by Contributed | Oct 15, 2024 | Technology
This article is contributed. See the original author and article here.
Introduction
In today’s data-driven world, the ability to act upon data as soon as its generated is crucial for businesses to make informed decisions quickly. Organizations seek to harness the power of up-to-the-minute data to drive their operations, marketing strategies, and customer interactions.
This becomes challenging in the world of real-time data where it is not always possible to do all the transformations while the data is being streamed. Therefore, you must come up with a flow that does not impact the data stream and is also quick.
This is where Microsoft Fabric comes into play. Fabric offers a comprehensive suite of services including Data Engineering, Data Factory, Data Science, Real-Time Intelligence, Data Warehouse, and Databases. But today, we are going to focus on Real-Time Intelligence.
Use-Cases
This set up can be used in scenarios where data transformation is needed to be used in downstream processing/analytical workload. As example of this would be to enable OneLake availability in KQL table and use that data to be accessed by other Fabric engines like Notebooks, Lakehouse etc. for training ML models/analytics.
Another example let’s say you have a timestamp column in your streaming data and you would like to change its format based on your standard. You can use the update policy to transform the timestamp data format and store it.
Overview
Fabric Real-Time Intelligence supports KQL database as its datastore which is designed to handle real-time data streams efficiently. After ingestion, you can use Kusto Query Language (KQL) to query the data in the database.
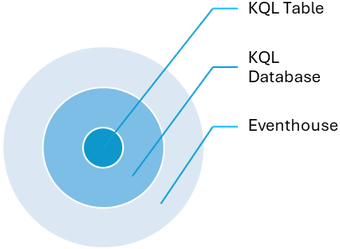
KQL Table is a Fabric item which is part of the KQL Database. Both these entities are housed within an Eventhouse. An Eventhouse is a workspace of databases, which might be shared across a certain project. It allows you to manage multiple databases at once, sharing capacity and resources to optimize performance and cost. Eventhouses provide unified monitoring and management across all databases and per database.
Figure 1: Hierarchy of Fabric items in an Eventhouse
Update policies are automated processes activated when new data is added to a table. They automatically transform the incoming data with a query and save the result in a destination table, removing the need for manual orchestration. A single table can have multiple update policies for various transformations, saving data to different tables simultaneously. These target tables can have distinct schemas, retention policies, and other configurations from the source table.
Scope
In this blog, we have a scenario where we will be doing data enrichment on the data that lands in the KQL table. In this case, we will be dropping the columns we don’t need but you can also do other transformations supported in KQL on the data.
Here we have a real-time stream pushing data to a KQL table. Once loaded into the source table, we will use an update policy which will drop columns not needed and push the data of interest to the destination table from the source table.

Prerequisites
Creating sample data stream
- In the Real-Time Intelligence experience, create a new event stream.
- Under source, add new source and select sample data.

- Continue configuring the stream. I am using the Bicycles sample data stream in this blog.
- Select Direct ingestion as the Data Ingestion Mode for destination.
- Select your workspace and KQL database you have created as a prerequisite to this exercise for the destination.
- You should be seeing a pop-up to configure the database details and continue to configure the table where you need to land the data from the stream.
Configuring KQL Table with Update Policy
- Open the Eventhouse page in Fabric. There you should now be able to preview the data that is being ingested from the sample data stream.
Create a new destination table. I used the following KQL to create the new table (destination):
.create table RTITableNew (
BikepointID: string,Street: string, Neighbourhood: string, No_Bikes: int, No_Empty_Docks: int )
- Under the Database tab, click on new and select Table Update Policy.

You can edit the existing policy format or paste the one below that I used:
NOTE: RTITable is source and RTITableNew is the destination table.
.alter table RTITable policy update ```[
{
"IsEnabled": true,
"Source": "RTITable",
"Query": "RTITable | project BikepointID=BikepointID, Street=Street, Neighbourhood=Neighbourhood, No_Bikes=No_Bikes, No_Empty_Docks=No_Empty_Docks ",
"IsTransactional": true,
"PropagateIngestionProperties": false,
"ManagedIdentity": null
}
]```
The above policy drops the Longitude and Latitude columns and stores the rest of the columns in the destination table. You can do more transformations as per your requirements, but the workflow remains the same.
- After running the above command, your destination table will start populating with the new data as soon as the source table gets data. To review the policy on the destination table, you can run the following command:
.show table policy update
Conclusion
To summarize, we took a real-time data stream, stored the data in a KQL database and then performed data enrichment on the data and stored in a destination table. This flow caters the scenarios where you want to perform processing on the data once its ingested from the stream.
Further Reading and Resources
Common scenarios for using table update policies – Kusto | Microsoft Learn
Create a table update policy in Real-Time Intelligence – Microsoft Fabric | Microsoft Learn

by Contributed | Oct 13, 2024 | Technology
This article is contributed. See the original author and article here.
Dr. Kai Neuffer – Principal Program Manager, Industry and Partner Sales – Energy Industry
Dr. Wolfgang De Salvador – Senior Product Manager – Azure Storage
Paul Edwards – Principal Technical Program Manager – Azure Core HPC & AI
Acknowledgments
We would like to express our gratitude to Cormac Garvey for his previous contributions to the NVIDIA network-operator and GPU-operator, which inspired this article.
Resources and references used in this article:
Introduction
As of today, more and more we see AKS gaining share as an orchestration solution for HPC/AI workloads. The drivers behind this trend are multiple: the progressive move toward containerization of the HPC/AI software stacks, the ease of management and the universal nature of Kubernetes APIs.
The focus of this blog post is to provide a guide for getting an AKS cluster InfiniBand enabled, with the possibility of having HCAs or IPoIB available inside Kubernetes Pods as cluster resources.
Several methodologies and articles have provided insights on the topic, as well as the official documentation of NVIDIA Network Operator.
The purpose of this article is organizing and harmonizing the different experiences while proposing a deployment model which is closer to the most maintained and standard way of enabling InfiniBand cluster: using NVIDIA Network Operator.
Of course, this is only the first step for having an AKS cluster HPC/AI ready. This article is meant to work in pair with the blog post for NVIDIA GPU operator.
In a similar way, a proper HPC/AI AKS cluster will require an adequate job scheduler like kqueue or Volcano to handle properly multi-node jobs and allowing a smooth interaction in parallel processing. This is out of the scope of the current Blog post, but references and examples can be found in the already mentioned in the repository related to HPC on AKS or running workloads on NDv4 GPUs on AKS.
Getting the basics up and running
In this section we will describe how to deploy a vanilla dev/testing cluster where the content of this article can be deployed for demonstration. In case you already have your AKS cluster with InfiniBand enabled nodes, you can skip this section.
Deploying a vanilla AKS cluster
The standard way of deploying a vanilla AKS cluster is following the standard procedure described in Azure documentation.
Please be aware that this command will create an AKS cluster with:
- Kubenet as Network CNI
- AKS cluster will have a public endpoint
- Local accounts with Kubernetes RBAC
In general, we strongly recommend for production workloads to look the main security concepts for AKS cluster.
- Use Azure CNI
- Evaluate using Private AKS Cluster to limit API exposure to the public internet
- Evaluate using Azure RBAC with Entra ID accounts or Kubernetes RBAC with Entra ID accounts
This will be out of scope for the present demo, but please be aware that this cluster is meant for NVIDIA Network Operator demo purposes only.
Using Azure CLI we can create an AKS cluster with this procedure (replace the values between arrows with your preferred values):
export RESOURCE_GROUP_NAME=
export AKS_CLUSTER_NAME=
export LOCATION=
## Following line to be used only if Resource Group is not available
az group create --resource-group $RESOURCE_GROUP_NAME --location $LOCATION
az aks create --resource-group $RESOURCE_GROUP_NAME --name $AKS_CLUSTER_NAME --node-count 2 --generate-ssh-keys
Connecting to the cluster
To connect to the AKS cluster, several ways are documented in Azure documentation. In this part of the article we will use Linux Ubuntu 22.04 on a VM with Azure CLI installed to deploy the cluster. We authenticate to Azure by using the az login command and install the Azure Client (be aware that in the login command you may be required to use –tenant in case you have access to multiple tenants). Moreover, be sure you are using the right subscription checking with az account show:
## Add --tenant in case of multiple tenants
## Add --identity in case of using a managed identity on the VM
az login
az aks install-cli
az aks get-credentials --resource-group $RESOURCE_GROUP_NAME --name $AKS_CLUSTER_NAME
After this is completed, you should be able to perform standard kubectl commands like:
kubectl get nodes
root@aks-gpu-playground-rg-jumpbox:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-11280554-vmss00001a Ready agent 9m40s v1.27.7
aks-agentpool-11280554-vmss00001b Ready agent 9m47s v1.27.7
Command line will be perfectly fine for all the operations in the blog post. However, if you would like to have a TUI experience, we suggest to use k9s, which can be easily installed on Linux following the installation instructions. For Ubuntu, you can install current version at the time of Blog post creation with:
wget "https://github.com/derailed/k9s/releases/download/v0.32.5/k9s_linux_amd64.deb"
dpkg -i k9s_linux_amd64.deb
k9s allows to easily interact with the different resources of AKS cluster directly from a terminal user interface. It can be launched with k9s command. Detailed documentation on how to navigate on the different resources (Pods, DaemonSets, Nodes) can be found on the official k9s documentation page.
Attaching an Azure Container registry to the Azure Kubernetes Cluster
To be able to create our own docker container to run them on the cluster it is convenient to create an Azure Container Registry (create a private Azure Container Registry) and to attach it to the AKS cluster. This can be done in the following way:
export ACR_NAME=
az acr create --resource-group $RESOURCE_GROUP_NAME
--name $ACR_NAME --sku Basic
az aks update --name $AKS_CLUSTER_NAME --resource-group $RESOURCE_GROUP_NAME --attach-acr $ACR_NAME
You will need to be able to perform pull and push operations from this Container Registry through Docker. To be able to push new containers into the registry you need to login first which you can do using the az acr login command:
az acr login --name $ACR_NAME
Connecting the AKS cluster to the container registry makes sure that the system managed identity for AKS nodes will have access to be allowed to pull containers.
About taints for AKS nodes
It is important to understand deeply the concept of taints and tolerations for Spot and GPU nodes in AKS. In case of spot instances, AKS applies the following taint:
kubernetes.azure.com/scalesetpriority=spot:NoSchedule
We will show later that we have to add some tolerations to be able to get the NVIDIA Network Operator running on Spot instances.
Creating the first IB pool
The currently created AKS cluster has as a default only a node pool with 2 nodes of Standard_D2s_v2 VMs. It is now time to add the first InfiniBand enabled node pool. This can be done using Azure Cloud Shell, for example using an Standard_HB120rs_v3 and setting the autoscaling enabled. We are setting the minimum number of nodes to 2 for the subsequent tests, so please remind to downscale the pool setting the minimum node number equal to 0 once completed to avoid not necessary costs:
az aks nodepool add
--resource-group $RESOURCE_GROUP_NAME
--cluster-name $AKS_CLUSTER_NAME
--name hb120v3
--node-vm-size Standard_HB120rs_v3
--enable-cluster-autoscaler
--min-count 2 --max-count 2 --node-count 2
In order to deploy in Spot mode, the following flags should be added to Azure CLI:
--priority Spot --eviction-policy Delete --spot-max-price -1
Once the deployment has finished, we can see the nodes with the kubectl get nodes command:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-hb120v3-16191816-vmss000000 Ready 51s v1.29.8
aks-hb120v3-16191816-vmss000001 Ready 51s v1.29.8
aks-nodepool1-28303986-vmss000000 Ready 101m v1.29.8
aks-nodepool1-28303986-vmss000001 Ready 101m v1.29.8
Installing the Network Operator
Installing Helm
On a machine with kubectl configured and with the context configured above for connection to the AKS cluster, we run the following to install helm if not installed already:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
&& chmod 700 get_helm.sh
&& ./get_helm.sh
Installing Node Feature Discovery
On Azure, since most of the nodes have a ConnectX-4 network card for accelerated networking, it is important to fine tune the node feature recognition. Moreover, AKS nodes may have special taints that needs to be tolerated by Node Feature Discovery daemons. Because of this we will install Node Feature Discovery separately from NVIDIA Network Operator.
NVIDIA Network Operator will act on the nodes with the label feature.node.kubernetes.io/pci-15b3.present. Moreover, it is important to tune the node discovery plugin so that it will be scheduled even on Spot instances of the Kubernetes cluster. Here we introduce also the MIG toleration and GPU toleration to grant compatibility with the NVIDIA GPU Operator article.
helm install --wait --create-namespace -n network-operator node-feature-discovery node-feature-discovery --create-namespace --repo https://kubernetes-sigs.github.io/node-feature-discovery/charts --set-json master.config.extraLabelNs='["nvidia.com"]' --set-json worker.tolerations='[{ "effect": "NoSchedule", "key": "sku", "operator": "Equal", "value": "gpu"},{"effect": "NoSchedule", "key": "kubernetes.azure.com/scalesetpriority", "value":"spot", "operator": "Equal"},{"effect": "NoSchedule", "key": "mig", "value":"notReady", "operator": "Equal"}]'
After enabling Node Feature Discovery, it is important to create a custom rule to precisely match ConnectX-6 and ConnectX-7 cards available on the most recent Azure nodes. This can be done creating a file called nfd-network-rule.yaml containing the following:
---
apiVersion: nfd.k8s-sigs.io/v1alpha1
kind: NodeFeatureRule
metadata:
name: nfd-network-rule
spec:
rules:
- name: "nfd-network-rule"
labels:
"feature.node.kubernetes.io/pci-15b3.present": "true"
matchFeatures:
- feature: pci.device
matchExpressions:
device: {op: In, value: ["101c", "101e"]}
After this file is created, we should apply this to the AKS cluster:
kubectl apply -n network-operator -f nfd-network-rule.yaml
After a few seconds the Node Feature Discovery will label ONLY the HBv3 nodes. This can be checked with:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-hb120v3-16191816-vmss000000 Ready 51s v1.29.8
aks-hb120v3-16191816-vmss000001 Ready 51s v1.29.8
aks-nodepool1-28303986-vmss000000 Ready 101m v1.29.8
aks-nodepool1-28303986-vmss000001 Ready 101m v1.29.8
kubectl describe nodes aks-hb120v3-16191816-vmss000001 | grep present
feature.node.kubernetes.io/pci-15b3.present=true
kubectl describe nodes aks-nodepool1-28303986-vmss000000 | grep present
The label should not be found on the agents node pool without InfiniBand (since they are of type Standard_D2s_v2)
Installing and configuring the NVIDIA Network Operator helm chart
We download the NVIDIA Network Operator helm chart and update our helm repository:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
Then we generate a configuration template file with the name values.yaml. For a quick view of all the available values we could type:
helm show values nvidia/network-operator --version v24.7.0
The values.yaml file is divide into several sections to configure the different components of the network operator. These can be summarized as:
The SR-IOV Network Operator is relevant for an OpenShift environments and requires access to the InfiniBand subnet manager which is not available on Azure. This is why we disabled it. For this article we modify the values.yaml file to enable the following components:
Our proposed values.yaml becomes:
nfd:
# -- Deploy Node Feature Discovery operator.
enabled: false
deployNodeFeatureRules: false
# -- Enable CRDs upgrade with helm pre-install and pre-upgrade hooks.
upgradeCRDs: true
operator:
tolerations: [{ "effect": "NoSchedule", "key": "sku", "operator": "Equal", "value": "gpu"},{"effect": "NoSchedule", "key": "kubernetes.azure.com/scalesetpriority", "value":"spot", "operator": "Equal"},{"effect": "NoSchedule", "key": "mig", "value":"notReady", "operator": "Equal"}]
sriovNetworkOperator:
# -- Deploy SR-IOV Network Operator.
enabled: false
deployCR: true
ofedDriver:
# -- Deploy the NVIDIA DOCA Driver driver container.
deploy: true
rdmaSharedDevicePlugin:
# -- Deploy RDMA shared device plugin.
deploy: true
useCdi: true
secondaryNetwork:
# -- Deploy Secondary Network.
deploy: true
cniPlugins:
# -- Deploy CNI Plugins Secondary Network.
deploy: true
multus:
# -- Deploy Multus Secondary Network.
deploy: true
ipoib:
# -- Deploy IPoIB CNI.
deploy: true
ipamPlugin:
# -- Deploy IPAM CNI Plugin Secondary Network.
deploy: true
nicFeatureDiscover:
deploy: false
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: kubernetes.azure.com/scalesetpriority
operator: Equal
value: spot
effect: NoSchedule
- key: mig
operator: Equal
value: notReady
effect: NoSchedule
Once we have done all modifications within the values.yaml file we can deploy the helm chart:
helm install network-operator nvidia/network-operator
-n nvidia-network-operator
--create-namespace
--version v24.7.0
-f ./values.yaml
--wait
After a few minutes we should see the following pods running on compute nodes:
kubectl get pods -n nvidia-network-operator --field-selector spec.nodeName=aks-hb120v3-16191816-vmss000001
NAME READY STATUS RESTARTS AGE
cni-plugins-ds-f4kcj 1/1 Running 0 2m50s
kube-ipoib-cni-ds-blfxf 1/1 Running 0 2m50s
kube-multus-ds-45hzt 1/1 Running 0 2m50s
mofed-ubuntu22.04-659dcf4b88-ds-7m462 0/1 Running 0 2m7s
nv-ipam-node-fpht4 1/1 Running 0 2m14s
whereabouts-78z5j 1/1 Running 0 2m50s
Further, we can check if the rdma-device plugin has published as a new resource:
kubectl describe node aks-hb120v3-16191816-vmss000001 | grep rdma/rdma_shared_device_a:
rdma/rdma_shared_device_a: 63
rdma/rdma_shared_device_a: 63
The first line shows the number of configured Host Channel Adaptors (HCAs) that can be used by pods running on the node. The second entry show how many of them are are available. As we have not started any pods that request this resource yet, both values are the same. This maximal number of HCAs can be set within values.yaml configuration file by modifying the rdmHcaMax setting within the rdmaSharedDevicePlugin section:
...
rdmaSharedDevicePlugin:
deploy: true
image: k8s-rdma-shared-dev-plugin
repository: ghcr.io/mellanox
version: sha-fe7f371c7e1b8315bf900f71cd25cfc1251dc775
useCdi: true
...
resources:
- name: rdma_shared_device_a
vendors: [15b3]
rdmaHcaMax: 63
...
We can also check if the IPoIB module has been loaded on the compute node and that the corresponding network interface exists. To do so, we use the kubectl debug command to start a busybox container on the node and connect to it:
kubectl debug node/aks-hb120v3-16191816-vmss000001 -it --image=mcr.microsoft.com/cbl-mariner/busybox:2.0
Once on the node, we can run the chroot command to get on the host and sudo to become root:
chroot /host
sudo su -
Then we can run the following commands to check if the IPoIB module is loaded and the network interface is configured:
lsmod | grep ipoib
ib_ipoib 135168 0
ib_cm 131072 2 rdma_cm,ib_ipoib
ib_core 409600 8 rdma_cm,ib_ipoib,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm
mlx_compat 69632 11 rdma_cm,ib_ipoib,mlxdevm,iw_cm,ib_umad,ib_core,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,mlx5_core
ip a
...
8: ibP257s79720: mtu 2044 qdisc mq state UP group default qlen 256
link/infiniband 00:00:01:48:fe:80:00:00:00:00:00:00:00:15:5d:ff:fd:33:ff:1a brd 00:ff:ff:ff:ff:12:40:1b:80:06:00:00:00:00:00:00:ff:ff:ff:ff
altname ibP257p0s0
inet6 fe80::215:5dff:fd33:ff1a/64 scope link
valid_lft forever preferred_lft forever
The name of the IPoIB interface ibP257s79720 is not consistant within the same VM SKU but the altname ibP257p0s0 is. This will be important when we configure the IPoIB CNI later.
About the OFED driver
The AKS Ubuntu 22.04 node image comes with the inbox Infiniband drivers which are usually relatively old and miss some features. Therefore, the NVIDIA Network Operator uses a driver container to load the most-recent DOCA-OFED modules into the the OS kernel of the hosts. To make sure that the modules match the kernel version of the host, the entripoint script of the container compiles the right DOCA-OFED version before loading the modules. This process takes a few minutes and slows down spinning-up of new nodes within the nodepool. This could be fixed by using a custom DOCA-OFED container that contains the modules for the version of the AKS node’s kernel.
Configuring the IBoIP CNI
The IPoIB CNI plugin allows us to create an IPoIB child link on each Pod that runs on the node. The number of these links is limited to the number of HCAs cofigured in the values.yaml configuration file as discussed previously.
To enable the IPoIB CNI we create the following ipoib_network.yaml file:
apiVersion: mellanox.com/v1alpha1
kind: IPoIBNetwork
metadata:
name: example-ipoibnetwork
spec:
networkNamespace: "default"
master: "ibP257p0s0"
ipam: |
{
"type": "whereabouts",
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"range": "192.168.5.225/28",
"exclude": [
"192.168.6.229/30",
"192.168.6.236/32"
],
"log_file" : "/var/log/whereabouts.log",
"log_level" : "info",
"gateway": "192.168.6.1"
}
The configration cotains the IPoIB interface name on the AKS host as value for the master key and the configuration for IP range for the IPoIB subnet. We apply the configuration by running:
kubectl create -f ipoib_network.yaml
Building a sample image for testing IPoIB and RDMA connectivity
In order to test with InfiniBand utilities the RDMA connectivity, it is critical to have a Docker image where DOCA OFED is installed with the userspace tools.
An example of such an image could have this Dockerfile:
FROM ubuntu:22.04
ENV DOCA_URL="https://www.mellanox.com/downloads/DOCA/DOCA_v2.8.0/host/doca-host_2.8.0-204000-24.07-ubuntu2204_amd64.deb"
ENV DOCA_SHA256="289a3e00f676032b52afb1aab5f19d2a672bcca782daf9d30ade0b59975af582"
RUN apt-get update
RUN apt-get install wget git -y
WORKDIR /root
RUN wget $DOCA_URL
RUN echo "$DOCA_SHA256 $(basename ${DOCA_URL})" | sha256sum --check --status
RUN dpkg -i $(basename ${DOCA_URL})
RUN apt-get update
RUN apt-get install doca-ofed-userspace -y
After creating this Dockerfile it is possible to build and push the image in the ACR created at the beginning of the blog post:
az acr login -n $ACR_NAME
docker build . -t $ACR_NAME.azurecr.io/ibtest
docker push $ACR_NAME.azurecr.io/ibtest
Testing IPoIB and RDMA connectivity
We will create three pods and spread them over two compute AKS nodes to demonstrate the IPoIB and RDMA connectivity. To so so we need to create the pods with the following resource request:
- Define the number of required CPU cores in a way that two pods can fit on a single host but the rhird one will be scheduled on a second one, e.g. cpu: 50.
- Request one HCA per pod: rdma/rdma_shared_device_a: 1.
- Run the pods in privileged: true mode to be able to access the RDMA InfiniBand interface.
The last point is only required if we want to use the InfinBand interface for RDMA workloads as MPI but not if we only want to use the IPoIB network communication.
To test the connectivity we create the following ibtestpod.yaml (the image name must be adjusted with your ACR_NAME):
apiVersion: v1
kind: Pod
metadata:
name: ipoib-test-pod-1
annotations:
k8s.v1.cni.cncf.io/networks: example-ipoibnetwork
spec:
restartPolicy: OnFailure
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: NoSchedule
containers:
- image: .azurecr.io/ibtest
name: rdma-test-ctr
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
privileged: true
resources:
requests:
cpu: 50
rdma/rdma_shared_device_a: 1
limits:
cpu: 50
rdma/rdma_shared_device_a: 1
command:
- sh
- -c
- |
sleep inf
---
apiVersion: v1
kind: Pod
metadata:
name: ipoib-test-pod-2
annotations:
k8s.v1.cni.cncf.io/networks: example-ipoibnetwork
spec:
restartPolicy: OnFailure
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: NoSchedule
containers:
- image: .azurecr.io/ibtest
name: rdma-test-ctr
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
privileged: true
resources:
requests:
cpu: 50
rdma/rdma_shared_device_a: 1
limits:
cpu: 50
rdma/rdma_shared_device_a: 1
command:
- sh
- -c
- |
sleep inf
---
apiVersion: v1
kind: Pod
metadata:
name: ipoib-test-pod-3
annotations:
k8s.v1.cni.cncf.io/networks: example-ipoibnetwork
spec:
restartPolicy: OnFailure
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: NoSchedule
containers:
- image: .azurecr.io/ibtest
name: rdma-test-ctr
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
privileged: true
resources:
requests:
cpu: 50
rdma/rdma_shared_device_a: 1
limits:
cpu: 50
rdma/rdma_shared_device_a: 1
command:
- sh
- -c
- |
sleep inf
We start the pods by executing:
kubectl apply -f ibtestpod.yaml
pod/ipoib-test-pod-1 created
pod/ipoib-test-pod-2 created
pod/ipoib-test-pod-3 created
We can check that all pods are distributed over the two nodes host even that might not be the same in your setup:
kubectl get pods --output 'jsonpath={range .items[*]}{.spec.nodeName}{" "}{.metadata.namespace}{" "}{.metadata.name}{"n"}{end}'
aks-hb120v3-16191816-vmss000000 default ipoib-test-pod-1
aks-hb120v3-16191816-vmss000001 default ipoib-test-pod-2
aks-hb120v3-16191816-vmss000001 default ipoib-test-pod-3
By executing the following commands we can get the IPoIB IP addresses of the pods:
kubectl describe pod ipoib-test-pod-1 | grep multus | grep ipoib
Normal AddedInterface 35s multus Add net1 [192.168.5.225/28] from default/example-ipoibnetwork
kubectl describe pod ipoib-test-pod-2 | grep multus | grep ipoib
Normal AddedInterface 38s multus Add net1 [192.168.5.226/28] from default/example-ipoibnetwork
kubectl describe pod ipoib-test-pod-3 | grep multus | grep ipoib
Normal AddedInterface 41s multus Add net1 [192.168.5.227/28] from default/example-ipoibnetwork
We see that pod ipoib-test-pod-1 that runs on the first AKS node has the IPoIB IP address 192.168.5.225, while pod ipoib-test-pod-2 has the IPoIB IP address 192.168.5.226 and pod ipoib-test-pod-3 192.168.5.227. Both run in the second AKS node.
To test the intra-node and inter-node IPoIB connectivity we connect to ipoib-test-pod-2 and ping the other two pods:
kubectl exec -it ipoib-test-pod-2 -- /bin/sh
/ # ping 192.168.5.225 -c 3
PING 192.168.5.225 (192.168.5.225): 56 data bytes
64 bytes from 192.168.5.225: seq=0 ttl=64 time=1.352 ms
64 bytes from 192.168.5.225: seq=1 ttl=64 time=0.221 ms
64 bytes from 192.168.5.225: seq=2 ttl=64 time=0.281 ms
--- 192.168.5.225 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.221/0.618/1.352 ms
/ # ping 192.168.5.227 -c 3
PING 192.168.5.227 (192.168.5.227): 56 data bytes
64 bytes from 192.168.5.227: seq=0 ttl=64 time=1.171 ms
64 bytes from 192.168.5.227: seq=1 ttl=64 time=0.255 ms
64 bytes from 192.168.5.227: seq=2 ttl=64 time=0.290 ms
--- 192.168.5.227 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.255/0.572/1.171 ms
We also confirm the IP address is 192.168.5.226 by running:
/ # ip a | grep net1
12: net1@if8: mtu 2044 qdisc noqueue state UP
inet 192.168.5.226/28 brd 192.168.5.239 scope global net1
Just notice that the name of the IBoIB link device on the node is net1@if8. To test the RDMA we just start the ib_read_lat on ipoib-test-pod-2:
# ib_read_lat
************************************
* Waiting for client to connect... *
************************************
Then we open another shell, connect to iboip-test-pod-1 and run ib_read_lat 192.168.5.226, which is the IP address of connect to iboip-test-pod-2:
kubectl exec -it ipoib-test-pod-1 -- /bin/sh
# ib_read_lat 192.168.5.226
---------------------------------------------------------------------------------------
RDMA_Read Latency Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 1
Mtu : 4096[B]
Link type : IB
Outstand reads : 16
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0x1b7 QPN 0x0126 PSN 0xc5305e OUT 0x10 RKey 0x04070c VAddr 0x0056453ff00000
remote address: LID 0x1c1 QPN 0x0126 PSN 0x18a616 OUT 0x10 RKey 0x04060a VAddr 0x005607b90aa000
---------------------------------------------------------------------------------------
#bytes #iterations t_min[usec] t_max[usec] t_typical[usec] t_avg[usec] t_stdev[usec] 99% percentile[usec] 99.9% percentile[usec]
Conflicting CPU frequency values detected: 1846.554000 != 3463.693000. CPU Frequency is not max.
Conflicting CPU frequency values detected: 1846.554000 != 3510.158000. CPU Frequency is not max.
2 1000 3.80 5.95 3.83 3.84 0.00 3.93 5.95
---------------------------------------------------------------------------------------
This shows that there is RDMA connectivity between iboip-test-pod-1 and iboip-test-pod-2 which run each on a different AKS nodes. Then we go back to pod iboip-test-pod-2 and start the ib_read_lat server again:
[root@ipoib-test-pod-2 /]# ib_read_lat
************************************
* Waiting for client to connect... *
************************************
Then we open another shell, connect to iboip-test-pod-3 and run ib_read_lat 192.168.5.226 again:
kubectl exec -it ipoib-test-pod-3 -- /bin/sh
# ib_read_lat 192.168.5.226
---------------------------------------------------------------------------------------
RDMA_Read Latency Test
Dual-port : OFF Device : mlx5_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : ON
TX depth : 1
Mtu : 4096[B]
Link type : IB
Outstand reads : 16
rdma_cm QPs : OFF
Data ex. method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0x1b7 QPN 0x0127 PSN 0x99bde7 OUT 0x10 RKey 0x040700 VAddr 0x005624407f9000
remote address: LID 0x1c1 QPN 0x0127 PSN 0x9539df OUT 0x10 RKey 0x040600 VAddr 0x00563b8d000000
---------------------------------------------------------------------------------------
#bytes #iterations t_min[usec] t_max[usec] t_typical[usec] t_avg[usec] t_stdev[usec] 99% percentile[usec] 99.9% percentile[usec]
Conflicting CPU frequency values detected: 1846.554000 != 3512.949000. CPU Frequency is not max.
Conflicting CPU frequency values detected: 1846.554000 != 2089.386000. CPU Frequency is not max.
2 1000 3.79 7.03 3.82 3.82 0.00 3.87 7.03
---------------------------------------------------------------------------------------
Now both of these pods run on teh same AKS nodes which is refleted in the lower latency. Let us clean-up by deleting the pods:
kubectl delete -f ibtestpod.yaml
pod "ipoib-test-pod-1" deleted
pod "ipoib-test-pod-2" deleted
pod "ipoib-test-pod-3" deleted
Uninstalling the NVIDIA Network Operator
To apply a different configuration we might want to uninstall the operator by uninstalling the helm template before we install a new version:
helm uninstall network-operator -n nvidia-network-operator
Downscaling the node pool
To allow the nodepool to autoscale down to zero, use the following Azure CLI command. This is important to avoid any unwanted cost:
az aks nodepool update
--resource-group $RESOURCE_GROUP_NAME
--cluster-name $AKS_CLUSTER_NAME
--name hb120v3
--update-cluster-autoscaler
--min-count 0
--max-count 2
Conclusions
This article is meant to provide a low-level insight on how to configure InfiniBand using NVIDIA Network operator on an AKS cluster.
Of course, this is only the first step for having an AKS cluster HPC/AI ready. This article is meant to work in pair with the blog post for NVIDIA GPU operator.
In a similar way, a proper HPC/AI AKS cluster will require an adequate job scheduler like kqueue or Volcano to handle properly multi-node jobs and allowing a smooth interaction in parallel processing. This is out of the scope of the current Blog post, but references and examples can be found in the already mentioned in the repository related to HPC on AKS or running workloads on NDv4 GPUs on AKS.

by Contributed | Oct 12, 2024 | Technology
This article is contributed. See the original author and article here.
Introduction
In the age of AI and machine learning, data is the key to training and fine-tuning models. However, gathering high-quality, diverse datasets can be challenging. Synthetic data generation offers a promising solution, but how do you ensure the data you’re creating is both valid and responsible?
This blog will explore the process of crafting responsible synthetic data, evaluating it, and using it for fine-tuning models. We’ll also dive into Azure AI’s RAFT distillation recipe, a novel approach to generating synthetic datasets using Meta’s Llama 3.1 model and UC Berkeley’s Gorilla project.
Understanding Synthetic Data for Fine-Tuning
What is synthetic data?
Synthetic data is artificially generated rather than collected from real-world events. It is used when gathering real data is expensive, time-consuming, or raises privacy concerns. For example, synthetic images, videos, or text can be generated to mimic real-world datasets.
Why synthetic data matters for fine-tuning:
Fine-tuning a machine learning model with real-world data is often limited by the availability of diverse, high-quality datasets. Synthetic data fills this gap by providing additional samples, augmenting the original dataset, or generating new, unseen scenarios. For instance, in AI models like GPT or image classification systems, fine-tuning with synthetic data helps models adapt to specialized tasks or environments.
Common use cases:
- Natural Language Processing (NLP): Generating new text to help models better understand uncommon language structures.
- Computer Vision: Creating synthetic images to train models for object detection, especially in rare or sensitive cases like medical imaging.
- Robotics: Simulating environments for AI models to interact with, reducing the need for real-world testing.
What makes data “responsible”?
Synthetic data can exacerbate existing biases or create new ethical concerns. Creating responsible data ensures that datasets are fair, and representative, and do not introduce harmful consequences when used for fine-tuning AI models.
Key principles of responsible synthetic data include:
- Fairness: Avoiding biases in race, gender, or other sensitive attributes.
- Privacy: Ensuring that synthetic data does not leak sensitive information from real-world datasets.
- Transparency: Ensuring that the origins and processing of the synthetic data are documented.
Quality aspects for validation:
- Diversity: Does the data capture the range of possible real-world cases?
- Relevance: Does the synthetic data match the domain and task for which it will be used?
- Performance Impact: Does the use of synthetic data improve model performance without degrading fairness or accuracy?
Validating Synthetic Data
Validation ensures that synthetic data meets the required quality and ethical standards before being used to fine-tune a model.
Techniques for validation:
- Ground-truth comparison: If there’s real data available, compare the synthetic data with real-world datasets to see how closely they match.
- Model-based validation: Fine-tune a model with both synthetic and real data, then test its performance on a validation dataset. If the synthetic data significantly improves the model’s accuracy or generalization capabilities, it’s considered valid.
- Bias and fairness evaluation: Use fairness metrics (such as demographic parity or disparate impact) to check if the synthetic data introduces unintended biases. Several tools, like Microsoft Fair Learn or IBM’s AI Fairness 360, can help identify such issues.
Tools and methods for validation:
- Azure Machine Learning offers built-in tools for data validation, including feature importance, explainability dashboards, and fairness assessments.
- Open-source tools such as Google’s What-If Tool or IBM AI Fairness 360, can provide detailed reports on fairness and bias in your synthetic data.
The RAFT Distillation Recipe
The RAFT distillation recipe, available on GitHub, provides a method to generate high-quality synthetic datasets using Meta Llama 3.1 and UC Berkeley’s Gorilla project.
Introduction to RAFT
RAFT (Reinforcement Active Fine-Tuning) is a technique where a pre-trained model generates synthetic data, which is then used to fine-tune the same or a similar model. The goal is to create data that is relevant, diverse, and aligned with the task for which the model is being fine-tuned.
Meta Llama 3.1:
A powerful language model deployed on Azure AI. Using RAFT, Meta Llama generates synthetic data that can be used for NLP tasks, such as question answering, summarization, or classification.
UC Berkeley’s Gorilla Project:
The Gorilla project focuses on fine-tuning models for specific tasks using minimal data. By integrating the Gorilla project’s methods into RAFT, users can create a tailored dataset quickly and efficiently.
Steps from the RAFT distillation recipe:
- Step 1: Deploy Meta Llama 3.1 on Azure AI using the provided instructions in the GitHub repo.
- Step 2: Use RAFT distillation to generate synthetic datasets. This involves having the model generate relevant text or data samples based on input prompts.
- Step 3: Evaluate the generated synthetic dataset using metrics such as relevance, diversity, and performance.
- Step 4: Fine-tune the model using the generated synthetic data to improve performance on specific tasks.
The blog can include code snippets from the repo to show users how to set up RAFT on Azure, generate synthetic datasets, and fine-tune models.
To create a JSONL (JSON Lines) file for training models in Azure Machine Learning, follow these step-by-step instructions:
What is a JSONL File?
A JSONL file is a format where each line is a valid JSON object. It’s commonly used for machine learning tasks like fine-tuning models because it allows you to store structured data in a readable format.
Step-by-Step Guide to Creating a JSONL File
Step 1: Prepare Your Data
- Identify the data you need for fine-tuning. For instance, if you’re fine-tuning a text model, your data may consist of input and output text pairs.
- Each line in the file should be a JSON object. A typical structure might look like this:
Step 2: Use a Text Editor or Python Script
You can create a JSONL file using a text editor like Notepad or VS Code, or generate it programmatically with a script (e.g., in Python).
- Method 1: Using a Text Editor
- Open a plain text editor (like Notepad++ or Visual Studio Code).
- Write each line as a valid JSON object, e.g.

- Save the file with a .jsonl extension (e.g., training_data.jsonl).
Method 2: Using Python Script You can also use Python to generate a JSONL file, especially if you have a large dataset.
Example Python code:

Step 3: Validate the JSON Format
Ensure that:
- Each line in your file is a valid JSON object.
- There are no commas between objects (unlike a JSON array).
- Make sure that every object is properly enclosed in {}.
Step 4: Upload to Azure ML
Once your JSON file is ready:
- Upload the file to your Azure Machine Learning workspace. You can do this from the Azure portal or via an SDK command.
- Use the file for training or evaluation in the Azure ML pipeline, depending on your task (e.g., fine-tuning).
Step 5: Test the File
To verify the file, you can use a simple Python script to load and print the contents:

Example: JSONL File for Fine-Tuning (with 3 lines)

Summary of Steps:
- Prepare your data in a structured JSON format.
- Write each line as a separate JSON object in a text editor or using a Python script.
- Save the file with a .jsonl extension.
- Validate the format to ensure each line is a valid JSON object.
- Upload to Azure Machine Learning for model training or fine-tuning.
By following these steps, you’ll have a valid JSONL file ready to be used in Azure Machine Learning for tasks such as model fine-tuning.
Resources
- Azure Machine Learning documentation: https://learn.microsoft.com/azure/machine-learning/?view=azureml-api-2&viewFallbackFrom=azureml-api-2%3Fstudentamb_263805
- Azure AI: https://azure.microsoft.com/solutions/ai/?studentamb_263805


Recent Comments