This article is contributed. See the original author and article here.
Written by Cosmos Darwin, Senior PM on the Azure Edge & Platform team at Microsoft. Follow him on Twitter @cosmosdarwin.
The biggest news for Azure Stack HCI at Microsoft Ignite 2020 is the surprise announcement of the Azure Kubernetes Service coming to Azure Stack HCI. You can download the Preview right now. This new service dramatically expands the possibilities for IT and Ops teams, empowering you to easily run modern container-based applications on-premises, including stateful containers that require fast, fault tolerant persistent storage.
In this blog post, I’m going to explain how it works. I’ll describe the experience of setting up a Kubernetes cluster on Azure Stack HCI, present the storage architecture, and then containerize and deploy a sample app to demonstrate basics like dynamic provisioning and scale-out. I’ll introduce some Kubernetes concepts along the way, but that’s not the focus. If you’re interested in how you can use Storage Spaces Direct in the exciting new world of containers, read on!
Background
Before we start, it helps to understand the backstory: Kubernetes is hard to set up.
In recent years, containers have become the normal way to package and distribute new applications. Many organizations want to use Kubernetes to orchestrate their containers. Unfortunately, the only straightforward way to get Kubernetes has historically been to use a managed service in the public cloud, like Azure Kubernetes Service. But what if you need to deploy the app on your own servers, that you manage, on your premises? At Microsoft, we’re committed to helping you innovate anywhere with Azure. That’s why we build common tools that work across the cloud and the edge, and it’s why the Azure Kubernetes Service is coming to Azure Stack HCI.
OK, let’s get into it.
My lab environment
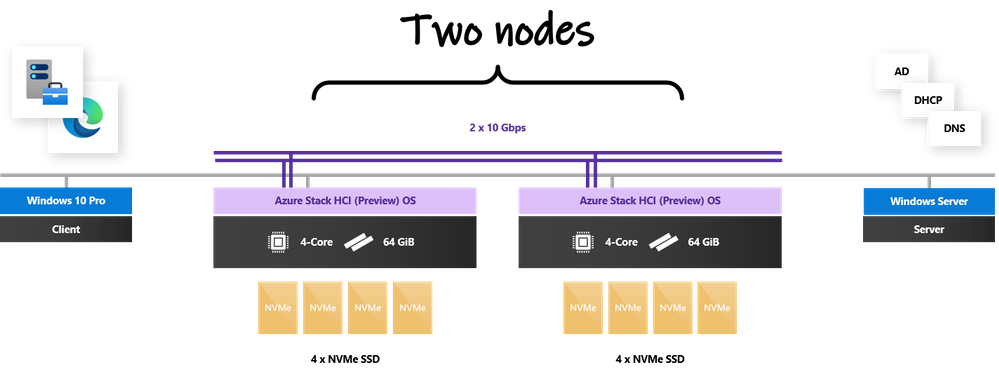
You don’t need a large hardware footprint to run the Azure Kubernetes Service. For this blog, I’m using an Azure Stack HCI cluster pretty close to the minimum spec: 2 nodes with 4 cores, 64 GiB of memory, and 4 x SSD drives each. If you watched my recent appearance on Azure Friday with Scott Hanselman, this configuration should sound familiar. Each node is running the latest Azure Stack HCI (Preview) operating system. (Missed that announcement? Watch my session from Microsoft Inspire in July.) There’s also a Windows 10 client machine with Windows Admin Center, and an Active Directory domain controller providing DNS and DHCP, on the same network.

Getting started: deploy the Azure Kubernetes Service
Before we can deploy a Kubernetes cluster, we first need to deploy the Azure Kubernetes Service itself. This step is only necessary on-premises: we are deploying our own instance of the control plane, running completely local to Azure Stack HCI. There’s no equivalent step in the public cloud because the control plane is already set up, years ago, by Microsoft.
Luckily, there’s a Windows Admin Center extension included with the Preview to make this easy. With the extension installed, navigate to your Azure Stack HCI cluster and select the “Azure Kubernetes Service” tool in the left menu. Provide the administrator credential, a cluster shared volume, and (implicitly) a range of IP addresses from your DHCP server, and it handles everything else. The installation takes about 30 minutes.

With the installation complete, we can poke around the cluster and observe what’s new:
- There’s an agent, visible in Get-Process, running on every host node
- There’s a clustered service, visible in Get-ClusterResource, running on the host cluster
- There are two virtual machines, visible in Get-VM or Windows Admin Center
- Many files have been dropped into our cluster shared volume


Ready-made Kubernetes infrastructure
With the infrastructure in place, we’re ready to deploy our first Kubernetes cluster.
In Kubernetes, a cluster comprises at least one controller node and additional worker nodes. When you deploy a Kubernetes cluster in Azure public cloud, these nodes are simply virtual machines deployed in Azure. The Azure Kubernetes Service handles provisioning them for you and setting them up with a container runtime (e.g. Docker) and the kubelet agentry. Inside, the worker nodes run either Linux or Windows, depending on the container images you want to run.
This all works the same way on Azure Stack HCI: when you deploy a Kubernetes cluster, the on-premises Azure Kubernetes Service provisions on-premises virtual machines with either Linux or Windows inside. Just like in Azure public cloud, these virtual “container host” nodes are completely managed for you, even though they’re on-premises. Let’s try it.
This PowerShell cmdlet creates a new Kubernetes cluster:
New-AksHciCluster -clusterName demo -linuxNodeCount 2
(Alternatively, you can use Windows Admin Center if you prefer.)
Our new Kubernetes cluster named “demo” will have 2 worker nodes running Linux. We can create Windows worker nodes (to run Windows containers) with the -windowsNodeCount parameter. Notice that we didn’t need to provide an ISO or VHD, nor credentials, nor… any inputs at all. After a few short minutes, our new Kubernetes nodes are created and visible in Windows Admin Center:

This push-button simplicity is the major benefit of Azure Kubernetes Service.
The first time you experience it on Azure Stack HCI, it’s honestly startling. Where did these virtual machines come from?! Closer inspection reveals that they’re running an operating system called “Common Base Linux – Mariner” that Microsoft quietly revealed last week on GitHub. Azure Kubernetes Service downloaded it for us. It’s an open-source Linux distribution that, like the rest of Azure Kubernetes Service on Azure Stack HCI, is supported and secured top-to-bottom by Microsoft. Very mysterious.

More important than the nodes themselves is what’s going on inside them. Azure Kubernetes Service has configured an impressive amount of infrastructure to assemble these nodes into a robust, managed Kubernetes cluster. And it helpfully installed kubectl.exe, the Kubernetes CLI, on every node in the Azure Stack HCI host cluster.
We can use kubectl to explore Kubernetes. In PowerShell, run:
PS C:> kubectl get pod -A
We see more than a dozen pods!
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-868d587f84-dws2x 1/1 Running 0 21m
kube-system coredns-868d587f84-kr8sw 1/1 Running 0 21m
kube-system csi-msk8scsi-controller-5bb99d6f5b-x9rxm 5/5 Running 0 21m
kube-system csi-msk8scsi-node-jfl9p 3/3 Running 0 20m
kube-system csi-msk8scsi-node-npqxm 3/3 Running 0 12m
kube-system etcd-demo-control-plane-v44qg 1/1 Running 0 22m
kube-system kube-apiserver-demo-control-plane-v44qg 1/1 Running 0 22m
kube-system kube-controller-manager-demo-control-plane-v44qg 1/1 Running 0 22m
kube-system kube-flannel-ds-amd64-9pxwn 1/1 Running 0 21m
kube-system kube-flannel-ds-amd64-brxz9 1/1 Running 0 12m
kube-system kube-flannel-ds-amd64-tjffx 1/1 Running 0 20m
kube-system kube-proxy-5s8kw 1/1 Running 0 12m
kube-system kube-proxy-p9nbd 1/1 Running 0 20m
kube-system kube-proxy-wfxfw 1/1 Running 0 21m
kube-system kube-scheduler-demo-control-plane-v44qg 1/1 Running 0 22m
kube-system moc-cloud-controller-manager-644b8d8688-4n84j 1/1 Running 0 21m
If you’ve used Kubernetes before, then you recognize many of these. Spot the four core components of the Kubernetes control plane: etcd, apiserver, controller, and scheduler; the Flannel plugin that fulfills the Container Network Interface (CNI); something with CSI in its name (hint: Container Storage Interface); and a few others.
On the other hand, if you’re new to Kubernetes, don’t feel overwhelmed. You don’t need to know any of this to succeed with Kubernetes on Azure Stack HCI. That’s the whole point: Azure Kubernetes Service handles it for you. I won’t get into Kubernetes infrastructure in this blog, but if you’re interested to learn more, consider reading one of the many excellent explainers out there, like this one.
Connecting the dots with Storage Spaces Direct
For our purposes, suffice to say that in Kubernetes, pods are the basic unit of compute and persistent volumes are the basic unit of storage. Pods comprise one or more containerized apps and consume resources like processor cycles and memory from worker nodes. They can also claim (request) access to one or more persistent volumes. Where do the persistent volumes come from?
Storage in Kubernetes depends on your environment. The Container Storage Interface (CSI) defines how storage providers can extend the core Kubernetes platform to offer convenient provisioning from an external storage system. For example, when you deploy Kubernetes in Azure public cloud, requests for storage are fulfilled by Azure Disks or Azure Files, depending on the specifics of your request. This works because Microsoft implemented two CSI drivers, azureDisk and azureFile, that Azure Kubernetes Service automatically installs for you.
To bring Kubernetes to Azure Stack HCI, our team implemented a new CSI driver.
The simplest way to try it out is what’s called static provisioning. In plain terms, this means to pre-create a Kubernetes persistent volume claim using administrator tools, even before deploying any pods. We can do this by authoring a short YAML file:
apiVersion: "v1"
kind: "PersistentVolumeClaim"
metadata:
name: "bigvolume"
spec:
resources:
requests:
storage: 100Gi
accessModes:
- "ReadWriteOnce
The primary way that administrators interact with Kubernetes is by applying YAML files to describe the desired state of the cluster. Kubernetes compares your YAML with the current reality, figures out what changes to make, and implements them. The YAML format is human-readable: ours defines an object of kind PersistentVolumeClaim named “bigvolume” with storage capacity up to 100 GiB and read/write access for one consumer at a time.
Save the YAML and use kubectl to apply it:
PS C:> kubectl apply -f pvc.yaml
To fulfill our claim, Kubernetes will provision a new persistent volume, or “pv” for short. We can see it with kubectl:
PS C:> kubectl get pv
Here’s the output:
NAME CAPACITY ACCESS MODES STATUS CLAIM STORAGECLASS AGE
pvc-e11dbfa2-3fc1... 100Gi RWO Bound default/bigvolume default 1s
Moreover, we see it in Windows Admin Center – look at the Azure Stack HCI volume where we deployed Azure Kubernetes Service, before and after:

Clearly, the provisioning worked: it’s consuming real capacity from our Azure Stack HCI storage pool.
But how! What sorcery made this happen?
Review: Azure Stack HCI storage architecture
As the baseline, let’s review the Azure Stack HCI storage architecture for traditional virtual machines:
(Tip: the numbers in this list correspond to the numbers in the diagram.)
1. An Azure Stack HCI cluster is comprised of physical OEM servers running our operating system
2. The servers are connected by high-speed Ethernet for the storage bus layer “back-end”
3. Every server contributes local SSD, HDD, and NVMe drives into a software-defined pool of storage
4. From the pool, virtualized data volumes are created with built-in resiliency (like RAID implemented in software)
5. Virtual machines running on the cluster store their virtual hard disk files in the data volumes
6. With like-local access to their files from any host, they can move around the cluster in response to failures or maintenance

There’s more to it – caching, striping, deduplication, etc. – but that’s the basic picture.
Azure Kubernetes Service on Azure Stack HCI builds on the same architecture, with just a few additions. That’s good news: if you understand Storage Spaces Direct, you’re already halfway to being an expert with Kubernetes on Azure Stack HCI, because steps 1-6 don’t change at all. Here’s the additional orchestration Azure Kubernetes Service provides:
7. Kubernetes, running inside the virtual nodes, receives a request for storage (e.g. from a newly scheduled pod)
8. It forwards the request to the new msvhd CSI driver, automatically installed by Azure Kubernetes Service
9. Our CSI driver makes the requests to the clustered Agent Service and the Node Agent on the volume owner node
10. The Node Agent creates a new VHDX file and attaches it to the worker node (virtual machine) that needs the storage
11. Inside the worker node, the new disk is discovered and formatted using EXT4 (Linux) or NTFS (Windows)
12. Kubernetes mounts the storage into the requesting pod’s container filesystem

Again, notice that this architecture is strictly additive: it builds on how Azure Stack HCI already works. This means that containerized apps benefit from all the beloved features of Storage Spaces Direct: RDMA-accelerated storage, server-side read/write caching, nested resiliency, mirror-accelerated parity, encryption at rest, deduplication and compression, self-balancing scale-out… it all just works.
To return to our example, using timestamps and file sizes, we can dig around and locate the VHD file that must correspond to “bigvolume” in Kubernetes. It’s tucked away here:
C:ClusterStorageVolume01imagesb79f1237ffe6c4b8ea899d6-fc71-11ea-91d4-02ec016a0003.vhdx
So, that’s the sorcery. :)
Dynamic storage provisioning
Our first example used static provisioning, one of two ways to get persistent storage in Kubernetes. The more common way is dynamic provisioning, where storage is created just-in-time as pods are scheduled. To facilitate dynamic provisioning, Kubernetes uses storage classes to represent and templatize different options (e.g. different media, or different resiliency, etc.) offered by the underlying storage.
For example, in Azure public cloud, Azure Kubernetes Service conveniently provides these out of the box:
PS C:> kubectl get sc
NAME PROVISIONER VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Immediate true 1h
azurefile-premium kubernetes.io/azure-file Immediate true 1h
default (default) kubernetes.io/azure-disk Immediate true 1h
managed-premium kubernetes.io/azure-disk Immediate true 1h
Notice the “default” storage class, which enables someone to request storage without specific knowledge of the local environment.
On Azure Stack HCI, there’s a convenient default storage class too:
PS C:> kubectl get sc
NAME PROVISIONER VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
default (default) msvhd Immediate true 1h
With dynamic provisioning and default storage classes, Kubernetes can ensure that containers get the storage they expect (as described in their YAML file) regardless how they get scheduled, re-scheduled, scaled out, or otherwise moved. It even provides portability to/from the public cloud: when I apply pvc.yaml from earlier on Azure public cloud, I get 100 GiB of Standard SSD Azure Managed Disk. When I run the exact same YAML on Azure Stack HCI, I get 100 GiB of VHDX on my host cluster’s capacity media.
I don’t need to change my code at all.
Sample application
To exercise the basics, I’ve written a sample app that we can containerize and deploy to Kubernetes on Azure Stack HCI. My app is an extravagant 17 lines of Python code (on GitHub here) meaning it’s simplistic, for illustrative purposes only. All it does is query the time, query its own container ID, and then append how long it’s been running to /storage/log.txt once per minute. That’s it.
To containerize this app, I’ve taken three steps:
- On my local dev box, I authored a Dockerfile to package this app into a container image
- I pushed the container image into an Azure Container Registry in my subscription
- Finally, I authored several YAML files to describe how Kubernetes should run my container

These files – demo.py, the Dockerfile, and the demo1/2/3.yaml Kubernetes manifests are literally all the code in this project.
The important point is that my app requires persistent storage.
Specifically, when my code starts, it expects writeable storage mounted at /storage.
Deploy the app
Let’s start with the simplest thing: demo1.yaml simply defines one PersistentVolumeClaim “myvolumeclaim” and one Pod “demo1” which mounts the volume.

Let’s apply the YAML:
PS C:> kubectl apply -f demo1.yaml
Moments later, just like that, Kubernetes has started running my app!
PS C:> kubectl get pod
NAME READY STATUS RESTARTS AGE
demo1 1/1 Running 0 27s
More to the point, its requested storage was dynamically provisioned:
PS C:> kubectl get pv
NAME CAPACITY ACCESS MODES STATUS CLAIM STORAGECLASS AGE
pvc-d8781916-8d5b-... 1Gi RWO Bound default/myvolumeclaim default 27s
After a few minutes, we can get a shell to the container and get the content of the file it’s writing:
PS C:> kubectl exec demo1 -- cat ../storage/log.txt
As expected, we see one lonely container, writing hello once per minute:
[09:51:00 AM] Hello from container e5809e63...ca54e26e! I've been running for 0 minutes.
[09:52:00 AM] Hello from container e5809e63...ca54e26e! I've been running for 1 minutes.
[09:53:00 AM] Hello from container e5809e63...ca54e26e! I've been running for 2 minutes.
[09:54:00 AM] Hello from container e5809e63...ca54e26e! I've been running for 3 minutes.
[09:55:00 AM] Hello from container e5809e63...ca54e26e! I've been running for 4 minutes.
The app works – cool.
Can we scale it?
Scale out (run multiple container instances)
Kubernetes has convenient and powerful built-in mechanisms to scale apps. By far the most common is an abstraction called Deployment. Instead of describing each pod directly, you templatizes one or multiple pods and then specify how many identical replicas of each pod should be running. (There’s more to it, but that’s the gist.) You provide the target number of replicas in your YAML specification, and Kubernetes handles spinning up additional instances to meet your target.
demo2.yaml defines a Deployment of our sample app. We can start with:
spec:
replicas: 1
With just 1 replica, this is equivalent to what we did before.
After verifying that it’s working, let’s make this edit to the YAML and re-apply:
spec:
replicas: 5
Kubernetes detects our change and immediately starts creating 4 more instances of our app!
PS C:> kubectl get pod
NAME READY STATUS RESTARTS AGE
demo2-bb9cb785b-4nrzt 1/1 Running 0 3m21s
demo2-bb9cb785b-8w76m 0/1 ContainerCreating 0 5s
demo2-bb9cb785b-f4mw5 0/1 ContainerCreating 0 5s
demo2-bb9cb785b-gsml2 0/1 ContainerCreating 0 5s
demo2-bb9cb785b-s8stg 0/1 ContainerCreating 0 5s
Notice that my YAML is structured such that all instances reference the same PersistentVolumeClaim – here’s the picture:

Because all 5 instances of our containerized app are accessing (and writing to) the same underlying storage, we expect to see their messages intermingled together. After a few minutes, we can get the contents of the /storage/log.txt file to confirm. And indeed, it works! For the first few minutes, from 10:00 AM until 10:03 AM, there is one single container (with ID ending in 8d3f6a82) writing once per minute. Then we scale out. From 10:04 onward, we see 5 containers with different IDs. One is from earlier, but 4 are new (running for 0 minutes). Thereafter, every minute on the minute, all 5 containers write in lockstep to the file:
[10:00:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 0 minutes.
[10:01:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 1 minutes.
[10:02:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 2 minutes.
[10:03:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 3 minutes.
[10:04:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 4 minutes.
[10:04:00 AM] Hello from container 03e68cc2...9369d18d! I've been running for 0 minutes.
[10:04:00 AM] Hello from container 1c93a862...f8e23339! I've been running for 0 minutes.
[10:04:00 AM] Hello from container 4f94949b...f8eb2df5! I've been running for 0 minutes.
[10:04:00 AM] Hello from container 08c7f504...e0345af8! I've been running for 0 minutes.
[10:05:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 5 minutes.
[10:05:00 AM] Hello from container 1c93a862...f8e23339! I've been running for 1 minutes.
[10:05:00 AM] Hello from container 03e68cc2...9369d18d! I've been running for 1 minutes.
[10:05:00 AM] Hello from container 4f94949b...f8eb2df5! I've been running for 1 minutes.
[10:05:00 AM] Hello from container 08c7f504...e0345af8! I've been running for 1 minutes.
[10:06:00 AM] Hello from container 735613d8...8d3f6a82! I've been running for 6 minutes.
[10:06:00 AM] Hello from container 08c7f504...e0345af8! I've been running for 2 minutes.
[10:06:00 AM] Hello from container 03e68cc2...9369d18d! I've been running for 2 minutes.
[10:06:00 AM] Hello from container 1c93a862...f8e23339! I've been running for 2 minutes.
[10:06:00 AM] Hello from container 4f94949b...f8eb2df5! I've been running for 2 minutes.
We’ve scaled our app, but what if we need to scale storage? Can we orchestrate that too?
Scale persistent storage with Stateful Sets
It’s reasonably common that when you containerize a stateful application, like a database, each instance may require its own persistent storage. One way to accomplish this is with the Kubernetes abstraction called StatefulSet. By templatizing both the pod and its storage claim, demo3.yaml showcases the value of dynamic provisioning. Now, each instance will get its own persistent volume, while still providing the same push-button scalability as before:

After we apply the YAML with Replicas: 5, we can see our statefulset. It’s diligently tracking 5/5 instances for us:
PS C:> kubectl get statefulset
NAME READY AGE
demo3 5/5 2m35s
Here are the 5 running pods, thoughtfully named and numbered by Kubernetes:
PS C:> kubectl get pod
NAME READY STATUS RESTARTS AGE
demo3-0 1/1 Running 0 3m
demo3-1 1/1 Running 0 3m
demo3-2 1/1 Running 0 2m
demo3-3 1/1 Running 0 2m
demo3-4 1/1 Running 0 1m
More to the point, each pod requested its own exclusive storage, so 5 persistent volume claims were provisioned:
PS C:> kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
myvolume-demo3-0 Bound pvc-09d32b8c-4373... 1Gi RWO default 3m
myvolume-demo3-1 Bound pvc-09d32b8c-4373... 1Gi RWO default 3m
myvolume-demo3-2 Bound pvc-09d32b8c-4373... 1Gi RWO default 2m
myvolume-demo3-3 Bound pvc-09d32b8c-4373... 1Gi RWO default 2m
myvolume-demo3-4 Bound pvc-09d32b8c-4373... 1Gi RWO default 1m
…and these claims were fulfilled concretely by creating 5 new VHDX files on Azure Stack HCI:

Takeaway
Whew, that was a lot to take in.
As you can see, Azure Kubernetes Service on Azure Stack HCI delivers the same push-button experience for deploying a robust, managed Kubernetes infrastructure as in Azure public cloud, but now running completely on your servers, on your premises. To empower you to innovate anywhere with Azure, this new service is supported and secured top-to-bottom by Microsoft, and includes everything you need to run modern container-based apps on Azure Stack HCI, like the new CSI storage driver that mounts capacity from Storage Spaces Direct into Kubernetes pods. With support for dynamic provisioning using storage classes, volume expansion, and more, containerized apps can get the storage they need on Azure Stack HCI with few or no code changes.
You can run containers and virtual machines side-by-side on the same Azure Stack HCI cluster, and if you have an existing deployment of Azure Stack HCI, you can add Azure Kubernetes Service without redeploying your environment or buying new hardware. It’s an exciting time for Azure edge infrastructure, and a great day to start learning Kubernetes.
Please try out the Preview and let us know what you think!
– Cosmos
Acknowledgements
Thanks to Dinesh Kumar Govindasamy, Benjamin Armstrong, and Nick Maliwacki for their support with this blog post. In the spirit of full transparency, let me acknowledge that this blog glosses over a few minor things: (1) For illustrative effect, we set the msvhd storage class to provision fixed VHDs although the default is dynamic; (2) For demo1, to pull our image from my private Azure Container Registry, we supplied imagePullSecrets in our YAML, not shown; (3) For demo2, we used a NodeSelector to keep all 5 replicas on the same node, because ReadWriteMany access isn’t in the current Preview.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments