This article is contributed. See the original author and article here.
Welcome to the first of the “Azure Data Factory and Azure Purview integration” blog series!
Many enterprise customers and ISVs are using Azure Data Factory for their data integration and transformation needs. We are excited to see how ADF is making modeling and operating ETL flows more efficient and scalable for organizations worldwide! To make that experience even better, we are integrating ADF with Azure Purview to bring more customer values around lineage, policy management, and data governance.
In this blog series we will share scenarios, use cases, and how-to instructions on integration between ADF and Azure Purview. Each post will take 5-10 minutes to read.
As enterprises bring into more siloed data into their data lake and enterprise data warehouse, the data integration processes become more complex. As a result, it gets increasingly harder for users to track the freshness of the produced data and to analyze and optimize the existing ETL process. For example, when user needs to modify some data sources, it is very difficult to know how much impact it has on the ETL and downstream analytical process.
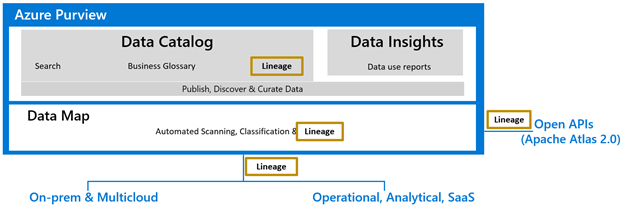
Azure Purview is a new cloud service for data users to centrally manage and govern data across their data estate spanning cloud and on-prem environments.
You can connect one or more data factories to an Azure Purview account, and the connection allows Data Factory to automatically publish lineage data for Copy, Data flow and SSIS package execution into Azure Purview. Data Factory Lineage in Azure Purview provides detailed information for root cause analysis and impact analysis.
Scenarios 1: Root cause analysis
Data Engineers own data sources within a data estate. In situations when a data source has incorrect data due to upstream issues, the data engineers have no centralized place to identify the issues.
Using catalog lineage, the data engineers can understand upstream process failures and be informed about the reasons for their data sources discrepancy.

Scenario 2: Impact analysis
If data Producers want to change and deprecate a column in a data source they own, and they want to know who are being impacted upon making such a change. There isn’t a centralized place a data producer can know all the downstream consumers of their data sources.
Using catalog lineage, a data producer can easily understand the impact of the downstream assets upon changing the attributes of the data source.

Next steps
- Create an Azure Purview account now and start by connecting a Data Factory
- Learn how to push and see lineage data in Azure Purview
- Learn more on lineage user guide.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments