This article is contributed. See the original author and article here.
Introduction
Did you know that you can use Microsoft Fabric to copy data at scale from on-premises SQL Server to Azure SQL Database or Azure SQL Managed Instance within minutes?
It is often required to copy data from on-premises to Azure SQL database, Azure SQL Managed Instance or to any other data store for data analytics purposes. You may simply want to migrate data from on-premises data sources to Azure Database Services. You will most likely want to be able to do this data movement at scale, with minimal coding and complexity and require an automated and simple approach to handle such scenarios.
In the following example, I am copying 2 tables from an On-premises SQL Server 2019 database to Azure SQL Database using Microsoft Fabric. The entire migration is driven through a metadata table approach, so the copy pipeline is simple and easy to deploy. We have used this approach to copy hundreds of tables from one database to another efficiently. The monitoring UI provides flexibility and convenience to track the progress and rerun the data migration in case of any failures. The entire migration is driven using a database table that holds the information about the tables to copy from the source.
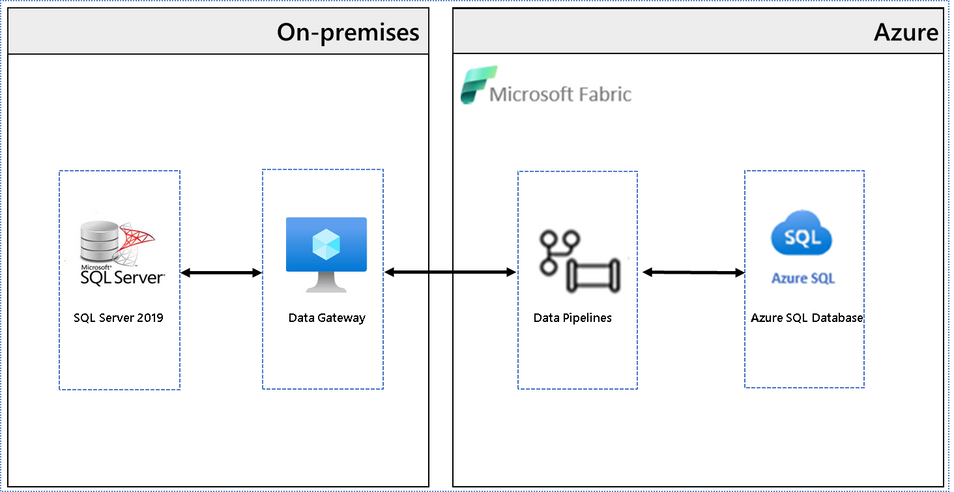
Architecture diagram
This architectural diagram shows the components of the solution from SQL Server on-premises to Microsoft Fabric.
Steps
Install data gateway:
To connect to an on-premises data source from Microsoft Fabric, a data gateway needs to be installed. Use this link to install an on-premises data gateway | Microsoft Learn
Create a table to hold metadata information:
First, let us create this table in the target Azure SQL Database.
CREATE TABLE [dbo].[Metadata](
[Id] [int] IDENTITY(1,1) NOT NULL,
[DataSet] [nvarchar](255) NULL,
[SourceSchemaName] [nvarchar](255) NULL,
[SourceTableName] [nvarchar](255) NULL,
[TargetSchemaName] [nvarchar](255) NULL,
[TargetTableName] [nvarchar](255) NULL,
[IsEnabled] [bit] NULL
)
I intend to copy two tables – Customer and Sales – from the source to the target. Let us insert these entries into the metadata table. Insert one row per table.
INSERT [dbo].[Metadata] ([DataSet], [SourceSchemaName], [SourceTableName], [TargetSchemaName], [TargetTableName], [IsEnabled]) VALUES (N'Customer', N'dbo', N'Customer', N'dbo', N'Customer', 1);
INSERT [dbo].[Metadata] ([DataSet], [SourceSchemaName], [SourceTableName], [TargetSchemaName], [TargetTableName], [IsEnabled]) VALUES (N'Sales', N'dbo', N'Sales', N'dbo', N'Sales', 1);
Ensure that the table is populated. The data pipelines will use this table to drive the migration.

Create Data Pipelines:
Open Microsoft Fabric and click create button to see the items you can create with Microsoft Fabric.

Click on “Data pipeline” to start creating a new data pipeline.

Let us name the pipeline “Copy_Multiple_Tables”.

Click on “Add pipeline activity” to add a new activity.

Choose Azure SQL Database from the list. We will create the table to hold metadata in the target.

Ensure that the settings are as shown in the screenshot.

Click the preview data button and check if you can view the data from the table.

Let us now create a new connection to the source. From the list of available connections, choose SQL Server, as we intend to copy data from SQL Server 2019 on-premises. Ensure that the gateway cluster and connection are already configured and available.

Add a new activity and set the batch count to copy tables in parallel.

We now need to set the Items property, which is dynamically populated at runtime. To set this click on this button as shown in the screenshot and set the value as:
@activity('Get_Table_List').output.value


Add a copy activity to the activity container.

Set the source Table attributes in the copy activity as shown in the screenshot. Click on the edit button and click the “Add dynamic content” button. Ensure that you paste the text only after you click the “Add dynamic content” button, otherwise, the text will not render dynamically during runtime.
Set the Table schema name to:
@item().SourceSchemaName
Set the Table name to:
@item().SourceTableName

Click on the destination tab and set the destination attributes as in the screenshot.
Set the Table schema name to:
@item().TargetSchemaName
Set the Table name to:
@item().TargetTableName

We have configured the pipeline. Now click on save to publish the pipeline.

Run pipeline:
Click the Run button from the top menu to execute the pipeline. Ensure the pipeline runs successfully. This will copy both tables from source to target.

Summary:
In the above example, we have used Microsoft Fabric pipelines to copy data from an on-premises SQL Server 2019 database to Azure SQL Database. You can modify the sink/destination in this pipeline to copy to other sources such as Azure SQL Managed Instance or Azure Database for PostgreSQL. If you are interested in copying data from a mainframe z/OS database, then you will find this blog post from our team also very helpful.
Feedback and suggestions
If you have feedback or suggestions for improving this data migration asset, please contact the Azure Databases SQL Customer Success Engineering Team. Thanks for your support!
Note: For additional information about migrating various source databases to Azure, see the Azure Database Migration Guide.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments