This article is contributed. See the original author and article here.
We are excited to announce Azure Data Explore data connector for Azure Synapse Workspace. This is an extension of the Azure Data Explorer Spark connector that is now natively integrated into Azure Synapse Apache Spark pools.
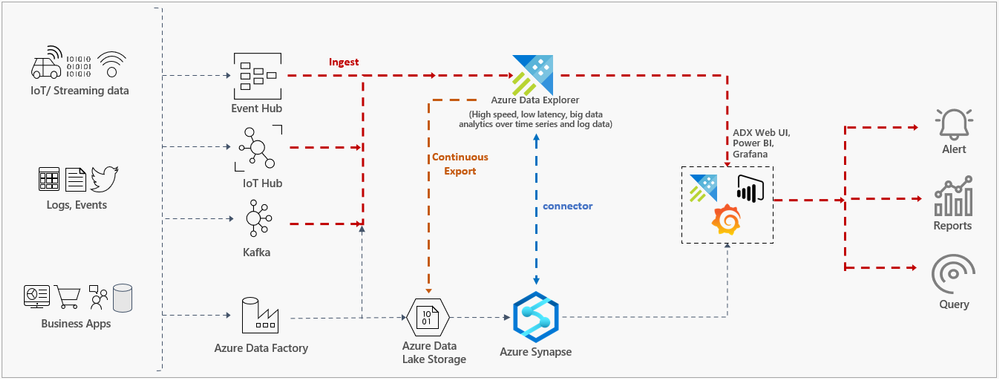
Azure Data Explorer is a fast, fully managed data analytics service for real-time analysis on large volumes of Telemetry, Logs, Time Series data streaming from applications, websites, IoT devices, and more. Azure Synapse Analytics brings together the worlds of enterprise data integration, data warehousing, and big data analytics into a single service both though on-demand and serverless and provisioned resources.
Microsoft customers are using Azure Data Explorer for near-real-time analytics and are looking at deeper integration with their Big Data solutions for the following scenarios:
- Archive data in Data Lake for long term retention.
- Run data processing jobs on large datasets and write the output to Azure Data Explorer.
- Train machine learning models and save the model to Azure Data Explorer for scoring on fresh data.
- Feed the data into their enterprise data warehouse.
- Correlate/process data across multiple data sources.
The above-mentioned scenarios are addressed by the combination of two capabilities: Continuous Export capability in Azure Data Explorer and Spark connector that is now natively integrated into Azure Synapse that enables smooth access to Azure Data Explore with AAD pass-through authentication, secure credentials management, and Synapse workspace experience to improve developer productivity and easy integration with the rest of your big data solution.

To power your near-real-time analytics, you can ingest your data into Azure Data Explorer, where the data is cached, indexed, and available for low latency ingestion and query. You can use the Azure Data Explorer connector in Azure Synapse to query the cached and indexed data using Synapse Apache Spark. The connector is optimized for moving large data sets and automatically optimizes for the right path to read the data via REST APIs or uses distributed export capability to export data from Azure Data Explorer and load the Spark DataFrame.
Optionally, for archiving data in the Data Lake store, use the continuous export to export data from Azure Data Explorer to your Data Lake Store linked to Azure Synapse Workspace. Once the data is available in Data Lake, you can run Synapse Apache Spark to process the data, train machine learning models, and send the output to Azure Data Explorer for further analysis or scoring the machine learning models on near-real-time data. You can also query, create tables and views over exported data with Synapse SQL serverless pool.
This connector simplifies the architecture for managing hot/warm/cold paths for your big data solutions. Please give it a try!
To get started:
- Follow the Synapse Quick Start to get started with using the Azure Data Explorer connector in Synapse.
- A sample code with advanced options is available here.
- Follow this documentation to setup up a continuous export job to export data to your Synapse linked Data Lake Storage account.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments