (OIG) or a statistical component of a department may need to create their own independent CDL for independence purposes. This agency HQ CDL would then report to DHS. In contrast, smaller agencies might only need a single CDL. This could integrate with the existing Cloud Log Aggregation Warehouse (CLAW) a CISA-deployed architecture for collecting and aggregating security telemetry data from agencies using commercial CSP services — and align with the National Cybersecurity Protection System (NCPS) Cloud Interface Reference Architecture. This program ensures security data from cloud-based traffic is captured, analyzed, and enables CISA analysts to maintain situational awareness and provide support to agencies.
If data is consolidated in a central monolithic, stringent data stewardship is crucial, especially concerning data segmentation, access controls, and classification. Data segmentation provides granular access control based on a need-to-know approach, with mechanisms such as encryption, authorization, access audits, firewalls, and tagging. If constructed correctly, this can eliminate the need for separate CDL infrastructures for independent organizations. This should be compatible with role-based user access schemes, segment data based on sensitivity or criticality, and meet Federal authentication standards. This supports Zero Trust initiatives in Federal agencies and aligns with Federal cybersecurity regulations, data privacy laws, and current TLS encryption standards. Data must also adhere to retention standards outlined in OMB 21-31 Appendix C and the latest National Archives and Records Administration (NARA) publications, and comply with Data Loss Prevention requirements, covering data at rest, in transit, and at endpoints, in line with NIST 800-53 Revision 5.
In certain scenarios, data might require reclassification or recategorization based on its need-to-know status. Agencies must consider storage capabilities, ensuring they have a scalable, redundant and highly available storage system that can handle vast amounts of varied data, from structured to unstructured formats. Other considerations include interoperability, migrating an existing enterprise CDL to another platform, integrating with legacy systems, and supporting multi-cloud enterprise architectures that source data from a range of CSPs and physical locations. When considering data portability, the ease of transferring data between different platforms or services is crucial. This necessitates storing data in widely recognized formats and ensuring it remains accessible. Moreover, the administrative efforts involved in segmenting and classifying the data should also be considered.
Beyond cost and feasibility, the CDL model also provides the opportunity for CIOs and CISOs to achieve data dominance with their security and log data. This concept of data dominance allows them to gather data, quickly and securely, reduces processing time, which provides quicker time to respond. This quicker time to respond, the strategic goal of any security implementation, is only possible with the appropriate platform and infrastructure so organizations can get closer to real-time situational awareness.
The Application of CDL
With a solid strategy in place, it’s time to delve into the application of a CDL. Questions arise about its operation, making it actionable, its placement relative to the Security Operations Center (SOC), and potential integrations with agency Governance Risk Management, and Compliance (GRC) tools and other monitoring systems. A mature security program needs a comprehensive real-time view of an agency’s security posture, encompassing SOC activities and the agency’s governance, risk management, and compliance tasks. The CDL should interface seamlessly with existing or future Security Orchestration and Response (SOAR) and End Point Detection (EDR) tools, as well as ticketing systems.
CDLs facilitate the sharing of analyses within their agencies, as well as with other Federal entities like the Department of Homeland Security (DHS), Cybersecurity and Infrastructure Security Agency (CISA), Federal law enforcement agencies, and intelligence agencies. Moreover, CDLs can bridge the gaps in a Federal security program, interlinking entities such as the SOC, GRC tools, and other security monitoring capabilities. At the highest levels of maturity, the CDL will leverage Network Operations Center (NOC) and even potentially administration information such as employee leave schedules. The benefit of modernizing the CDL lies in eliminating the requirement to segregate data before ingestion. Data is no longer categorized as security-specific or operations-specific. Instead, it is centralized into a single location, allowing CDL tools and models to assess the data’s significance. Monolithic technology stacks are effective when all workloads are in the same cloud environment. However, in a multi-cloud infrastructure, this approach becomes challenging. With workloads spread across different clouds, selecting one as a central hub incurs egress costs to transfer log data between clouds. Departments are exploring options to store data in the cloud where it’s generated, while also considering if Cloud Service Providers (CSPs) offer tools for analysis, visibility, machine learning, and artificial intelligence.
The next step is for agencies to send actionable information to security personnel regarding potential incidents and provide mission owners with the intelligence necessary to enhance efficiency. Additionally, this approach eliminates the creation of separate silos for security data, mission data, financial information, and operations data. This integration extends to other Federal security initiatives such as Continuous Diagnostics and Mitigation (CDM), Authority to Operate (ATO), Trusted Internet Connection (TIC), and the Federal Risk and Authorization Management Program (FedRAMP).
It’s also pivotal to determine if the CDL aligns with the MITRE ATT&CK Framework, which can significantly assist in incident response. MITRE ATT&CK® is a public knowledge base outlining adversary tactics and techniques based on observed events. The knowledge base aids in developing specific threat models and methodologies across various sectors.
Lastly, to gauge the CDL’s applicability, one might consider creating a test case. Given the vast amount of log data — since logs are perpetual — this presents an ideal scenario for machine learning. Achieving real-time visibility can be challenging with the multiple layers of log aggregation, but timely insights might be within reach. For more resources from Microsoft Federal Security, please visit https://aka.ms/FedCyber.
Stay Connected
Connect with the Public Sector community to keep the conversation going, exchange tips and tricks, and join community events. Click “Join” to become a member and follow or subscribe to the Public Sector Blog spaceto get the most recent updates and news directly from the product teams.
This article is contributed. See the original author and article here.
If you are looking for a step-by-step guide on how to enable authentication for your Azure Kubernetes Service (AKS) cluster, you may have encountered some challenges. The documentation on this topic is scarce and often outdated or incomplete. Moreover, you may have specific requirements for your use case that are not covered by the existing resources. That is why I have created this comprehensive guide using the latest Azure cloud resources.
In this guide, you will learn how to set up an AKS cluster and provide authentication to that cluster using NGINX and the OAuth2 proxy. This guide is intended for educational purposes only and does not guarantee proper authentication as certified by NIST. It is also not a complete solution for securing your AKS cluster, which involves more than just authentication. Therefore, this guide should be used as a learning tool to help you understand how authentication works and how to implement it using Azure.
By following this guide, you will be able to set up an AKS cluster with authentication using NGINX, OAuth2 Proxy, and Microsoft Entra ID. You will not need a domain name as we will use a fully qualified domain name (FQDN). However, you can also use a domain name if you prefer. Additionally, we will use Let’s Encrypt for TLS certificates so that our application will use HTTPS.
Additionally, I have broken this guide into several parts. This is the first part where you will be guided through the creation of your AKS cluster and the initial NGINX configuration. I will provide the remaining parts in future posts.
To learn how to use NGINX with Oauth2 Proxy, I conducted thorough online research and consulted various tutorials, guides, and other sources of information. The following list contains some of the most helpful references that I used to create this guide. You may find them useful as well if you need more details or clarification on any aspect of this topic.
Before you begin, you will need to meet the following prerequisites:
Azure CLI or Azure PowerShell
An Azure subscription
An Azure Resource Group
Create an Azure Container Registry (ACR)
To create an Azure container registry, you can follow the steps outlined in the official documentation here Create a new ACR. An Azure container registry is a managed Docker registry service that allows you to store and manage your private Docker container images and related artifacts. For now I’ll set up an ACR using PowerShell:
The command above will configure the appropriate AcrPull role for the managed identity and allows you to authorize an existing ACR in your subscription. A managed identity from Microsoft Entra ID allows your app to easily access other Microsoft Entra protected resources.
Validate the Deployment
We will verify the deployment using the Kubernetes command line client. Ensure that you have this tool installed by running the following command.
Install-Module Az.Aks
Configure the kubectl client to connect to your Kubernetes cluster. The following command downloads credentials and configures the Kubernetes CLU to use them.
Verify the connection to your cluster by running the following command.
kubectl get nodes
You should see some output with the name of the nodes on your cluster.
NGINX Ingress controller configuration
Now that we have our AKS cluster up and running with an attached ACR we can configure our ingress controller NGINX. The NGINX ingress controller provides a reverse proxy for configurable traffic routing and TLS termination. We will utilize NGINX to fence off our AKS cluster providing a public IP address accessible through the load balancer which we can then assign a FQDN for accessing our applications. Additionally, we can configure NGINX to integrate with Microsoft Entra ID for authenticating users via an OAuth2 Proxy. Those details will be shared in a later post. You can follow the basic configuration for an ingress controller on the official documentation here Create an unmanaged ingress controller.
Before configuration begins, make sure you have Helm installed. Then run the following commands.
Now that you have configured and installed the NGINX ingress controller you can check the load balancer. Run the following command.
kubectl get services --namespace ingress-basic -o wide -w ingress-nginx-controller
You should see some output. When Kubernetes creates the load balancer service a public IP address is assigned. You can view the IP address under the column EXTERNAL-IP. Make note of this IP address. If you browse to that IP address you should get a 404 Not Found.
This wraps up the first part of this series. In the next part I will go over deploying two applications and creating the ingress routes to route to the applications. Then we will move on to setting up cert manager and getting things ready for our OAuth2 Proxy provider.
This article is contributed. See the original author and article here.
Developers across the world are building innovative generative AI solutions since the launch of Azure OpenAI Service in January 2023. Over 53,000 customers globally harness the capabilities of expansive generative AI models, supported by the robust commitments of Azure’s cloud and computing infrastructure backed by enterprise grade security.
Today, we are thrilled to announce many new capabilities, models, and pricing improvements within the service. We are launching Assistants API in public preview, new text-to-speech capabilities, upcoming updated models for GPT-4 Turbo preview and GPT-3.5 Turbo, new embeddings models and updates to the fine-tuning API, including a new model, support for continuous fine-tuning, and better pricing. Let’s explore our new offerings in detail.
Build sophisticated copilot experiences in your apps with Assistants API
We are excited to announce, Assistants, a new feature in Azure OpenAI Service, is now available in public preview. Assistants API makes it simple for developers to create high quality copilot-like experiences within their own applications. Previously, building custom AI assistants needed heavy lifting even for experienced developers. While the chat completions API is lightweight and powerful, it is inherently stateless, which means that developers had to manage conversation state and chat threads, tool integrations, retrieval documents and indexes, and execute code manually. Assistants API, as the stateful evolution of the chat completion API, provides a solution for these challenges.
Building customizable, purpose-built AI that can sift through data, suggest solutions, and automate tasks just got easier. The Assistants API supports persistent and infinitely long threads. This means that as a developer you no longer need to develop thread state management systems and work around a model’s context window constraints. Once you create a Thread, you can simply append new messages to it as users respond. Assistants can access files in several formats – either while creating an Assistant or as part of Threads. Assistants can also access multiple tools in parallel, as needed. These tools include:
Code Interpreter: This Azure OpenAI Service-hosted tool lets you write and run Python code in a sandboxed environment. Use cases include solving challenging code and math problems iteratively, performing advanced data analysis over user-added files in multiple formats and generating data visualization like charts and graphs.
Function calling: You can describe functions of your app or external APIs to your Assistant and have the model intelligently decide when to invoke those functions and incorporate the function response in its messages.
Support for new features, including an improved knowledge retrieval tool, is coming soon.
Assistants API is built on the same capabilities that power OpenAI’s GPT product and offers unparalleled flexibility for creating a wide range of copilot-like applications. Use cases range AI-powered product recommender, sales analyst app, coding assistant, employee Q&A chatbot, and more. Start building on the no-code Assistants playground on start building with the API.
As with the rest of our offerings, data and files provided by you to the Azure OpenAI Service are not used to improve OpenAI models or any Microsoft or third-party products or services, and developers can delete the data as per their needs. Learn more about data, privacy and security for Azure OpenAI Service here. We recommend using Assistants with trusted data sources. Retrieving untrusted data using Function calling, Code Interpreter with file input, and Assistant Threads functionalities could compromise the security of your Assistant, or the application that uses the Assistant. Learn about mitigation approaches here.
Fine-tuning: New model support, new capabilities, and lower prices
Since we announced Azure OpenAI Service fine-tuning for OpenAI’s Babbage-002, Davinci-002 and GPT-35-Turbo on October 16, 2023, we’ve enabled AI builders to build custom models. Today we’re releasing fine-tuning support for OpenAI’sGPT-35-Turbo 1106, a next gen GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Fine-tuning with GPT-35-Turbo 1106 supports 16k context length in training data, allowing you to fine-tune with longer messages and generate longer and more coherent texts.
In addition, we are introducing two new features to enable you to create more complex custom models and easily update them. First, we are launching support for fine-tuning with function calling that enables you to teach your custom model when to make function calls and improve the accuracy and consistency of the responses. Second, we are launching support for continuous fine-tuning, which allows you to train a previously fine-tuned model with new data, without losing the previous knowledge and performance of the model. This lets you add additional training data to an existing custom model without starting from scratch and lets you experiment more iteratively.
Besides new model support and features, we are making it more affordable for you to train and host your fine-tuned models on Azure OpenAI Service, including decreasing the cost of training and hosting GPT-35-Turbo by 50%.
Coming soon: New models and model updates
The following models and model updates are coming this month to Azure OpenAI Service. You can review the latest model availability here.
Updated GPT-4 Turbo preview and GPT-3.5 Turbo models
We are rolling out an updated GPT-4 Turbo preview model, gpt-4-0125-preview, with improvements in tasks such as code generation and reduced cases of “laziness” where the model doesn’t complete a task. The new model fixes a bug impacting non-English UTF-8 generations. Post-launch, we’ll begin updating Azure OpenAI deployments that use GPT-4 version 1106-preview to use version 0125-preview. The update will start two weeks after the launch date and complete within a week. Because version 0125-preview offers improved capabilities,customers may notice some changes in the model behavior and compatibility after the upgrade. Pricing for gpt-4-0125-preview will be same as pricing for gpt-4-1106-preview.
In addition to the updated GPT-4 Turbo, we will also be launching GPT-3.5-turbo-0125, a new GPT-3.5 Turbo model with improved pricing and higher accuracy at responding in various formats. We will reduce input prices for the new model by 50% to $0.0005 /1K tokens and output prices by 25% to $0.0015 /1K tokens.
New Text-to-Speech (TTS) models
Our new text-to-speech model generates human-quality speech from text in six preset voices, each with its own personality and style. The two model variants include tts-1, the standard voices model variant, which is optimized for real-time use cases, and tts-1-hd, the high-definition (HD) equivalent, which is optimized for quality. This new includes capabilities such as building custom voices and avatars already available in Azure AI and enables customers to build entirely new experiences across customer support, training videos, live-streaming and more. Developers can now access these voices through both services, Azure OpenAI Service and Azure AI Speech.
A new generation of embeddings models with lower pricing
Azure OpenAI Service customers have been incorporating embeddings models in their applications to personalize, recommend and search content. We are excited to announce a new generation of embeddings models that are significantly more capable and meet a variety of customer needs. These models will be available later this month.
text-embedding-3-small is a new smaller and highly efficient embeddings model that provides stronger performance compared to its predecessor text-embedding-ada-002. Given its efficiency, pricing for this model is $0.00002 per 1k tokens, a 5x price reduction compared to that of text-embedding-ada-002. We are not deprecating text-embedding-ada-002 so you can continue using the previous generation model, if needed.
text-embedding-3-large is our new best performing embeddings model that creates embeddings with up to 3072 dimensions. This large embeddings model is priced at $0.00013 / 1k tokens.
Both embeddings models offer native support for shortening embeddings (i.e. remove numbers from the end of the sequence) without the embedding losing its concept-representing properties. This allows you to make trade-off between the performance and cost of using embeddings.
What’s Next
It has been great to see what developers have built already using Azure OpenAI Service. You can further accelerate your enterprise’s AI transformation with the products we announced today. Explore the following resources to get started or learn more about Azure OpenAI Service.
Get started with Azure OpenAI Assistants (preview)
Speed up developing with the Assistants API with the code samples in the Assistants GitHub repo
This article is contributed. See the original author and article here.
In the fast-paced world of sales, sellers are now expected to be adept multitaskers. As they engage with customers, the demands of various tasks and follow-ups can quickly accumulate. Effectively managing these aspects is crucial for streamlining processes, minimizing manual intervention and significantly enhancing the overall customer experience. By staying organized and leveraging tools to keep track, sellers can meet their goals more effectively. When we released focused view in April 2023, we had precisely this goal in mind – to transform the current user experience while working on records within Dynamics 365 Sales.
Since its launch, focused view has not only achieved remarkable success but has also gained widespread user adoption. Thousands of sellers now rely on it as a swift solution to navigate records efficiently and address open tasks promptly. A closer look at our usage analysis indicated around a 50% reduction in overall task execution time compared to the current grid view for the same set of actions.
With the new enhancements, our commitment is to further elevate the overall user experience, aiming to provide a comprehensive set of capabilities within focused view. This ensures that users can accomplish all tasks seamlessly without the need to switch contexts across multiple views.
This blog delves into the introduced changes, detailing how users can leverage these updates to streamline their daily tasks.
What is focused view?
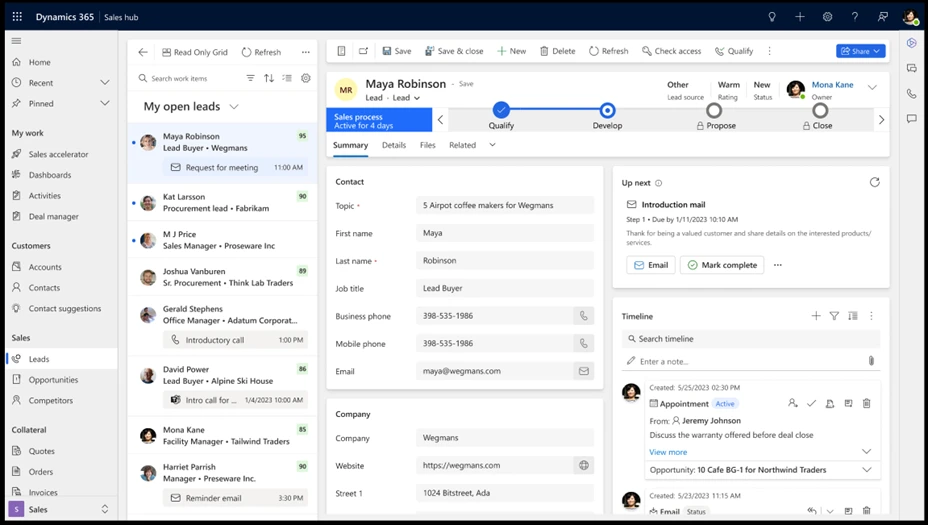
Focused view is a new work surface which allows users to view all their records as a list, while being able to work on any of them without having to switch context multiple times between the record form and the list of records. It supports easy filtering, sorting, and card customization capabilities to ensure you see the data that matters to you.
Focused view
What are the new enhancements?
Expanding the reach of focused view
As part of the current release, we are introducing focused view for Dynamics 365 entities. It’s now enabled automatically for all users, with no set up. Thus, Dynamics 365 users can leverage it for any out of the box or custom entities that they work on. Users should be able to see the focused view button or find it within the “show as” dropdown for all their entities, as the first button of the ribbon command bar.
Maintaining user preferences
We are committed to respecting our users’ preferences to ensure they always see the view they use the most first. To achieve this, our system now seamlessly retains the last-used work surface for each user every time they log into Dynamics 365 Sales. This enables users to effortlessly pick up right where they left off, regardless of any system default settings for a given entity. At our core, we prioritize our users’ individual choices, ensuring that their preferred work surface always takes the lead.
Introducing new capabilities
We are leaving no stone unturned to make focused view the ultimate work surface to cater to all our users’ needs! With the new release, we are introducing several new capabilities to ensure users can complete all their required tasks from a single place:
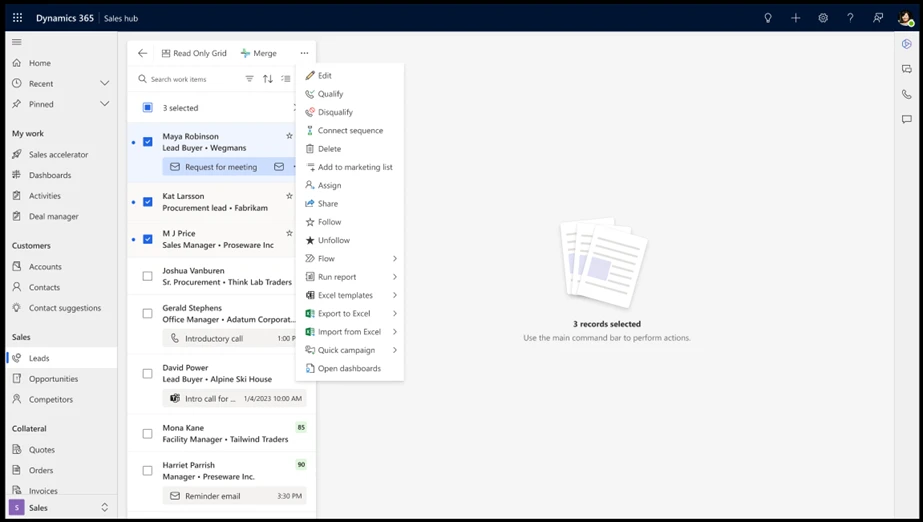
Multi-select records: With the enhanced focused view, users can now multi-select records and execute bulk functionalities in a seamless manner.
Support the view level ribbon command bar: Within the focused view, users no longer need to navigate to a grid experience to make updates. Instead, we have now made available an easy access point through the ribbon command bar. It now allows users to take instant action on any record(s) without any additional navigation.
Multi-select and ribbon command bar
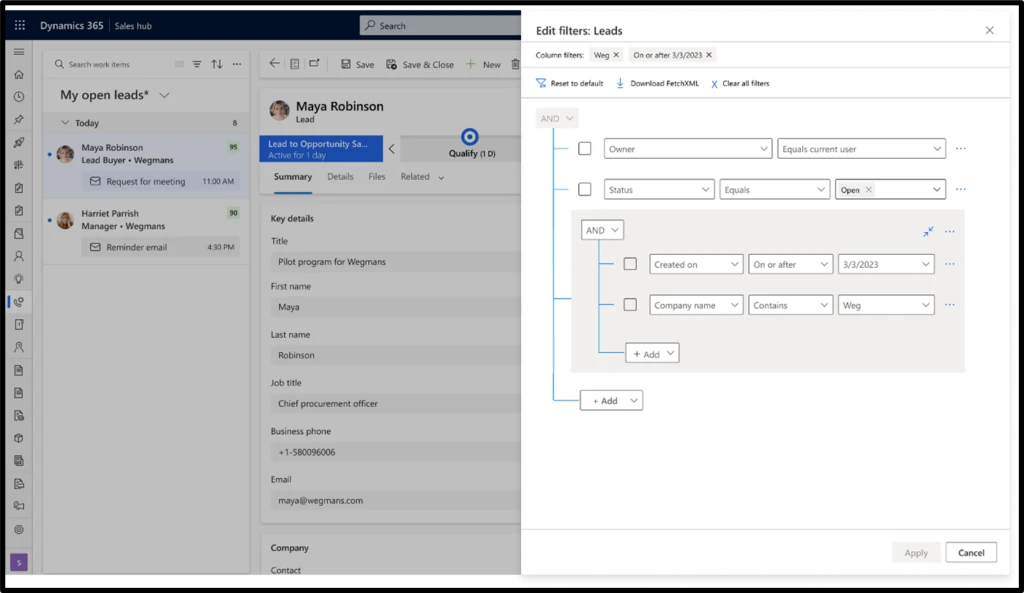
Advanced filtering capability: We have introduced the ability for users to create their own filter query. In addition, users can save it as a custom view from within focused view. This helps them view and work on records that matter.
Advanced filter query
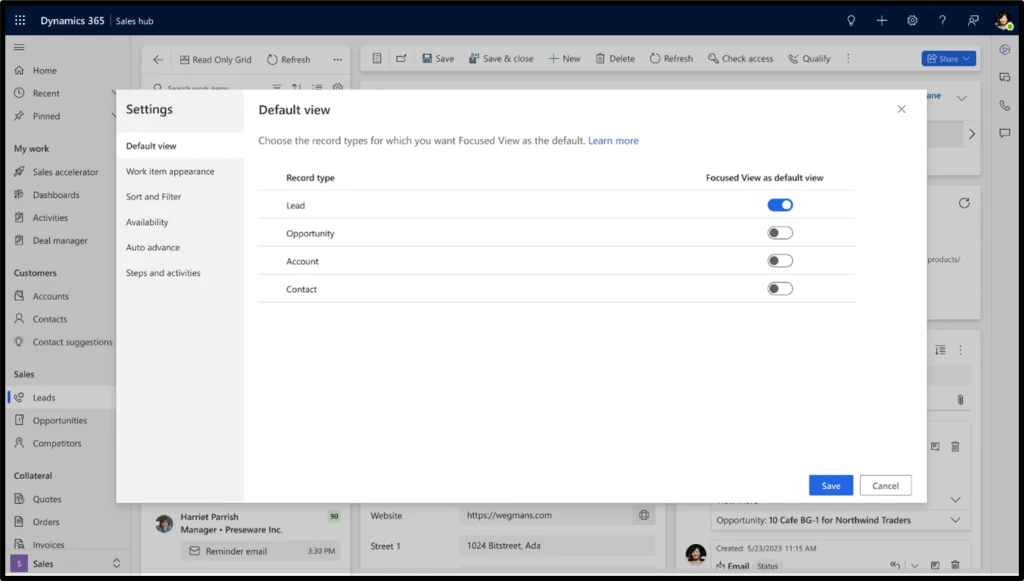
How can I make focused view the default landing page?
With all the new capabilities and ease of use, users will likely want to make focused view their default worksurface. To help achieve that, we are making it the default landing page for Lead entity as an out of the box option. For the other core entities, namely Account, Contact and Opportunity, we are providing an easy option for admins to make it the default option for their org from within the focused view specific settings. These can easily be adjusted for an organization’s specific needs.
Making focused view default for Lead, Opportunity, Account and Contact
For other entities, users can use the existing custom settings option within advanced settings. They simply need to choose the relevant entity and then select focused view from the list of available controls.
Conclusion
With these updates, focused view becomes the worksurface where users can view, plan and execute all their sales related tasks in a seamless and efficient manner. It helps them with greater task success rate and faster execution speed.
We are simplifying the ability for a users to get started. There’s now no setup required at either their or admin level. With these enhancements, users will find focused view readily available as the primary option on the ribbon command bar when navigating the entity grid. This streamlined accessibility ensures a hassle-free initiation, allowing users to effortlessly view and utilize focused view as their default choice.
So go ahead and start leveraging focused view as the go-to workspace for all sales related tasks and save time to concentrate building relations and closing deals!
This article is contributed. See the original author and article here.
We are thrilled to announce that this newsletter edition officially marks one full year of Logic Apps’ Ace Aviators! From our initial newsletter and livestream in February of last year, it’s been an incredible journey witnessing this community take flight. Of course, none of this smooth flying would have been possible without YOU! So, to all our aviators, thank you for reading, watching, and participating this past year. Make sure to keep sharing and posting to #LogicAppsAviators so we can continue to navigate the skies of innovation together.
What is your role and title? What are your responsibilities associated with your position?
Although my title is Solution Architect, my role is of Practice/Competency Lead, and I lead the Microsoft Integration practice (I’m responsible for leading and growing our expertise) within Birlasoft Limited. My role is multifaceted, encompassing strategic leadership, team development, client engagement, and operational excellence.
Below is a breakdown of my responsibilities:
Strategic Leadership:
Defining the vision and direction for the practice, aligning it with the overall organizational strategy.
Identifying and pursuing growth opportunities, including new markets, services, and partnerships.
Staying abreast of industry trends and innovations to ensure our practice remains competitive (I’m not at my best now, but I’m taking steps to improve).
Team Development:
Building and nurturing a high-performing team of experts in our practice area.
Providing mentorship and coaching to help team members develop their skills and expertise.
Fostering a collaborative and innovative work environment.
Client Engagement:
Building strong relationships with clients and understanding their needs and challenges.
Developing and delivering high-quality solutions that meet client requirements.
Managing client expectations and ensuring their satisfaction.
Operational Excellence:
Establishing and maintaining efficient processes and workflows within the practice.
Managing budgets and resources effectively.
Measuring and monitoring key performance indicators (KPIs) and driving continuous improvement.
Overall, my goal is to lead the Microsoft Integration Practice to success by delivering exceptional value to our clients, developing our team, and contributing to the growth of the organization.
Can you provide some insights into your day-to-day activities and what a typical day in your role looks like?
Typical days begin with a coffee-fueled review of emails, calendar, and upcoming meetings, deadlines, and calls. A substantial portion of the day is then dedicated to collaborative meetings with project teams and clients, focusing on progress updates, challenge resolution, and recommendation presentations. Drafting proposals for new RFPs/RFIs or executing ongoing project plans occupies another significant segment of the workday. As the practice lead, I am also prepared to address any ad-hoc requests or situations that may arise within the practice.
The positive response to our proposals, built on strong customer focus and industry best practices, has ignited growth in the Birlasoft Integration Practice. To capitalize on this momentum, I’m busy interviewing and assembling a team of exceptional individuals. It’s an honor to be part of this thriving practice (and I can’t wait to see what we achieve together)!
So, my day involves doing development work, working on POC/RFP/RFI, solution designing, Interviews, handling escalations, mentoring team, resources, and project planning etc.
What motivates and inspires you to be an active member of the Aviators/Microsoft community?
I am a very strong believer in The Value of Giving Back and by nature I like helping people (as much as I can).
What Inspired: When I had started learning BizTalk, I took lot of help from the community written articles and Microsoft documentation. I will be very honest, although Microsoft documentation is very apt but the articles written by community members were more easy to understand, had a different perspective, simple ways to explain etc.
And that’s how I started with an intention of helping people like me by sharing whatever limited knowledge I have in a simplified manner (at least I try to) by various means – answering on forums, writing articles etc. I maintain a blog Techfindings…by Maheshkumar Tiwari through which I share my findings/learnings and it’s been over a decade I am doing it, over LinkedIn/Facebook answering individuals to their questions, also sometimes on groups.
What Motivates: When you receive mail/message/thank you note from someone you don’t know, saying that the content really helped them – to solve the problem, to crack the interview, to clear the understanding etc. — It warms my heart more than any award. It’s the fuel that keeps me creating, knowing I’m truly touching lives.
Looking back, what advice do you wish you would have been told earlier on that you would give to individuals looking to become involved in STEM/technology?
While theoretical knowledge is important, prioritize developing practical skills like coding, data analysis, project management, and problem-solving. Don’t wait for the “perfect” moment or project to begin. Try mini-projects, tinker with code, participate in online challenges. While doing this embrace failures as learning opportunities and steppingstones to improvement.
No one knows everything, and reaching out for help is a sign of strength, not weakness. Seek guidance from seniors, peers, online communities, or any available resources.
Focus on the joy of learning, exploring, and problem-solving, not just achieving a specific degree or job title. Curiosity and a love for understanding how things work will fuel your passion and resilience through challenges.
What are some of the most important lessons you’ve learned throughout your career?
The only thing which is constant is Change – the sooner we accept it and develop/have a mindset to adapt, the better it is.
Survival of the fittest is applicable to every phase of personal/professional life. You really can’t blame others.
Maintaining a healthy balance between work and personal life (unfortunately I am failing in this), practicing self-care, and managing stress are crucial for long-term success.
Building a successful career takes time, dedication, and perseverance. Set realistic goals, celebrate milestones, and don’t get discouraged by setbacks.
Enjoy the process, keep learning, and adapt to the ever-changing field.
Imagine you had a magic wand that could create a feature in Logic Apps. What would this feature be and why?
Without a second thought, following is what I would have created – A wizard which asks me questions about my workflow requirement and once the questionnaire ends, complete workflow should be presented.
Well, that’s from magic wand perspective :smiling_face_with_smiling_eyes:, but above is very much doable.
But, as of now following are the things which we can do at present (few points are from my team – want to share maximum ideas to make Logic app more robust)
Logic Apps should have a feature of disabling the actions from designer. This will help developers in unit testing the code efficiently. We can achieve this by commenting out Json in code view or by creating a backup workflow but that’s a tedious task.
Versioning missing in Azure standard Logic Apps
Breakpoint option should be enabled, so that it will help in debugging.
Retry from the failed step should be extended to loops and parallel branches as well
Need out of box support for Liquid Map debugging, Intellisense support would be also good to have
For now only Json schema is supported in http trigger, if xml support can be added to it.
CRON expression support in Logic app recurrence trigger
Reference documentation as to which WS plan should one choose based on number of workflows, volume of messages processed etc.(will help to justify the cost to clients)
Exact error capture for actions within loop/action within a scope inside a scope etc.
Support for partial deployment of workflows in a single logic app (adding only the new workflows and not overwrite all)
Check out this customer success story about Datex leveraging Microsoft Azure Integration Services to transform its infrastructure for a more modern solution. Azure Integration Services played a crucial role in enabling flexible integrations, data visualization through Power BI, and efficient electronic data integration (EDI) processes using Azure Logic Apps. Read more in this article about how AIS helped provide Datex with a low-code environment, faster time-to-market, cost savings, and enhanced capabilities.
Take a deeper dive into the new target-based scaling for Azure Logic Apps Standard update and how it can help you manage your application’s performance with asynchronous burst loads.
Read more on how Azure Logic Apps can unlock scenarios where it’s required to integrate with IBM i applications in another Mission Critical Series episode.
Struggling to manage your application settings during development and testing, especially when switching between local and cloud environments? Watch Sri’s video to learn how to efficiently manage your app settings.










Recent Comments