This article is contributed. See the original author and article here.
Azure Synapse Analytics is a limitless data analytics service that enables you to analyze data on Azure Data Lake storage. It provides managed Apache Spark and T-SQL engines (provisioned and serverless) for analyzing data.
In this article, you will see how you can create a table that references data on external Azure Data Lake storage in order to enable the client applications such as Power BI to create reports on Data Lake information. The data set is placed on Azure storage and formatted as parquet, but client applications can access these data as any other table without need to know where is stored actual data.
Prerequisite
To try this sample, you need to have Azure Synapse Analytics workspace. If you don’t have one you can easily deploy it using Azure portal or this Deployment template. Workspace automatically deploys one serverless Synapse SQL endpoint that is everything we need for this kind of analysis. With the workspace you are also getting easy-to-use Web UI called Synapse Studio that enables you to start analyzing the files directly from your browser.
NOTE: You need Synapse SQL serverless (on-demand) query endpoint to execute the code in this article.
COVID data set
In this sample is used the latest available public data on geographic distribution of COVID-19 cases worldwide from the European Center for Disease Prevention and Control (ECDC). Each row/entry contains the number of new cases reported per day and per country. For more information about this dataset, see here. Data set is updated on daily basis and placed as a part of Azure Open Dataset.
Configuring data sources and formats
As a first step you need to configure data source and specify file format of remotely stored files.
CREATE EXTERNAL DATA SOURCE ecdc_cases WITH (
LOCATION = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/'
);
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );
First statement creates data source that references ECDC COVID data set, while the second specifies parquet file format.
Exploring file schema
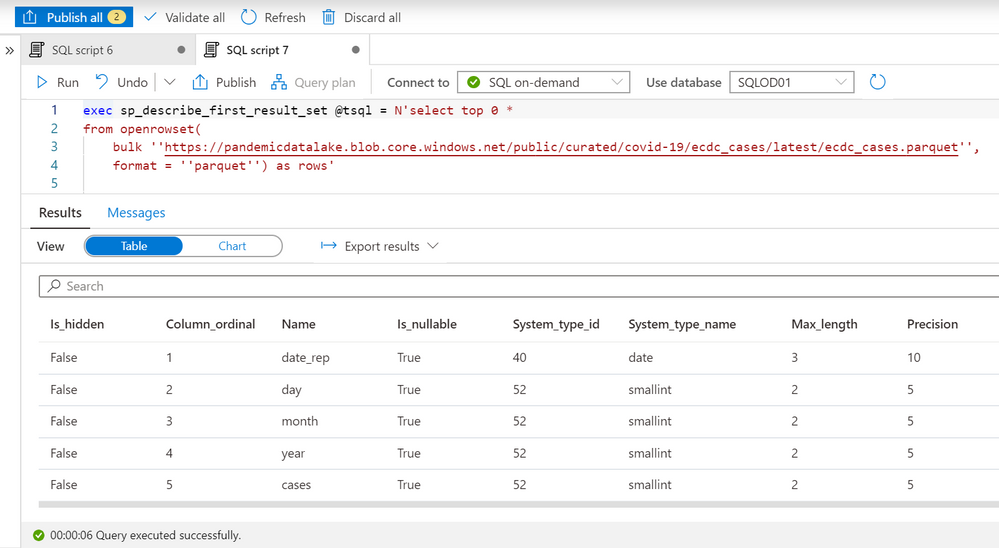
Now you need to determine what are the columns in the external files and what are their types. In the previous article you might have seen that OPENROWSET function enables you to quickly explore data in the files placed on Azure storage. We can also use sp_describe_first_result_set function to identify the schema that will be used for the table by providing the OPENROWSET data exploration query to this procedure:

The most important columns are name and system_type_name that we can use to create schema of external table that references this file. The easiest way to use these information to create a table is to export data in Excel, hide the columns between name and system_type_name and copy the values:

Creating an external table
Now we have all elements required to create a table. I will create one schema (this is optional but recommended), paste the results that I copied from Excel, and reference data_source/file_format that I created in the previous step:
create schema ecdc
go
create external table ecdc.cases (
date_rep date,
day smallint,
month smallint,
year smallint,
cases smallint,
deaths smallint,
countries_and_territories varchar(8000),
geo_id varchar(8000),
country_territory_code varchar(8000),
pop_data_2018 int,
continent_exp varchar(8000),
load_date datetime2(7),
iso_country varchar(8000)
) with (
data_source= ecdc_cases,
location = 'latest/ecdc_cases.parquet',
file_format = ParquetFormat
);
The only additional information that I need to provide is the location of the files that this external table references.
IMPORTANT: You need to run this statement in some database other than master! Master database don’t allow you to create objects (schemas, tables).
Now, we can read the content of external files using this table:

The query is executed via Synapse Studio, but I can use any other tool like PowerBI, Excel, SSMS, ADS to query my external table.
Conclusion
External tables in Azure Synapse SQL query engine represent logical relational adapter created on top of externally stored files that can be used by any application that use TSQL to query data. This way you can build a Logical Data Warehouse on top of your data stored in Azure Data Lake without need to load data in standard relational table. Azure Synapse SQL Logical Data Warehouse enables you to represent external data sources as standard tables and let you analytic/reporting applications access any data without need to know where the data is place and hot to parse the data structure.
You can find more details about the external tables in Azure Synapse documentation.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments