Automatic Scaling: Azure Web Apps Unleash Their Hidden Potential
This article is contributed. See the original author and article here.
Scale your Azure Web App automatically using Azure App Service Automatic Scaling
In this article we will focus on scaling azure web apps and how the new automatic scaling feature of azure app service, which allows it to scale out and in, in response to HTTP web traffic against your web app is a great feature which further enhances cost savings and improves the availability and resiliency of your web application under conditions of load.
We will also try to understand how automatic scaling is different (and at times based on scenarios better) than rule scaling, how to better understand and configure scaling limits and how it impacts scaling of different web applications sharing the same app service plan.
A look at existing options to scale an Azure Web App
- Manual scale: This is the simplest form of scaling where you decide on a fixed number of instances that you code needs to execute. This may seem similar to deploying an application to a virtual machine, but it has many advantages such as deploying code only once, no management of underlying hardware and as your needs change you can always change the number of instances running without having to deploy the code again.
- Rule based auto scale: This has been the most used scale option on azure web apps. This is further sub classified in two options.
- Scale based on a schedule: Let’s say your application is used by your users in a predictable manner, for instance an intranet application used by office employees will most likely see traffic consistently during the working days or a payroll application will see traffic once or twice a month (depending how you get your paycheck) for a period of 3-5 days, customers have traditionally been creating these schedules to scale an application out (and in: let’s forget to scale an application back in) using configurations as shown in example below, which allows the web application to run specific number of instances during the specific period of time during the specified days.
- Scale based on a metric: This has been the most advanced and a complex scaling condition to set. It allows you to configure the web application to scale in response to how a metric such as CPU Percentage or Memory Percentage of the underlying existing hosts changes during the load conditions. The way this is configured is how we configure an azure monitor metric alert and in response to it, in addition to firing an optional notification, the platform allows you to automatically scale out or in by adding or removing one or more instances of a fresh worker that can cater to your end user application traffic.
Although it works well but I have seen users having their fair share of challenges while setting this up with the common ones, I have faced, being
- Which metric should I use to scale? If your application has adopted message or event-based mechanisms, then it is an even more special case to consider the queue depth etc.
- Metrics are always aggregated over a period and if your application sees short bursts of load also referred to a transient spike, chances are high that by the time the scale out logic triggers your application may have already passed its peak demand and the scale out operation may not really help. You can try to keep evaluating your rule on a smaller duration and then match it with a smaller cool down period associated with aggressive scale out (meaning you add more instances quickly) and controlled scale in (meaning you scale back in smaller decrements over a longer duration) to cover for any next transient spike. You will see when you try it that it takes several attempts and good proactive monitoring before you get this balance working and the cost savings are less than optimal with a cohort of users complaining about slow response times often.
- You forget to create a scale in rule, and you only realize this at the end of the month when you get your invoice, and you are billed for a much higher number of web app instances than what you had planned for.
- Scale based on a schedule: Let’s say your application is used by your users in a predictable manner, for instance an intranet application used by office employees will most likely see traffic consistently during the working days or a payroll application will see traffic once or twice a month (depending how you get your paycheck) for a period of 3-5 days, customers have traditionally been creating these schedules to scale an application out (and in: let’s forget to scale an application back in) using configurations as shown in example below, which allows the web application to run specific number of instances during the specific period of time during the specified days.
Automatic Scaling
With Automatic Scaling, instead of us choosing a metric or configuring a schedule, the app service platform continues to monitor the HTTP traffic as soon as your application starts receiving it. Automatic Scaling periodically checks the /admin/host/ping endpoint along with other health check mechanisms inherent to the platform. These checks are specifically implemented features, with worker health assessments occurring at least once every few seconds. If the system detects increased load on the application, health checks become more frequent. In the event of deteriorating workers’ health and slowing requests, additional instances are requested. Once the load subsides, the platform initiates a review for potential scaling in. This process typically begins approximately 5-10 minutes after the load stops increasing. During scaling in, instances are removed at a maximum rate of one every few seconds to a minute.
As you dig in, you will realize that automatic scaling is very similar to the Elastic Premium plan that was introduced a while back for Azure Function Apps. If you are already familiar with Elastic Premium plans and are using them, then you will find the below section as a refresher to the concepts and you can choose to skip it.
Few terms to understand before we get into more details
- Pre-warmed instances: Consider this as an additional buffer worker that is ready to receive your applications traffic at moment’s notice. Using pre-warmed instances helps greatly reduce the time it takes to perform a scale-out operation. The default prewarmed instance count is 1 and, for most scenarios, this value should remain as 1. Currently, it is not possible to modify this setting to a higher number using the portal experience, but you can use the CLI, if you want to play around. Be mindful that you are charged for pre-warmed instances so unless you have tested that the default value of 1 does not work for you, do not change it.
- Maximum burst: Number of instances this plan can scale out under load. Value should be greater than or equal to current instances for this plan. This value is set at the level of the app service plan and in case you have multiple app services sharing the same plan and you want to see them scale independently then set the “Maximum scale limit” which is a setting that limits the number of instances a specific app under the app service plan can scale up to. All apps combined under the app service plan will be limited to this maximum burst value.
- Maximum scale limit: The maximum number of instances this web app can scale out to. As highlighted in the above point this is the setting which controls how much each individual app in the same app service plan can scale up to in terms of number of instances. If you have only one single web app in the same app service plan, then there is no point in configuring this value.
Load Testing the Metric based scaling vs Automatic Scaling
Web App Setup: The Azure web app is a Linux App Service set to Premium V3 P0V3 and 1 single instance set to the “Always Ready” instance.
The code deployed is the eShopOnWeb solution found on GitHub.
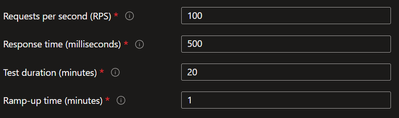
Load Test Setup
Note: Automatic Scaling takes precedence over custom auto scale settings. In case you have configured custom auto scale and want to switch to Automatic Scaling, I suggest you first switch to manual scale and disable the rule scale settings. Then enable and configure automatic scaling. As part of my tests, I observed some random behavior when switching between automatic scaling and rule-based scale with metrics back and forth without moving to manual scaling in between. This is also documented.
Rule based scaling:
As you can see, I configure the web app to scale based on the CpuPercentage metric by an instance count of 1.

As a result of the configuration, we observe a consistent scale out and in during the load testing and the graph is consistent in repeated runs.

Automatic Scaling:
For automatic scale setting shown below

under the same load the observed automatic scaling behavior is captured below along with the request rate and HttpResponseTime observed.



Key observations:
- What we are measuring is the maximum of a metric introduced as part of automatic scaling called automatic scaling instance count.
- We see the scaling out is very quick as the health checks being performed by the automatic scaling setup are being done continuously and if you read the documentation, it states that as the load increases the health checks become more frequent to keep up with the demand.
- Quick scale out ensures that the average response time does not stay at peak for a long time and is quickly brought down and remains consistent around a few ms.
- As the load varies the instances keep getting added and removed. The pace at which this happens is not always consistent. This is evident from a different set of graphs showing the automatic scale instance count metric for 2 runs of the same load test.
- The scaling in also happens quickly as the load decreases. As per documentation, the in starts to happen 5 minutes after the load reduced but I observed a more aggressive scale in which is much nicer as it helps me keep my costs down.
- It is safe to say that with automatic scaling the scale behavior is aggressive.
- My test load ran for 20 minutes. Comparing the total time, it takes for the scale operation to happen between the two scenarios, it is essentially 22 minutes approximately in case of automatic scale and 35 minutes in the custom scale with rules.
- Based on these observations, it is easy to see how automatic scaling brings function app kind of scaling capabilities to azure web app under the new premium plans. However, do note that both are inherently different implementations internally which is why you cannot share a plan with automatic scaling between a function app and an azure web app.
How to understand the billing with automatic scaling
Let’s use my setup as an example. I have only 1 always ready instance, so this is the instance that I am always being billed at. The platform will keep 1 pre-warmed instance handy.
When I am not running my load tests my web application is idle and the pre-warmed instance does not come in to play and hence there are no charges for the same. The moment my web application starts receiving traffic the pre-warmed instance is allocated and the billing for it starts. This is because I had only 1 always ready instance.
Assume, I had 2 or 3 always ready instances so unless all my existing instances had been activated and were receiving a steady stream of traffic the pre-warmed instance will not be activated and hence not billed.
The speed at which instances are added varies based on the individual application’s load pattern and startup time. The only way to keep track is to continue to monitor the automatic scaling instance count metric which is also used internally to come up with the billing which is done on a per second basis with automatic scaling configured. I found “Max” to be a better aggregation as compared to average for this metric so that you are safe with your cost projections.
Sample monthly cost projection, considering 1 single always ready instance at P0V3 and a maximum of 5 scaled instances running for 300 hours a month in east US = 73.73 + 300*0.101 = 104.03 USD. The actual cost will be less because my application is not peaking at 5 instances consistently (look at the graphs).
Automatic Scaling with multiple web apps in the same plan
To test how well different web applications will scale under the same app service plan, I deployed a simple Hello World template for an asp.net core web application you get in visual studio.
The first thing that you will notice is that the new web application also has the automatic scaling turned out as it is sharing the same app service plan.
To make sure that both apps make good use of the available resources and scale without impacting on the performance of the other app sharing the same plan we need to configure the scale out limit.
I kept that as 2 for the Hello World app and 3 for the eShopOnWeb app with the maximum burst set to 5.
There is nothing that prevents us from setting the maximum scale limit as 5 for both the applications and not even enforcing this limit in which case both the web applications will be competing for the 5 maximum burst instances.
My second sample application is just a simple web page with a 5 second delay so I will not be observing its response times for my analysis.
Running the same load test for both the applications
without limits set for each individual web application


With limits set


Observations
- When no limits are set both web applications try to scale to the maximum burst limit set at the level of the app service plan. This causes a bit of a race for the available resources initially but soon the web applications can scale to the number of required instances to meet the demand generated by the load.
- The average response time is much lower when no limits are set on individual web applications but when we ran the same load with limits of 2 and 3 instances set respectively the same eShopOnWeb application resulted in a much higher average response time.
- In this case the load test was run simultaneously but even when the same test was run with a delay of 5 minutes and no limits were set, the resources were distributed to both the web applications despite the first web application having a lead time to scale to more instances. Based on the one run, I executed in this manner having the first web application scaling out and the instances already in place allowed the second web application to scale even faster but my applications are simple so we should not generalize this.
Final Thoughts
Automatic scaling is a great addition to the azure web application service. Being able to scale a web application against web traffic and not just measured metrics has been an ask from customers for a long time and they can now do so by using this feature.
I have seen a lot of customers looking to containerize their web UI to achieve faster scalability against incoming traffic and with automatic scaling they can leverage the azure web application to host the web UI, while using AKS to host their backend API’s and scale the components independently.
It is quite adept in addressing the common challenges highlighted earlier with rule-based scaling by ensuring that setting up scaling is simple to just a couple of radio buttons and a slider, scale in happens as quickly as possible so that cost is optimized as much as possible.
I am sure this feature will see more improvements in the coming months. While the current concept adapts from how function app premium plans work, it will be great to see if the teams can adapt to scaling features akin to Kubernetes, without making it as complex as Kubernetes.
Ref:
https://learn.microsoft.com/en-us/azure/app-service/manage-automatic-scaling?tabs=azure-portal
https://learn.microsoft.com/en-us/azure/azure-functions/functions-premium-plan?tabs=portal
https://learn.microsoft.com/en-us/azure/azure-monitor/autoscale/autoscale-get-started





Recent Comments