This article is contributed. See the original author and article here.
Hi Everyone!
My Name is Fabian Scherer, Customer Engineer (CE – formally PFE) at Microsoft Germany for Microsoft Endpoint Manager related topics.
Challenge
During the daily challenges at Customer Environments one thing was coming to my mind on every Engagement. No one trusts the monitoring status of their Console.

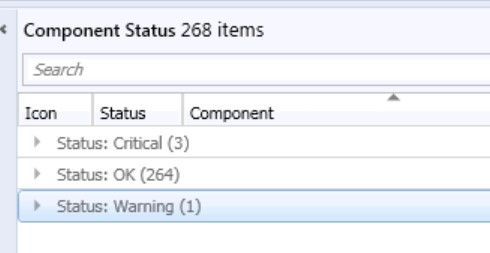
This is a familiar look in the morning at every Infrastructure I have seen during the past years. During the day, the counts are shifting a little bit but at midnight during the Status Summarizer Reset everything will go back to green and on the next day everything repeats. The most Customers are monitoring the Systems and will be notified if there is a bigger Issue with one of the Servers. But that’s an reactive Solution.
If you ask anyone about the status, the answers are always the same:
- We can’t trust this status
- If there is a big issue, we will get a Notification
- Our Infrastructure is too big
But if you want to get from the reactive to the proactive side it’s necessary to edit the Thresholds of the Stats in your Environment and to change the handling of the Supporters to a new level.
In this Blog I want to show you the journey we have taken to get to this point.
Preparation
After the decision to change the whole process the biggest and most annoying part of the project starts, the Preparation Phase. During this phase you must start to collect all the relevant data for your own infrastructure. This includes:
- Technical Understanding
- Listing Classification of your Components
- Thresholds during the past two weeks
- Status Messages which can be ignored
Technical Understanding
First, it is important to understand how the Threshold Topic works. You got all the Components at your Infrastructure and defined Thresholds like this:

(located at Administration > Site Configuration > Status Summarizers à Component Status Summarizer)
This means that the Component SMS_AD_SECURITY_GROUP_DISCOVERY needs 2,000 Messages of the Type Information to get to the Status Warning and 5,000 to get at the Critical state.

It also needs 10 Warning Messages to change to Warning and 50 Warnings to change to Critical state.

In Addition, it needs 1 Error Message to Change at the Warning State and 5 Error Messages to change to the Critical state.
This Defaults will make sense for some Components, but every Environment is different and needs separate Thresholds. Even at a Hierarchy you can’t compare Site A to Site B if there is a different count on Clients and Distribution Points.
One thing should also be clear – there is an separate Component named SMS_COMPONENT_STATUS_SUMMARIZER which detects if the Threshold of one Component is reached and switch it to the defined Status.
Listing Classification of your Components
So, let’s start on the top and list all Components in an Excel List.

After that you should also add the Systems where every of these Components is installed. When finally all Components are listed and linked to the Site Systems, you should start to tag the components with different Categories like this:
- Not installed
- Components which are not installed and shouldn’t be watched
- Not Relevant
- Components which are installed but currently not in Use
- Basic
- Components which are used by the Departments but just must be watched during Error and Warnings
- Important
- Components which are important for the Departments and there should be an investigation if something isn’t working in regular ways
- Critical
- Components which shows Critical Workflows and should be investigated as soon as something is strange

Thresholds during the past two weeks
As mentioned before the Count of Messages is relevant. So, you should start studying the Counts of Information, Warning and Error Messages for each Component during at least the past two weeks and wrote them down.

Some other Environment Issues like ‘Managements Points with a lower workload’ or ‘Distribution Points where the Site Server was unable to read the Registry’ got lighted out. This could be addressed during the Preparation Phase and were shown as good Quick Wins.
After you listed all the Message Counts you will be able to get an view all over the Weeks and to define how much Errors on some Components are ‘Normal’ and where too many Information Messages may can be Critical for the Environment.
Status Messages which can be ignored
On my Investigation, I found some Messages without any Sense for this Environment and Excluded them to minimize the Messages. For Example:
Message ID 9520 on SMS_DISTRIBUTION_MANAGER informs you that a Distribution will not take place because the Distribution Point is set on Maintenance Mode.
There are more Messages that could be not relevant for your own Environment, but you must detect and decide it by yourself.
Definition
After collecting all this Data it’s time to define new Thresholds for each Component on each Site. As first Key Factor you should choose the defined Category:
|
Category |
Information to Warning |
Information to Critical |
Warning to Warning |
Warning to Critical |
Critical to Warning |
Critical to Critical |
|
Not Installed |
– |
– |
– |
– |
– |
– |
|
Not Relevant |
– |
– |
– |
– |
– |
– |
|
Basic |
Unlimited |
Unlimited |
Individual Defined |
Individual Defined |
1 |
2 |
|
Important |
Double the Daily average Plus 2 |
Triple the Daily average Plus 2 |
1 |
2 |
1 |
2 |
|
Critical |
Daily Average Plus 2 |
Double the Daily Average Plus 2 |
1 |
2 |
1 |
2 |
(Note: The Information that the Component has been switched will also add one Message to your count.)
Examples:
- SMS_SITE_BACKUP | CAS | Critical | IW 12, IC 25, WW 1, WC 2, CW 1 CC 2
This Component on the CAS is writing 11 Information Messages per Day the whole Time I was spectating. If it’s writing more than 11 Messages, it’s important for me to see what’s different and if there is something we need to Investigate.
- SMS_SITE_SQL_BACKUP_% | SQL CAS | Critical | IW 5, IC 11, WW 1, WC 2, CW 2 CC 3
This Component on the SQL System related to the CAS is writing 4 Messages per Day the whole Time I was spectating. It also wrote 1 Error Message every Night. This was during the SMS_SITE_BACKUP and after one hour everything was fine. So, I accept the 1 Error Message per Night and let this Component switch after the Second Error Message.
Recommendation:
Discuss this step with all Units which are involved at your daily Business. They can show you some aspects you may not notice.
Implementation
After the Definition, the technically Part comes up. As mentioned before the Thresholds are defined at the GUI:
Administration > Site Configuration > Status Summarizers > Component Status Summarizer
But you can also list it using WMI:
WQL:
rootSMSSite_Sitecode
Select * from SMS_SCI_Component where ItemName like '%sms_component_Status_summarizer%'

Powershell:
$SiteCode = "<SiteCode>"
$ComputerName = "<FQDN>"
$QueryString = "Select * from SMS_SCI_Component where ItemName like '%sms_component_status_summarizer%' and SiteCode='$SiteCode'"
$WMIObjects = Get-WmiObject -Namespace "rootsmssite_$SiteCode" -Query $QueryString -Impersonation 3 -ComputerName $Computername
$PropList = $WMIObjects.PropLists
$Property = $PropList | where {$_.PropertyListName -eq "Component Thresholds"}
$Values = $Property.Values

And also by using SQL:
select * from SC_Component_PropertyList where Name = 'Component Thresholds' and SiteNumber = '<SiteNumber>'

The SiteNumber can be detected by watching the SiteControlFile:
select * from vSMS_SC_SiteControlXML
The most uncomplicated (but also the longest way) to update the Thresholds is using the Console but it’s a pity to update all Files using the GUI:
4 Site Systems * 6 Entries * 70 Components would be 1.680 entries that must be manually edited.
The smartest way is using SQL. But be careful – The command must be exactly been executed. If you forget to define the Name your Environment will be crashed. So please perform a Backup before you try to edit the Thresholds and use the whole Command. I copied the Values of the .xml File at the SQL query and edited the defined thresholds.
Index:
IW = Information Messages to get The Warning State
IE = Information Messages to get the Critical State
WW = Warning Messages to get the Warning State
WE = Warning Messages to get the Critical State
EW = Error Messages to get the Warning State
EE = Error Message to get the Critical State
!YOU WILL HAVE TO UPDATE THE WHOLE XML FILE, NOT JUST THE ENTRIES YOU WANT TO EDIT!
If you choose this way you can use the following Query:
update SC_Component_PropertyList SET Value = '<The whole XML File>' where Name = 'Component Thresholds' AND SiteNumber = '<SiteNumber>'
It is possible that the defined Thresholds will be overwritten with the Default during an SCCM CB Update. So please check the Settings after every Update. You should also be aware of new Components releases with any Version.

Additional Words
This Adjustment is not the End of the Process – it’s the Start. After you have done the first part you can choose the possibilities and develop it to a new level. Some Thresholds will have to be edited later. You should implement a Documentation to get rid of recurrently appearing Issues and you can define Rules, E-Mail Messages or Actions that should be performed after special Events appear. It’s just the first step out of the reactive Support moving to a Proactive Service and an Improvement of your Service Quality.
Fabian Scherer
CE
Disclaimer
The sample scripts are not supported under any Microsoft standard support program or service. The sample scripts are provided AS IS without warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments