
by Scott Muniz | Jul 29, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
In recent years, Azure Stack Hub has led the way for Microsoft’s Hybrid cloud offerings and partners have joined us to enhance the hybrid cloud journey of our customers. These partners and customers have built solutions that leverage Azure Stack Hub as part of their hybrid cloud strategy.
In some cases, these are actual products that work in hybrid environments and take advantage of the consistency offered by Azure Stack Hub, for the parts of the solution that “need to be on-premises”. In others, we’ve seen Service Providers that offer fully managed solutions to their customers – which essentially look just like a SaaS application they can consume directly, without worrying about all the parts of the solution that need to work together. Usually these range between:
- Service Providers
- They typically are Cloud Solution Providers (CSP), Managed Service Providers (MSP), or a System Integrator (SI) – some Service Providers are part of the Preferred and Advanced partners
- Either hosting an Azure Stack Hub, or a managing one on behalf of the end customer
- Partnering with ISVs, or building their own internal applications that are intended for their customers
- Enterprise customers
- Usually the larger companies that have certain requirements (regulatory, compliance, security, etc) for running Azure services on-premises
- Typically, they have an Azure presence and look to keep a consistent operational approach for their on-premises workloads
- Although they are internal to the company, they have their own internal-customers from other departments
- They need to provide value for their internal-customers and help them answer certain requirements
All of these partners create value for their customers, either internal or external to their company, by leveraging Azure Stack Hub as a platform and as part of the overall solution.
Today, we are starting a journey to explore the ways our customers and partners use, deploy, manage, and build solutions on the Azure Stack Hub platform.

Join Thomas Maurer (@ThomasMaurer) and myself (@rctibi) in this series, as we will meet customers that are deploying Azure Stack Hub for their own internal departments, partners that run managed services on behalf of their customers, and a wide range of in-between as we look at how our various partners are using Azure Stack Hub to bring the power of the cloud on-premises.
We are starting this journey with three videos:
Through the month of August, we have quite a few partner videos following and we will update this thread, as well as announce them on our Twitter feeds (#AzStackPartners) – follow us in this journey as we explore the partner solutions built on Azure Stack Hub!
by Scott Muniz | Jul 29, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
About the 20.07 feature release
The 20.07 feature release contains new features for application development and tenant certificate renewal, additional promotions of Beta features to long-term stable (LTS), and enhancement to improve stability and troubleshooting of device connections on Windows platforms.
New and changed features in the 20.07 release
The 20.07 feature release contains new features and improvements to networking, application development, analog-to-digital converter (ADC) and pulse-width modification (PWM) support, management of tenant certificate authority (CA) certificates, and client-side TLS in wolfSSL.
Networking features
This release adds new and enhanced foundational networking features:
Containers
You can now build Azure Sphere apps in containers, thus providing a reproducible build environment. A preconfigured container image for Azure Sphere is available from the Microsoft Container Registry (MCR).
Templates in Visual Studio and Visual Studio Code
Both Visual Studio and Visual Studio Code now support updated templates:
- The Blink template, intended for validating that the local development environment is set up correctly, supports additional Azure Sphere development boards.
- New blank templates for both high-level and real-time capable applications, which enable you to create an application with minimal removal of unneeded code.
Tenant certificate renewal
The Azure Sphere CLI and public API now support features for (viewing and renewing tenant CA certificates)[../deployment/tenant-cert.md].
In the azsphere CLI, the new azsphere ca-certificate command supports management and renewal of tenant CA certificates. This command replaces azsphere tenant download-ca-certificate, azsphere tenant download-ca-certificate-chain, and azsphere tenant download-validation-certificate.
wolfSSL
Azure Sphere applications can now use the wolfSSL client-side TLS API. Starting with the 20.07 release, Azure Sphere supports wolfSSL version 4.4 . This version includes numerous important changes, including some security features that resolve CVEs.
PC-to-device communication stability
The 20.07 feature release contains bug fixes and enhancements to ensure greater PC-to-device communication stability issues that are related to the FTDI driver on Windows. See Windows-specific problems for details. The new azsphere device rescan-attached command helps in troubleshooting device connection problems on Windows.
Public API
The Azure Sphere public API (PAPI) supports several new operations:
- Delete a device group
- Delete a product
- Get tenant certificates
- Get tenant certificate chain
- Get proof of possession certificate
- List tenant certificates
The following Azure Sphere Public APIs are being deprecated and will be retired on January 1, 2021:
- Tenants – List Certificates
- Tenants – List Certificate Chains
ADC and PWM
The analog-to-digital converter (ADC) and pulse-width modification (PWM) APIs have been promoted to long-term stable (LTS) from Beta.
In addition, Azure Sphere now includes limited ioctl support for both ADC and PWM.
Real-time application development
Real-time application support has been promoted to LTS. It is no longer considered Beta. Along with this change, the application.h API has also been promoted to LTS.
In addition, this release fixes a bug with the value of the reset vector of the M4 to enable the use of the M4 watchdog timer.
Hardware definitions
The Azure Sphere SDK now contains default hardware definitions for common Azure Sphere boards and dev kits, in both header file (.h) and JSON format. The GitHub sample apps also use hardware definitions to create a “sample appliance” abstraction that enables them to run unchanged across many boards, and to illustrate how you can create a similar abstraction for your own usage scenarios.
Sample applications
The Azure IoT sample applications for Azure Sphere have been updated to accommodate changes in Azure IoT Hub and Azure IoT Central. The samples also now support Linux as a development platform.
Boot timing
Boot performance in the 20.07 release has improved by approximately 750ms overall.
GNU Arm path discovery
The Azure Sphere extensions for both Visual Studio and Visual Studio Code now use the same internal mechanism to discover the location of the GNU Arm path. Previously, Visual Studio looked only within the Visual Studio installation directory. Now it looks first in the ARM_GNU_PATH environment variable, then in the registry (on Windows), and then in the Visual Studio installation directory.
Manufacturing samples
The iPerf3 network performance testing tool, which is part of the manufacturing samples, has been updated to LTS status. Support for a subset of fcntl() operations has been added to the base APIs to support the improvements in iPerf3.
Azure IoT C SDK support
Azure Sphere now supports the lts_02_2020 branch of the Azure IoT C SDK.
Linux kernel
The Linux kernel underlying the Azure Sphere OS has been updated to version 5.4.
Known issues in the 20.07 release
If you try to use an unknown client identity to authenticate to an EAP-TLS network, the WifiConfig_GetNetworkDiagnostics function does not return AuthenticationFailed (5) in the current release. Instead, it returns only the ConnectionFailed (1) error, which is a regression from the previous release. We expect to correct this in an upcoming release.
For more information
For more information on Azure Sphere OS feeds and setting up an evaluation device group, see Azure Sphere OS feeds.
If you encounter problems
For self-help technical inquiries, please visit Microsoft Q&A or Stack Overflow. If you require technical support and have a support plan, please submit a support ticket in Microsoft Azure Support or work with your Microsoft Technical Account Manager. If you do not have a support plan and require technical support, please explore the Azure support plans.
by Scott Muniz | Jul 29, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Those responsible for data will tell you that no matter what they do, at the end of the day, they’re value is only seen when the customer can get to the data they want. As much as we want to say this has to do with the data architecture, the design, the platforming and the code, it also has to incorporate the backup, retention and recovery of said data, too.
Oracle on Azure is a less known option for our beloved cloud and for our customers, we spend considerable time on this topic. Again, the data professional is often judged on how good they are by the ability to get the data back in times of crisis. With this in mind, we’re going to talk about backup and recovery for Oracle on Azure, along with key concepts and what to keep in mind when designing and implementing a solution.
Backups Pressure Points
A customer’s RPO and RTO can really impact when going to the cloud. They assume that everything will work the same way as it did on-prem and for most, it really does, but for backups, this is one of the big leaps that have to be made. It’s essential to embrace newer snapshot technologies over older, more archaic utilities for backups and Oracle is no different. We’re already more pressured by IO demands and to add RMAN backups and datapump exports on top of nightly statistics gathering jobs is asking for a perfect storm of IO demands the likes of which no one has ever seen, so this all has to be taken into consideration when architecting the solution.
As we size out the database using extended window AWR reports, we expect backups and any exports to be part of the workload, but if they aren’t, either due to differences in design or products used, this needs to be discussed from the very beginning of the project.

Using all of this information, we are going to identify the VM series not just by the DTU, (combination calculation for CPU and memory) but the VM throughput allowed and then the disk configuration to handle the workload. There are considerable disk options available towards backups, not just blob storage for inexpensive backup dump location, but locally managed disks that can be allocated for faster and more immediate access.
The Discussion
One of the first discussions that should be had when anyone is moving to the cloud around backup and recovery is clearly identifying Recovery Point Objective, (RPO) and Recovery Time Objective, (RTO), which for Oracle, centers around RMAN, Datapump, (imports/exports) and third-party tools.
Recovery Point Objective, (RPO) is the interval of time acceptable before a disruption in the quantity of data lost exceeds the business’ maximum ability to tolerate. Having a clear understanding of what this allowable threshold is essential to determining RPO. Recovery Time Objective (RTO) has to do with how much time it took to recover and return to business. This allowable time duration and any SLA includes when a database must be restored by after an outage or disaster and the time in order to avoid unacceptable consequences associated with a break in business continuity.
Specific questions around expectations for RPO and RTO revolve around:
- What is the time a database will complete a full or incremental backup and how often?
- What time is required to restore to be completed to meet SLAs?
- Are there any dependencies on archive log backups that will impact the first two scenarios?
- Is there the option to restore the entire VM vs. the database level recovery?
- Is it a multi-tier system that more than the database or VM must be considered in the recovery?
When customers use less-modern practices for development and refreshes, it’s important to help them evolve:
- Are there requirements for table level refreshes?
- Is there a subset of table data that can satisfy the request?
- Can objects be exported as needed during the workday?
- Consider snapshot restores
- Once a snapshot is restored to a secondary VM, the datapump copy would be used to retrieve the table to the destination.
- Consider flashback database from a secondary working database that could be used for a remote table copy to the primary database.
- Size considerations for the Flashback Recovery Area, (FRA) must be considered when implementing this solution and archiving must be enabled.
- The idea is flashback copy could be used to take a copy of the table and even use this table to copy over to a secondary database.
- Are database refreshes for secondary environments used for developers and testing?
- Consider using snapshots vs. RMAN clones or full recoveries.
- The latter are both time and resource intensive.
- Snapshots restores to secondary servers can be created in very short turn-around saving considerable time.
These types of changes can make a world of difference for the customers future, allowing them to not just migrate to the cloud, but completely evolve the way they work today.
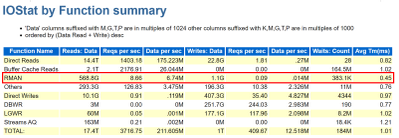
RMAN on Azure
RMAN, i.e. Recovery Manager, is still our go-to tool for Oracle backups on Azure, but it can add undo pressure on a cloud environment and this has to be recognized as so. Following best practices can help eliminate some of these challenges.
- Ensure that Redo is separated from Data
- Stripe disks and use the correct storage for the IO performance
- Size the VM appropriately, taking VM IO throughput limits into sizing considerations.
- Incorporate optimization features in RMAN, such as parallel matched to number of channels, RATE for throttling backups,
- Compress backup set AFTER and outside of RMAN if time is a consideration
- Turn on optimization:
RMAN> CONFIGURE BACKUP OPTIMIZATION ON;
By default this parameter is set to OFF, which results in Oracle not skipping unchanged data blocks in datafiles or backup of files that haven’t changed. Why backup something that’s already backed up and retained?
If you want to write backups to blob storage, blob fuse will still make a back up to locally managed disk and then move it to the less expensive blob storage. The time taken to perform this copy is what most are concerned about and if the time consideration isn’t a large concern for the customer, we choose to do this, but for those with stricter RPO/RTO, we’re less likely to go this route, choosing locally managed, striped disk instead.
As we’re still dependent on limits per VM on IO throughput, it’s important to take this all into consideration when sizing out the VM series and storage choices. We may size up from an E-series to an M-series that offers higher thresholds and write acceleration, along with ultra disk for our redo logs to assist with archiving. Identifying not only the IO but latency at the Oracle database level is important as these decisions are made. Don’t assume, but gather the information provided in an AWR for when a backup is taken, (datapump or other scenario being researched) to identify the focal point.
For many customers, ensuring that storage best practices around disk striping and mirroring are essential to improve performance of RMAN on Azure IaaS.
Using Azure Site Recovery Snapshots with Oracle
Azure Site Recovery isn’t “Oracle aware” like it is for Azure SQL, SQL Server or other managed database platforms, but that doesn’t mean that you can use it with Oracle. I just assumed that it was evident how to use it with Oracle but discovered that I shouldn’t assume. The key is putting the database in hot backup mode before the snapshot is taken and then taking it back out of backup mode once finished. The snapshot takes a matter of seconds, so it’s a very short amount of time to perform the task and then release the database to proceed forward.
This relies on the following to be performed in a script from a jump box, (not on the database server)
- Main script executes an “az vm run-command invoke” to the Oracle database server and run a script
- Script on the database server receives two arguments: Oracle SID, begin. This places the database into hot backup mode –
alter database begin backup;
- Main script the executes an “az vm snapshot” against each of the drives it captures for the Resource Group and VM Name. Each snapshot only takes a matter of seconds to complete.
- Main script executes an “az vm run-command invoke” to the Oracle database server and run a script
- Script on database server receives two arguments: Oracle SID, end. This takes the database out of hot backup mode
alter database end backup;
- Main script checks log for any errors and if any our found, notifies, if none, exits.
This script would run once per day to take a snapshot that could then be used to recover the VM and the database from.
Third Party Backup Utilities
As much as backup with RMAN is part of the following backup utilities, I’d like to push again for snapshots at the VM level that are also database enforced, allowing for less footprint on the system and quicker recovery times. Note that we again are moving away from full backups in RMAN and moving towards RMAN aware snapshots that can provide us with a database consistent snapshot that can be used to recover from and eliminate extra IO workload on the virtual machine.
Some popular services in the Azure Marketplace that are commonly used by customers for backups and snapshots are:
- Commvault
- Veeam
- Pure Storage Backup
- Rubrik
I’m starting to see a larger variety of tools available that once were only available on-prem. If the customer is comfortable with a specific third-party tool, I’d highly recommend researching and discovering if it’s feasible to also use it in Azure to ease the transition. One of the biggest complaints by customers going to the cloud is the learning curve, so why not make it simpler by keeping those tools that can remain the same, do just that?
by Scott Muniz | Jul 29, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
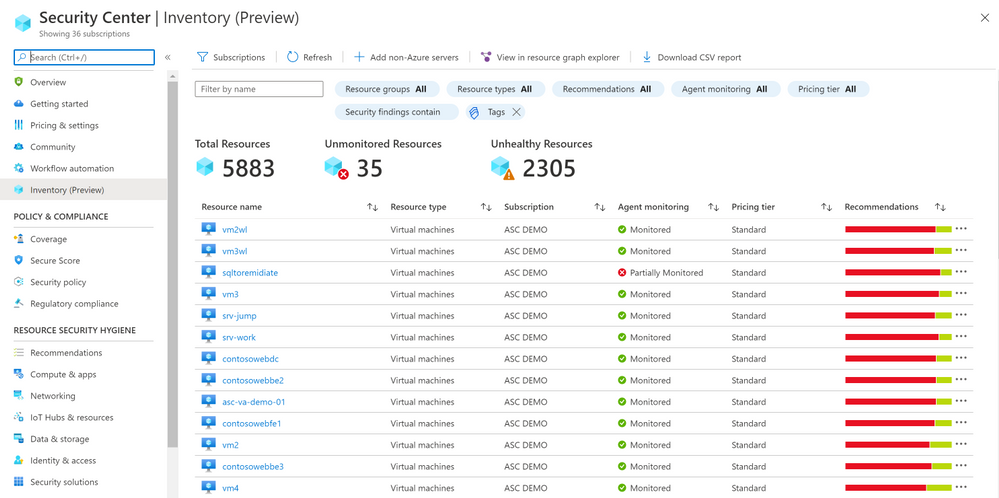
We are delighted to announce that Azure Security Center new Asset Inventory experience is now available in public preview!
What is the Asset Inventory experience?
A novel asset management experience providing you with full visibility over all your Security Center monitored resources.
This enables you to explore your security posture data in a much deeper and meaningful way with enhanced capabilities to filter, export, cross reference with different resource properties in addition to ASC generated insights.
This new experience is fully built on top of Azure Resource Graph (ARG) which now stores all of ASC security posture data, and leveraging its powerful KQL engine enables customers to quickly and easily reach deep insights on top of ASC data and cross reference with any other resource properties.
What can be achieved with this experience?
It is designed to help customers answer questions such as:
What are all my resources that are covered by Azure Security Center and which of these resources have outstanding security recommendations that should get my attention?

Find all resources that are vulnerable by a specific vulnerability and has a specific Azure resource tag?

To view more information about a resource, you can select it. The resource health pane opens.

These are just few examples of what can be discovered in the new experience, both in the UI and programmatically by calling the queries directly from Azure Resource Graph.
To save the query for later use, export it.


You can export the retrieved resources to CSV file for further use.

You can also onboard new Non-Azure servers to Azure Security Center.

As mentioned above, the Asset Inventory experience is now in public preview and will be improved constantly, stay tuned.
by Scott Muniz | Jul 29, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Introduction
Machine Learning is widely used these days for various data driven tasks including detection of security threats, monitoring IoT devices for predictive maintenance, recommendation systems, financial analysis and many other domains. Most ML models are built and deployed in two steps:
- Offline training
- Real time scoring
ML Training is done by researchers/data scientists. They fetch the training data, clean it, engineer features, try different models and tune parameters, repeating this cycle to improve the model’s quality and accuracy. This process is usually done using data science tools such as Jupyter, PyCharm, VS Code, Matlab etc. Once the model meets the required quality it is serialized and saved for scoring.
ML Scoring is the process of applying the model on new data to get insights and predictions. This is actually the business goal for building the model. Scoring usually needs to be done at scale with minimal latency, processing large sets of new records. For ADX users, the best solution for scoring is directly in ADX. ADX scoring is done on its compute nodes, in distributed manner near the data, thus achieving the best performance with minimal latency.
There are many types of models such as Bayesian models, decision trees and forests, regressions, deep neural networks and many more. These models can be built by various frameworks and/or packages like Scikit-learn, Tensorflow, CNTK, Keras, Caffe2, PyTorch etc. (here is a nice overview of ML algorithms, tools and frameworks). On one hand this variety is very good – you can find the most convenient algorithm and framework for your scenario, but on the other hand it creates an interoperability issue, as usually the ML scoring is done on infrastructure which is different from the one used for the training.
To resolve it, Microsoft and Facebook introduced in 2017 ONNX, Open Neural Network Exchange, that was adopted by many companies including AWS, IBM, Intel, Baidu, Mathworks, NVIDIA and many more. ONNX is a system for representation and serialization of ML models to a common file format. This format enables smooth switching among ML frameworks as well as allowing hardware vendors and others to improve the performance of deep neural networks for multiple frameworks at once by targeting the ONNX representation.
In this blog we explain how ADX can consume ONNX models, that were built and trained externally, for near real time scoring of new samples that are ingested into ADX.
How to use ADX for scoring ONNX models
ADX supports running Python code embedded in Kusto Query Language (KQL) using the python() plugin. The Python code is run in multiple sandboxes on ADX existing compute nodes. The Python image is based on Anaconda distribution and contains the most common ML frameworks including Scikit-learn, TensorFlow, Keras and PyTorch. To score ONNX models in ADX follow these steps:
- Develop your ML model using your favorite framework and tools
- Convert the final trained model to ONNX format
- Export the ONNX model to a table on ADX or to an Azure blob
- Score new data in ADX using the inline python() plugin
Example
We build a model to predict room occupancy based on Occupancy Detection data, a public dataset from UCI Repository. This model is a binary classifier to predict occupied/empty room based on Temperature, Humidity, Light and CO2 sensors measurements. The complete process can be found in this Jupyter notebook. Here we embed few snips just to present the main concepts
Prerequisite
- Enable Python plugin on your ADX cluster (see the Onboarding section of the python() plugin doc)
- Whitelist a blob container to be accessible by ADX Python sandbox (see the Appendix section of that doc)
- Create a Python environment (conda or virtual env) that reflects the Python sandbox image
- Install in that environment ONNX packages: onnxruntime and skl2onnx packages
- Install in that environment Azure Blob Storage package: azure-storage-blob
- Install KqlMagic to easily connect and query ADX cluster from Jupyter notebooks
Retrieve and explore the data using KqlMagic
reload_ext Kqlmagic
%config Kqlmagic.auto_dataframe = True
%kql kusto://code;cluster='demo11.westus';database='ML' -try_azcli_login
%kql df << OccupancyDetection
df[-4:]
| |
Timestamp
|
Temperature
|
Humidity
|
Light
|
CO2
|
HumidityRatio
|
Occupancy
|
Test
|
|
20556
|
2015-02-18 09:16:00.0000000
|
20.865
|
27.7450
|
423.50
|
1514.5
|
0.004230
|
True
|
True
|
|
20557
|
2015-02-18 09:16:00.0000000
|
20.890
|
27.7450
|
423.50
|
1521.5
|
0.004237
|
True
|
True
|
|
20558
|
2015-02-18 09:17:00.0000000
|
20.890
|
28.0225
|
418.75
|
1632.0
|
0.004279
|
True
|
True
|
|
20559
|
2015-02-18 09:19:00.0000000
|
21.000
|
28.1000
|
409.00
|
1864.0
|
0.004321
|
True
|
True
|
Train your model
Split the data to features (x), labels (y) and for training/testing:
train_x = df[df['Test'] == False][['Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio']]
train_y = df[df['Test'] == False]['Occupancy']
test_x = df[df['Test'] == True][['Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio']]
test_y = df[df['Test'] == True]['Occupancy']
print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)
(8143, 5) (8143,) (12417, 5) (12417,)
Train few classic models from Scikit-learn:
from sklearn import tree
from sklearn import neighbors
from sklearn import naive_bayes
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
#four classifier types
clf1 = tree.DecisionTreeClassifier()
clf2 = LogisticRegression(solver='liblinear')
clf3 = neighbors.KNeighborsClassifier()
clf4 = naive_bayes.GaussianNB()
clf1 = clf1.fit(train_x, train_y)
clf2 = clf2.fit(train_x, train_y)
clf3 = clf3.fit(train_x, train_y)
clf4 = clf4.fit(train_x, train_y)
# Accuracy on Testing set
for clf, label in zip([clf1, clf2, clf3, clf4], ['Decision Tree', 'Logistic Regression', 'K Nearest Neighbour', 'Naive Bayes']):
scores = cross_val_score(clf, test_x, test_y, cv=5, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), label))
Accuracy: 0.8605 (+/- 0.1130) [Decision Tree]
Accuracy: 0.9887 (+/- 0.0071) [Logistic Regression]
Accuracy: 0.9656 (+/- 0.0224) [K Nearest Neighbour]
Accuracy: 0.8893 (+/- 0.1265) [Naive Bayes]
The logistic regression model is the best one
Convert the model to ONNX
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# We define the input type (5 sensors readings), convert the scikit-learn model to ONNX and serialize it
initial_type = [('float_input', FloatTensorType([None, 5]))]
onnx_model = convert_sklearn(clf2, initial_types=initial_type)
bmodel = onnx_model.SerializeToString()
Test ONNX Model
Predict using ONNX runtime
import numpy as np
import onnxruntime as rt
sess = rt.InferenceSession(bmodel)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onnx = sess.run([label_name], {input_name: test_x.values.astype(np.float32)})[0]
# Verify ONNX and Scikit-learn predictions are same
pred_clf2 = clf2.predict(test_x)
diff_num = (pred_onnx != pred_clf2).sum()
if diff_num:
print(f'Predictions difference between sklearn and onnxruntime, total {diff_num} elements differ')
else:
print('Same prediction using sklearn and onnxruntime')
Same prediction using sklearn and onnxruntime
Scoring in ADX
Prerequisite
The Python image of ADX sandbox does NOT include ONNX runtime package. Therefore, we need to zip and upload it to a blob container and dynamically install from that container. Note that the blob container should be whitelisted to be accessible by ADX Python sandbox (see the appendix section of the python() plugin doc)
Here are the steps to create and upload the ONNX runtime package:
- Open Anaconda prompt on your local Python environment
- Download the onnxruntime package, run:
pip wheel onnxruntime
- Zip all the wheel files into onnxruntime-1.4.0-py36.zip (or your preferred name)
- Upload the zip file to a blob in the whitelisted blob container (you can use Azure Storage Explorer)
- Generate a SAS key with read permission to the blob
There are 2 options for retrieving the model for scoring:
- serialize the model to a string to be stored in a standard table in ADX
- copy the model to a blob container (that was previously whitelisted for access by ADX Python sandbox)
Scoring from serialized model which is stored in ADX table
Serializing the model and store it in ADX models table using KqlMagic
import pandas as pd
import datetime
models_tbl = 'ML_Models'
model_name = 'ONNX-Occupancy'
smodel = bmodel.hex()
now = datetime.datetime.now()
dfm = pd.DataFrame({'name':[model_name], 'timestamp':[now], 'model':[smodel]})
dfm
| |
name
|
timestamp
|
model
|
|
0
|
ONNX-Occupancy
|
2020-07-28 17:07:20.280040
|
08031208736b6c326f6e6e781a05312e362e3122076169…
|
set_query = '''
.set-or-append {0} <|
let tbl = dfm;
tbl
'''.format(models_tbl)
print(set_query)
.set-or-append ML_Models <|
let tbl = dfm;
tbl
%kql -query set_query
| |
ExtentId
|
OriginalSize
|
ExtentSize
|
CompressedSize
|
IndexSize
|
RowCount
|
|
0
|
bfc9acc2-3d79-4e64-9a79-d2681547e43d
|
1430.0
|
1490.0
|
1040.0
|
450.0
|
1
|
Scoring from serialized model which is stored in ADX table
# NOTE: we run ADX scoring query here using KqlMagic by embedding the query from Kusto Explorer
# with r'''Kusto Explorer query''':
# NOTE: replace the string "**** YOUR SAS KEY ****" in the external_artifacts parameter with the real SAS
scoring_from_table_query = r'''
let classify_sf=(samples:(*), models_tbl:(name:string, timestamp:datetime, model:string), model_name:string, features_cols:dynamic, pred_col:string)
{
let model_str = toscalar(models_tbl | where name == model_name | top 1 by timestamp desc | project model);
let kwargs = pack('smodel', model_str, 'features_cols', features_cols, 'pred_col', pred_col);
let code =
'n'
'import picklen'
'import binasciin'
'n'
'smodel = kargs["smodel"]n'
'features_cols = kargs["features_cols"]n'
'pred_col = kargs["pred_col"]n'
'bmodel = binascii.unhexlify(smodel)n'
'n'
'from sandbox_utils import Zipackagen'
'Zipackage.install("onnxruntime-v17-py36.zip")n'
'features_cols = kargs["features_cols"]n'
'pred_col = kargs["pred_col"]n'
'n'
'import onnxruntime as rtn'
'sess = rt.InferenceSession(bmodel)n'
'input_name = sess.get_inputs()[0].namen'
'label_name = sess.get_outputs()[0].namen'
'df1 = df[features_cols]n'
'predictions = sess.run([label_name], {input_name: df1.values.astype(np.float32)})[0]n'
'n'
'result = dfn'
'result[pred_col] = pd.DataFrame(predictions, columns=[pred_col])'
'n'
;
samples | evaluate python(typeof(*), code, kwargs, external_artifacts=pack('onnxruntime-v17-py36.zip', 'https://artifcatswestus.blob.core.windows.net/kusto/ONNX/onnxruntime-v17-py36.zip? **** YOUR SAS KEY ****')
)
};
OccupancyDetection
| where Test == 1
| extend pred_Occupancy=bool(0)
| invoke classify_sf(ML_Models, 'ONNX-Occupancy', pack_array('Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio'), 'pred_Occupancy')
'''
%kql pred_df << -query scoring_from_table_query
pred_df[-4:]
| |
Timestamp
|
Temperature
|
Humidity
|
Light
|
CO2
|
HumidityRatio
|
Occupancy
|
Test
|
pred_Occupancy
|
|
12413
|
2015-02-18 09:16:00+00:00
|
20.865
|
27.7450
|
423.50
|
1514.5
|
0.004230
|
True
|
True
|
True
|
|
12414
|
2015-02-18 09:16:00+00:00
|
20.890
|
27.7450
|
423.50
|
1521.5
|
0.004237
|
True
|
True
|
True
|
|
12415
|
2015-02-18 09:17:00+00:00
|
20.890
|
28.0225
|
418.75
|
1632.0
|
0.004279
|
True
|
True
|
True
|
|
12416
|
2015-02-18 09:19:00+00:00
|
21.000
|
28.1000
|
409.00
|
1864.0
|
0.004321
|
True
|
True
|
True
|
print('Confusion Matrix')
pred_df.groupby(['Occupancy', 'pred_Occupancy']).size()
Confusion Matrix
Occupancy pred_Occupancy
False False 9284
True 112
True False 15
True 3006
Scoring from model which is stored in blob storage
Copy the model to blob
Note again that the blob container should be whitelisted to be accessible by ADX Python sandbox
from azure.storage.blob import BlobClient
conn_str = "BlobEndpoint=https://artifcatswestus.blob.core.windows.net/kusto;SharedAccessSignature=?**** YOUR SAS KEY ****"
blob_client = BlobClient.from_connection_string(conn_str, container_name="ONNX", blob_name="room_occupancy.onnx")
res = blob_client.upload_blob(bmodel, overwrite=True)
# NOTE: we run ADX scoring query here using KqlMagic by embedding the query from Kusto Explorer
# with r'''Kusto Explorer query''':
# NOTE: replace the strings "**** YOUR SAS KEY ****" below with the respective real SAS
scoring_from_blob_query = r'''
let classify_sf=(samples:(*), model_sas:string, features_cols:dynamic, pred_col:string)
{
let kwargs = pack('features_cols', features_cols, 'pred_col', pred_col);
let code =
'n'
'from sandbox_utils import Zipackagen'
'Zipackage.install("onnxruntime-v17-py36.zip")n'
'features_cols = kargs["features_cols"]n'
'pred_col = kargs["pred_col"]n'
'n'
'import onnxruntime as rtn'
'sess = rt.InferenceSession(r"C:Tempmodel.onnx")n'
'input_name = sess.get_inputs()[0].namen'
'label_name = sess.get_outputs()[0].namen'
'df1 = df[features_cols]n'
'predictions = sess.run([label_name], {input_name: df1.values.astype(np.float32)})[0]n'
'n'
'result = dfn'
'result[pred_col] = pd.DataFrame(predictions, columns=[pred_col])'
'n'
;
samples | evaluate python(typeof(*), code, kwargs,
external_artifacts=pack('model.onnx', model_sas,
'onnxruntime-v17-py36.zip', 'https://artifcatswestus.blob.core.windows.net/kusto/ONNX/onnxruntime-v17-py36.zip? **** YOUR SAS KEY ****')
)
};
OccupancyDetection
| where Test == 1
| extend pred_Occupancy=bool(0)
| invoke classify_sf('https://artifcatswestus.blob.core.windows.net/kusto/ONNX/room_occupancy.onnx? **** YOUR SAS KEY ****',
pack_array('Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio'), 'pred_Occupancy')
'''
%kql pred_df << -query scoring_from_blob_query
pred_df[-4:]
| |
Timestamp
|
Temperature
|
Humidity
|
Light
|
CO2
|
HumidityRatio
|
Occupancy
|
Test
|
pred_Occupancy
|
|
12413
|
2015-02-18 09:16:00+00:00
|
20.865
|
27.7450
|
423.50
|
1514.5
|
0.004230
|
True
|
True
|
True
|
|
12414
|
2015-02-18 09:16:00+00:00
|
20.890
|
27.7450
|
423.50
|
1521.5
|
0.004237
|
True
|
True
|
True
|
|
12415
|
2015-02-18 09:17:00+00:00
|
20.890
|
28.0225
|
418.75
|
1632.0
|
0.004279
|
True
|
True
|
True
|
|
12416
|
2015-02-18 09:19:00+00:00
|
21.000
|
28.1000
|
409.00
|
1864.0
|
0.004321
|
True
|
True
|
True
|
print('Confusion Matrix')
pred_df.groupby(['Occupancy', 'pred_Occupancy']).size()
Confusion Matrix
Occupancy pred_Occupancy
False False 9284
True 112
True False 15
True 3006
Summary
In this tutorial we showed how to train a model in Scikit-learn, convert it to ONNX format and export it to ADX for scoring. This workflow is convenient as
- Training can be done on any hardware platform, using any framework supporting ONNX
- Scoring is done in ADX near the data, on the existing compute nodes, enabling near real time processing of big amounts of new data. There is no the need to export the data to external scoring service and import back the results. Consequently, scoring architecture is simpler and performance is much faster and scalable
by Scott Muniz | Jul 29, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Howdy folks!
Today we’re announcing the public preview of Azure AD Application Proxy (App Proxy) support for the Remote Desktop Services (RDS) web client. Many of you are already using App Proxy for applications hosted on RDS and we’ve seen a lot of requests for extending support to the RDS web client as well.
With this preview, you can now use the RDS web client even when App Proxy provides secure remote access to RDS. The web client works on any HTML5-capable browser such as Microsoft Edge, Internet Explorer 11, Google Chrome, Safari, or Mozilla Firefox (v55.0 and later). You can push full desktops or remote apps to the Remote Desktop web client. The remote apps are hosted on the virtualized machine but appear as if they’re running on the user’s desktop like local applications. The apps also have their own taskbar entry and can be resized and moved across monitors.
 Launch rich client apps with a full desktop like experience
Launch rich client apps with a full desktop like experience
Why use App Proxy with RDS?
RDS allows you to extend virtual desktops and applications to any device while helping keep critical intellectual property secure. By using this virtualization platform, you can deploy all types of applications such as Windows apps and other rich client apps as-is with no re-writing required. By using App Proxy with RDS you can reduce the attack surface of your RDS deployment by enforcing pre-authentication and Conditional Access policies like requiring Multi-Factor Authentication (MFA) or using a compliant device before users can access RDS. App Proxy also doesn’t require you to open inbound connections through your firewall.
Getting started
To use the RDS web client with App Proxy, first make sure to update your App Proxy connectors to the latest version, 1.5.1975.0. If you haven’t already, you will need to configure RDS to work with App Proxy. In this configuration, App Proxy will handle the internet facing component of your RDS deployment and protect all traffic with pre-authentication and any Conditional Access policies in place. For steps on how to do this, see Publish Remote Desktop with Azure AD Application Proxy.
 How Azure AD App Proxy works in an RDS deployment
How Azure AD App Proxy works in an RDS deployment
Configure the Remote Desktop web client
Next, complete setup by enabling the Remote Desktop web client for user access. See details on how to do this at Set up the Remote Desktop web client for your users. Now your users can use the external URL to access the client from their browser, or they can launch the app from the My Apps portal.
As always, we’d love to hear any feedback or suggestions you may have. Please let us know what you think in the comments below or on the Azure AD feedback forum.
Best regards,
Alex Simons (@alex_a_simons)
Corporate Vice President Program Management
Microsoft Identity Division
Learn more about Microsoft identity:

Recent Comments