This article is contributed. See the original author and article here.
We recently released a new version of MSTICPy with a feature called Pivot functions.
This feature has three main goals:
- Making it easy to discover and invoke MSTICPy functionality.
- Creating a standardized way to call pivotable functions.
- Letting you assemble multiple functions into re-usable pipelines.
The pivot functionality exposes operations relevant to a particular entity as methods (or functions) of that entity. These operations include:
- Data queries
- Threat intelligence lookups
- Other data lookups such as geo-location or domain resolution
- and other local functionality
Here are a couple of examples showing calling different kinds of enrichment functions from the IpAddress entity:
>>> from msticpy.datamodel.entities import IpAddress, Host
>>> IpAddress.util.ip_type(ip_str=“157.53.1.1”))
ip result 157.53.1.1 Public
>>> IpAddress.util.whois(“157.53.1.1”))
asn asn_cidr asn_country_code asn_date asn_description asn_registry nets …..
NA NA US 2015–04–01 NA arin [{‘cidr’: ‘157.53.0.0/16’… >>> IpAddress.util.geoloc_mm(value=“157.53.1.1”)) CountryCode CountryName State City Longitude Latitude Asn… US United States None None –97.822 37.751 None…
This second example shows a pivot function that does a data query for host logon events from a Host entity.
>>> Host.AzureSentinel.list_host_logons(host_name=“VictimPc”)
Account EventID TimeGenerated Computer SubjectUserName SubjectDomainName
NT AUTHORITYSYSTEM 4624 2020–10–01 22:39:36.987000+00:00 VictimPc.Contoso.Azure VictimPc$ CONTOSO
You can also add other functions from 3rd party Python packages or ones you write yourself as pivot functions.
Terminology
Before we get into things let’s clear up a few terms.
Entities – These are Python classes that represent real-world objects commonly encountered in CyberSec investigations and hunting. E.g., Host, URL, IP Address, Account, etc.
Pivoting – This comes from the common practice in CyberSec investigations of navigating from one suspect entity to another. E.g., you might start with an alert identifying a potentially malicious IP Address, from there you ‘pivot’ to see which hosts or accounts were communicating with that address. From there you might pivot again to look at processes running on the host or Office activity for the account.
Background reading
This article is available in Notebook form so that you can try out the examples. [TODO]
There is also full documentation of the Pivot functionality on our ReadtheDocs page.
Life before pivot functions
Before Pivot functions your ability to use the various bits of functionality in MSTICPy was always bounded by your knowledge of where a certain function was (or your enthusiasm for reading the docs).
For example, suppose you had an IP address that you wanted to do some simple enrichment on.
ip_addr = “20.72.193.242”
First, you’d need to locate and import the functions. There might also be (as in the GeoIPLiteLookup class) some initialization step you’d need to do before using the functionality.
from msticpy.sectools.ip_utils import get_ip_type
from msticpy.sectools.ip_utils import get_whois_info
from msticpy.sectools.geoip import GeoLiteLookup
geoip = GeoLiteLookup()
Next you might have to check the help for each function to work it parameters.
>>> help(get_ip_type)
Help on function get_ip_type in module msticpy.sectools.ip_utils:
get_ip_type(ip: str = None, ip_str: str = None) -> str
Validate value is an IP address and deteremine IPType category. …
Then finally run the functions.
>>> get_ip_type(ip_addr)
‘Public’
>>> get_whois_info(ip_addr)
(‘MICROSOFT-CORP-MSN-AS-BLOCK, US’,
{‘nir’: None, ‘asn_registry’: ‘arin’, ‘asn’: ‘8075’, ‘asn_cidr’: ‘20.64.0.0/10’, ‘asn_country_code’: ‘US’, ‘asn_date’: ‘2017-10-18’, ‘asn_description’: ‘MICROSOFT-CORP-MSN-AS-BLOCK, US’, ‘query’: ‘20.72.193.242’, ‘nets’: …
>>> geoip.lookup_ip(ip_addr)
([{‘continent’:
{‘code’: ‘NA’, ‘geoname_id’: 6255149, ‘names’:
{‘de’: ‘Nordamerika’, ‘en’: ‘North America’, ‘es’: ‘Norteamérica’, ‘fr’: ‘Amérique du Nord’, ‘ja’: ‘北アメリカ’, ‘pt-BR’: ‘América do Norte’, ‘ru’: ‘Северная Америка’, ‘zh-CN’: ‘北美洲’}}, ‘country’: {‘geoname_id’: 6252001, ‘iso_code’: ‘US’, ‘names’: {‘de’: ‘USA’, ‘en’: ‘United States’, ‘es’: ‘Estados Unidos’, …
At which point you’d discover that the output from each function was somewhat raw and it would take a bit more work if you wanted to combine it in any way (say in a single table).
In the rest of the article we’ll show you how Pivot functions make it easier to discover data and enrichment functions. We’ll also show how pivot functions bring standardization and handle different types of input (including lists and DataFrames) and finally, how the standardized output lets you chain multiple pivot functions together into re-usable pipelines of functionality.
Getting started with pivot functions
Let’s get started with how to use Pivot functions.
Typically, we use MSTICPy‘s init_notebook function at the start of any notebook. This handles checking versions and importing some commonly-used packages and modules (both MSTICPy and 3rd party packages like pandas).
>>> from msticpy.nbtools.nbinit import init_notebook
>>> init_notebook(namespace=globals());
Processing imports……..
Then there are a couple of preliminary steps needed before you can use pivot functions. The main one is loading the Pivot class.
Pivot functions are added to the entities dynamically by the Pivot class. The Pivot class will try to discover relevant functions from queries, Threat Intel providers and various utility functions.
In some cases, notably data queries, the data query functions are themselves created dynamically, so these need to be loaded before you create the Pivot class. (You can always create a new instance of this class, which forces re-discovery, so don’t worry if mess up the order of things).
Note in most cases we don’t need to connect/authenticate to a data provider prior to loading Pivot.
Let’s load our data query provider for AzureSentinel.
>>> az_provider = QueryProvider(“AzureSentinel”)
Please wait. Loading Kqlmagic extension…
Now we can load and instantiate the Pivot class.
>>> from msticpy.datamodel.pivot import Pivot
>>> pivot = Pivot(namespace=globals())
Why do we need to pass “namespace=globals()”?
Pivot searches through the current objects defined in the Python/notebook namespace to find provider objects that it will use to create the pivot functions. This is most relevant for QueryProviders – when you create a Pivot class instance it will find and use the relevant queries from the az_provider object that we created in the previous step. In most other cases (like GeoIP and ThreatIntel providers, it will create new ones if it can’t find existing ones).
Easy discovery of functionality
Find the entity name you need
The simplest way to do this is simply enumerate (using Python dir() function) the contents of the MSTICPy entities sub-package. This should have already been imported by the init_notebook function that we ran earlier.
The items at the beginning of the list with proper capitalization are the entities.
>>> dir(entities)
[‘Account’, ‘Alert’, ‘Algorithm’, ‘AzureResource’, ‘CloudApplication’, ‘Dns’, ‘ElevationToken’, ‘Entity’, ‘File’, ‘FileHash’, ‘GeoLocation’, ‘Host’, ‘HostLogonSession’, ‘IpAddress’, ‘Malware’, …
We’re going to make this a little more elegant in a forthcoming update with this helper function.
>>> entities.find_entity(“ip”)
Match found ‘IpAddress’msticpy.datamodel.entities.ip_address.IpAddress
Listing pivot functions available for an entity
Note you can always address an entity using its qualified path, e.g. “entities.IpAddress” but if you are going to use one or two entities a lot, it will save a bit of typing if you import them explicitly.
>>> from msticpy.datamodel.entities import IpAddress, Host
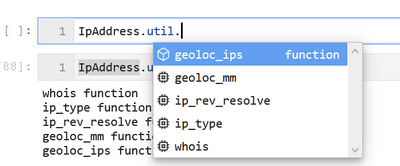
Once you have the entity loaded, you can use the get_pivot_list() function to see which pivot functions are available for it. The example below has been abbreviated for space reasons.
>>> IpAddress.get_pivot_list()
[‘AzureSentinel.SecurityAlert_list_alerts_for_ip’,
‘AzureSentinel.SigninLogs_list_aad_signins_for_ip’,
‘AzureSentinel.AzureActivity_list_azure_activity_for_ip’,
‘AzureSentinel.AzureNetworkAnalytics_CL_list_azure_network_flows_by_ip’,
…
‘ti.lookup_ip’,
‘ti.lookup_ipv4’,
‘ti.lookup_ipv4_OTX’,
…
‘ti.lookup_ipv6_OTX’,
‘util.whois’,
‘util.ip_type’,
‘util.ip_rev_resolve’,
‘util.geoloc_mm’,
‘util.geoloc_ips’]
Some of the function names are a little unwieldy but, in many cases, this is necessary to avoid name collisions. You will notice from the list that the functions are grouped into containers: “AzureSentinel”, “ti” and “util” in the above example.
Although this makes the function name even longer, we thought that this helped to keep related functionality together – so you don’t get a TI lookup function, when you thought you were running a query.
Fortunately, Jupyter notebooks/IPython support tab completion so you should not normally have to remember these names.
The containers (“AzureSentinel”, “util”, etc.) are also callable functions – they just return the list of functions they contain.
>>> IpAddress.util()
whois functionip_type functionip_rev_resolve functiongeoloc_mm functiongeoloc_ips function
Now we’re ready to run any of the functions for this entity (we take the same initial examples from the “Life before pivot functions” plus a few more).
>>> IpAddress.util.ip_type(ip_addr)
ip | result | |
0 | 20.72.193.242 | Public |
>>> IpAddress.util.whois(ip_addr)
asn | asn_cidr | asn_country_code | asn_date | asn_description | asn_registry | nets | |
0 | 8075 | 20.64.0.0/10 | US | 2017-10-18 | MICROSOFT-CORP-MSN-AS-BLOCK, US | arin | [{‘cidr’: ‘20.128.0.0/16, 20.48, … |
>>> IpAddress.util.ip_rev_resolve(ip_addr)
qname | rdtype | response | ip_address | |
0 | 20.72.193.242 | PTR | The DNS query name does not exist: 20.72.193.242. | 20.72.193.242 |
>>> IpAddress.util.geoloc_mm(ip_addr)
CountryCode | CountryName | State | City | Longitude | Latitude | Asn | edges | Type | AdditionalData | IpAddress | |
0 | US | United States | Washington | None | -122.3412 | 47.6032 | None | {} | geolocation | {} | 20.72.193.242 |
>>> IpAddress.ti.lookup_ip(ip_addr)
Ioc | IocType | SafeIoc | QuerySubtype | Provider | Result | Severity | Details | |
0 | 20.72.193.242 | ipv4 | 20.72.193.242 | None | Tor | True | information | Not found. |
0 | 20.72.193.242 | ipv4 | 20.72.193.242 | None | VirusTotal | True | unknown | {‘verbose_msg’: ‘Missing IP address’, ‘response_code’: 0} |
0 | 20.72.193.242 | ipv4 | 20.72.193.242 | None | XForce | True | warning | {‘score’: 1, ‘cats’: {}, ‘categoryDescriptions’: {}, ‘reason’: ‘Regional Internet Registry’, ‘re… |
Notice that we didn’t need to worry about either the parameter name or format (more on this in the next section). Also, whatever the function, the output is always returned as a pandas DataFrame.
For Data query functions you do need to worry about the parameter name
Data query functions are slightly more complex than most other functions and specifically often support many parameters. Rather than try to guess which parameter you meant, we require you to be explicit about it.
Before we can use a data query, we need to authenticate to the provider.
>>> az_provider.connect(WorkspaceConfig(workspace=“CyberSecuritySoc”).code_connect_str)
If you are not sure of the parameters required by the query you can use the built-in help
>>> Host.AzureSentinel.SecurityAlert_list_related_alerts?
Signature: Host.AzureSentinel.SecurityAlert_list_related_alerts(*args, **kwargs) -> Union[pandas.core.frame.DataFrame, Any]
Docstring:
Retrieves list of alerts with a common host, account or process
Parameters
———-
account_name: str (optional)
The account name to find
add_query_items: str (optional)
Additional query clauses
end: datetime (optional)
Query end time
host_name: str (optional)
The hostname to find
path_separator: str (optional)
Path separator (default value is: )
process_name: str (optional) …
In this case we want the “host_name” parameter.
>>> Host.AzureSentinel.SecurityAlert_list_related_alerts(host_name=“victim00”).head(5)
TenantId | TimeGenerated | AlertDisplayName | AlertName | Severity | Description | ProviderName | VendorName | VendorOriginalId | SystemAlertId | ResourceId | SourceComputerId | AlertType | ConfidenceLevel | ConfidenceScore | IsIncident | StartTimeUtc | EndTimeUtc | ProcessingEndTime | RemediationSteps | ExtendedProperties | Entities | SourceSystem | WorkspaceSubscriptionId | WorkspaceResourceGroup | ExtendedLinks | ProductName | ProductComponentName | AlertLink | Status | CompromisedEntity | Tactics | Type | Computer | src_hostname | src_accountname | src_procname | host_match | acct_match | proc_match | |
0 | 8ecf8077-cf51-4820-aadd-14040956f35d | 2020-12-10 09:10:08+00:00 | Suspected credential theft activity | Suspected credential theft activity | Medium | This program exhibits suspect characteristics potentially associated with credential theft. Onc… | MDATP | Microsoft | da637426874826633442_-1480645585 | a429998b-8a1f-a69c-f2b8-24dedde31c2d | WindowsDefenderAtp | NaN | False | 2020-12-04 14:00:00+00:00 | 2020-12-04 14:00:00+00:00 | 2020-12-10 09:10:08+00:00 | [rn “1. Make sure the machine is completely updated and all your software has the latest patc… | {rn “MicrosoftDefenderAtp.Category”: “CredentialAccess”,rn “MicrosoftDefenderAtp.Investiga… | [rn {rn “$id”: “4”,rn “DnsDomain”: “na.contosohotels.com”,rn “HostName”: “vict… | Detection | Microsoft Defender Advanced Threat Protection | https://securitycenter.microsoft.com/alert/da637426874826633442_-1480645585 | New | victim00.na.contosohotels.com | CredentialAccess | SecurityAlert | victim00 | victim00 | True | False | False | |||||||||
1 | 8ecf8077-cf51-4820-aadd-14040956f35d | 2020-12-10 09:10:08+00:00 | ‘Mimikatz’ hacktool was detected | ‘Mimikatz’ hacktool was detected | Low | Readily available tools, such as hacking programs, can be used by unauthorized individuals to sp… | MDATP | Microsoft | da637426874826014018_-1390662053 | edb68e6d-012d-4c6b-7408-20e679fb41c8 | WindowsDefenderAv | NaN | False | 2020-12-04 14:00:01+00:00 | 2020-12-04 14:00:01+00:00 | 2020-12-10 09:10:08+00:00 | [rn “1. Make sure the machine is completely updated and all your software has the latest patc… | {rn “MicrosoftDefenderAtp.Category”: “Malware”,rn “MicrosoftDefenderAtp.InvestigationId”: … | [rn {rn “$id”: “4”,rn “DnsDomain”: “na.contosohotels.com”,rn “HostName”: “vict… | Detection | Microsoft Defender Advanced Threat Protection | https://securitycenter.microsoft.com/alert/da637426874826014018_-1390662053 | New | victim00.na.contosohotels.com | Unknown | SecurityAlert | victim00 | victim00 | True | False | False | |||||||||
2 | 8ecf8077-cf51-4820-aadd-14040956f35d | 2020-12-10 09:10:08+00:00 | Malicious credential theft tool execution detected | Malicious credential theft tool execution detected | High | A known credential theft tool execution command line was detected.nEither the process itself or… | MDATP | Microsoft | da637426874824572229_-192666782 | 39912e77-045b-a082-a91e-8a18958d1b1c | WindowsDefenderAtp | NaN | False | 2020-12-04 14:00:00+00:00 | 2020-12-04 14:00:00+00:00 | 2020-12-10 09:10:08+00:00 | [rn “1. Make sure the machine is completely updated and all your software has the latest patc… | {rn “MicrosoftDefenderAtp.Category”: “CredentialAccess”,rn “MicrosoftDefenderAtp.Investiga… | [rn {rn “$id”: “4”,rn “DnsDomain”: “na.contosohotels.com”,rn “HostName”: “vict… | Detection | Microsoft Defender Advanced Threat Protection | https://securitycenter.microsoft.com/alert/da637426874824572229_-192666782 | New | victim00.na.contosohotels.com | CredentialAccess | SecurityAlert | victim00 | victim00 | True | False | False |
Shown below is a preview of a notebook tool that lets you browser around entities and their pivot functions, search for a function by keyword and view the help for that function. This is going to be released shortly.
>>> Pivot.browse()
Standardized way of calling Pivot functions
Due to various factors (historical, underlying data, developer laziness and forgetfulness, etc.) the functionality in MSTICPy can be inconsistent in the way it uses input parameters.
Also, many functions will only accept inputs as a single value, or a list or a DataFrame or some unpredictable combination of these.
Pivot functions allow you to largely forget about this – you can use the same function whether you have:
- a single value
- a list of values (or any Python iterable, such as a tuple or even a generator function)
- a DataFrame with the input value in one of the columns.
Let’s take an example.
Suppose we have a set of IP addresses pasted from somewhere that we want to use as input.
We need to convert this into a Python data object of some sort.
To do this we can use another Pivot utility %%txt2df. This is a Jupyter/IPython magic function – to use it, just paste you data in a cell that you want to import into an empty. Use
%%txt2df –help
in an empty cell to see the full syntax.
In the example below, we specify a comma separator, that the data has a headers row and to save the converted data as a DataFrame named “ip_df”.
Warning if you specify the “–name” parameter, this will overwrite any existing variable of this name.
%%txt2df –sep , –headers –name ip_df
idx, ip, type
0, 172.217.15.99, Public
1, 40.85.232.64, Public
2, 20.38.98.100, Public
3, 23.96.64.84, Public
4, 65.55.44.108, Public
5, 131.107.147.209, Public
6, 10.0.3.4, Private
7, 10.0.3.5, Private
8, 13.82.152.48, Public
idx | ip | type | |
0 | 0 | 172.217.15.99 | Public |
1 | 1 | 40.85.232.64 | Public |
2 | 2 | 20.38.98.100 | Public |
3 | 3 | 23.96.64.84 | Public |
4 | 4 | 65.55.44.108 | Public |
5 | 5 | 131.107.147.209 | Public |
6 | 6 | 10.0.3.4 | Private |
7 | 7 | 10.0.3.5 | Private |
8 | 8 | 13.82.152.48 | Public |
For demonstration purposes, we’ll also create a standard Python list from the “ip” column of the DataFrame.
>>> ip_list = list(ip_df.ip)
>>> print(ip_list)
[‘172.217.15.99’, ‘40.85.232.64’, ‘20.38.98.100’, ‘23.96.64.84’, ‘65.55.44.108’, ‘131.107.147.209’, ‘10.0.3.4’, ‘10.0.3.5’, ‘13.82.152.48’]
How did this work before?
If you recall the earlier example of get_ip_type, passing it a list or DataFrame doesn’t result in anything useful.
>>> get_ip_type(ip_list)
[‘172.217.15.99’, ‘40.85.232.64’, ‘20.38.98.100’, ‘23.96.64.84’, ‘65.55.44.108’, ‘131.107.147.209’, ‘10.0.3.4’, ‘10.0.3.5’, ‘13.82.152.48’]
does not appear to be an IPv4 or IPv6 address
‘Unspecified’
Pivot versions are (somewhat) agnostic to input data format
However, the “pivotized” version can accept and correctly process a list.
>>> IpAddress.util.ip_type(ip_list)ip | result | |
0 | 172.217.15.99 | Public |
1 | 40.85.232.64 | Public |
2 | 20.38.98.100 | Public |
3 | 23.96.64.84 | Public |
4 | 65.55.44.108 | Public |
5 | 131.107.147.209 | Public |
6 | 10.0.3.4 | Private |
7 | 10.0.3.5 | Private |
8 | 13.82.152.48 | Public |
In the case of a DataFrame, we have to tell the function the name of the column that contains the input data.
>>> IpAddress.util.whois(ip_df) # won’t work!
—————————————————————————
KeyError Traceback (most recent call last)
<ipython-input-32-debf57d805c7> in <module>
…
173 input_df, input_column, param_dict = _create_input_df(
–> 174 input_value, pivot_reg, parent_kwargs=kwargs
175 )
…
KeyError: (“‘ip_column’ is not in the input dataframe”,
‘Please specify the column when calling the function.
You can use one of the parameter names for this:’, [‘column’, ‘input_column’, ‘input_col’, ‘src_column’, ‘src_col’])
>>> entities.IpAddress.util.whois(ip_df, column=”ip”) # correctnir | asn_registry | asn | asn_cidr | asn_country_code | asn_date | asn_description | query | nets |
NaN | arin | 15169 | 172.217.15.0/24 | US | 2012-04-16 | GOOGLE, US | 172.217.15.99 | [{‘cidr’: ‘172.217.0.0/16’, ‘name’: ‘GOOGLE’, ‘handle’: ‘NET-172-217-0-0-1’, ‘range’: ‘172.217.0… |
NaN | arin | 8075 | 40.80.0.0/12 | US | 2015-02-23 | MICROSOFT-CORP-MSN-AS-BLOCK, US | 40.85.232.64 | [{‘cidr’: ‘40.80.0.0/12, 40.124.0.0/16, 40.125.0.0/17, 40.74.0.0/15, 40.120.0.0/14, 40.76.0.0/14… |
NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Note: for most functions you can ignore the parameter name and just specify it as a positional parameter. You can also use the original parameter name of the underlying function or the placeholder name “value”.
The following are all equivalent:
>>> IpAddress.util.ip_type(ip_list)
>>> IpAddress.util.ip_type(ip_str=ip_list)
>>> IpAddress.util.ip_type(value=ip_list)
>>> IpAddress.util.ip_type(data=ip_list)
When passing both a DataFrame and column name use:
>>> IpAddress.util.ip_type(data=ip_df, column=“col_name”)You can also pass an entity instance of an entity as a input parameter. The pivot code knows which attribute or attributes of an entity will provider the input value.
>>> ip_entity = IpAddress(Address=”40.85.232.64″)
>>> IpAddress.util.ip_type(ip_entity)
ip | result | |
0 | 40.85.232.64 | Public |
Iterable/DataFrame inputs and single-value functions
Many of the underlying functions only accept single values as inputs. Examples of these are the data query functions – typically they expect a single host name, IP address, etc.
Pivot knows about the type of parameters that the function accepts. It will adjust the input to match the expectations of the underlying function. If a list or DataFrame is passed as input to a single-value function Pivot will split the input and call the function once for each value. It then combines the output into a single DataFrame before returning the results.
You can read a bit more about how this is done in the Appendix – “how do pivot wrappers work?”
Data queries – where does the time range come from?
The Pivot class has a built-in time range, which is used by default for all queries. Don’t worry – you can change it easily.
To see the current time setting:
>>> Pivot.current.timespan
TimeStamp(start=2021-02-15 21:01:40.381864, end=2021-02-16 21:01:40.381864, period=-1 day, 0:00:00)
Note: “Pivot.current” gives you access to the last created instance of the Pivot class – if you’ve created multiple instances of Pivot (which you rarely need to do), you can always get to the last one you created using this class attribute.
You can edit the time range interactively
Pivot.current.edit_query_time()
Or by setting the timespan property directly.
>>> from msticpy.common.timespan import TimeSpan
>>> # TimeSpan accepts datetimes or datestrings
>>> timespan = TimeSpan(start=”02/01/2021″, end=”02/15/2021″)
>>> Pivot.current.timespan = timespan
TimeStamp(start=2021-02-01 00:00:00, end=2021-02-15 00:00:00, period=-14 days +00:00:00)
In an upcoming release there is also a convenience function for setting the time directly with Python datetimes or date strings.
Pivot.current.set_timespan(start=”2020-02-06 03:00:00″, end=”2021-02-15 01:42:42″)
You can also override the built-in time settings by specifying start and end as parameters to the query function.
Host.AzureSentinel.SecurityAlert_list_related_alerts(host_name=”victim00″, start=dt1, end=dt2)
Supplying extra parameters
The Pivot layer will pass any unused keyword parameters to the underlying function. This does not usually apply to positional parameters – if you want parameters to get to the function, you have to name them explicitly. In this example the add_query_items parameter is passed to the underlying query function
>>> entities.Host.AzureSentinel.SecurityEvent_list_host_logons(
host_name=”victimPc”,
add_query_items=”| summarize count() by LogonType”
)
LogonType | count_ | |
0 | 5 | 27492 |
1 | 4 | 12597 |
2 | 3 | 6936 |
3 | 2 | 173 |
4 | 10 | 58 |
5 | 9 | 8 |
6 | 0 | 19 |
7 | 11 | 1 |
Pivot Pipelines
Because all pivot functions accept DataFrames as input and produce DataFrames as output, it means that it is possible to chain pivot functions into a pipeline.
Joining input to output
You can join the input to the output. This usually only makes sense when the input is a DataFrame. It lets you keep the previously accumulated results and tag on the additional columns produced by the pivot function you are calling.
The join parameter supports “inner”, “left”, “right” and “outer” joins (be careful with the latter though!) See pivot joins documentation for more details.
Although joining is useful in pipelines you can use it on any function whether in a pipeline or not. In this example you can see that the idx, ip and type columns have been carried over from the source DataFrame and joined with the output.
>>> entities.IpAddress.util.whois(ip_df, column=”ip”, join=”inner”)idx | ip | type | nir | asn_registry | asn | asn_cidr | asn_country_code | asn_date | asn_description | query | nets |
0 | 172.217.15.99 | Public | NaN | arin | 15169 | 172.217.15.0/24 | US | 2012-04-16 | GOOGLE, US | 172.217.15.99 | [{‘cidr’: ‘172.217.0.0/16’, ‘name’: ‘GOOGLE’, ‘handle’: ‘NET-172-217-0-0-1’, ‘range’: ‘172.217.0… |
1 | 40.85.232.64 | Public | NaN | arin | 8075 | 40.80.0.0/12 | US | 2015-02-23 | MICROSOFT-CORP-MSN-AS-BLOCK, US | 40.85.232.64 | [{‘cidr’: ‘40.80.0.0/12, 40.124.0.0/16, 40.125.0.0/17, 40.74.0.0/15, 40.120.0.0/14, 40.76.0.0/14… |
2 | 20.38.98.100 | Public | NaN | arin | 8075 | 20.36.0.0/14 | US | 2017-10-18 | MICROSOFT-CORP-MSN-AS-BLOCK, US | 20.38.98.100 | [{‘cidr’: ‘20.64.0.0/10, 20.40.0.0/13, 20.34.0.0/15, 20.128.0.0/16, 20.36.0.0/14, 20.48.0.0/12, … |
Pipelines
Pivot pipelines are implemented pandas customr accessors. Read more about Extending pandas here.
When you load Pivot it adds the mp_pivot pandas DataFrame accessor. This appears as an attribute to DataFrames.
>>> ips_df.mp_pivot
<msticpy.datamodel.pivot_pd_accessor.PivotAccessor at 0x275754e2208>
The main pipelining function run is a method of mp_pivot. run requires two parameters
- the pivot function to run and
- the column to use as input.
See mp_pivot.run documentation for more details.
Here is an example of using it to call four pivot functions, each using the output of the previous function as input and using the join parameter to accumulate the results from each stage.
1. (
2. ips_df
3. .mp_pivot.run(IpAddress.util.ip_type, column=”IP”, join=”inner”)
4. .query(“result == ‘Public'”).head(10)
5. .mp_pivot.run(IpAddress.util.whois, column=”ip”, join=”left”)
6. .mp_pivot.run(IpAddress.util.geoloc_mm, column=”ip”, join=”left”)
7. .mp_pivot.run(IpAddress.AzureSentinel.SecurityAlert_list_alerts_for_ip, source_ip_list=”ip”, join=”left”)
8. ).head(5)
Let’s step through it line by line.
- The whole thing is surrounded by a pair of parentheses – this is just to let us split the whole expression over multiple lines without Python complaining.
- Next we have ips_df – this is just the starting DataFrame, our input data.
- Next we call the mp_pivot.run() accessor method on this dataframe. We pass it the pivot function that we want to run (IpAddress.util.ip_type) and the input column name (IP). This column name is the column in ips_df where our input IP addresses are. We’ve also specified an join type of “inner”. In this case the join type doesn’t really matter since we know we get exactly one output row for every input row.
- We’re using the pandas query function to filter out unwanted entries from the previous stage. In this case we only want “Public” IP addresses. This illustrates that you can intersperse standard pandas functions in the same pipeline. We could have also added a column selector expression ([[“col1”, “col2″…]]), for example, if we wanted to filter the columns passed to the next stage
- We are calling a further pivot function – whois. Remember the “column” parameter always refers to the input column, i.e. the column from previous stage that we want to use in this stage.
- We are calling geoloc_mm to get geo location details joining with a “left” join – this preserves the input data rows and adds null columns in any cases where the pivot function returned no result.
- Is the same as 6 except the called function is a data query to see if we have any alerts that contain these IP addresses. Remember, in the case of data queries we have to name the specific query parameter that we want the input to go to. In this case, each row value in the ip column from the previous stage will be sent to the query.
- Finally we close the parentheses to form a valid Python expression. The whole expression returns a DataFrame so we can add further pandas operations here (like .head(5) shown here).
>>> (
ips_df
.mp_pivot.run(entities.IpAddress.util.ip_type, column=”IP”, join=”inner”)
.query(“result == ‘Public'”).head(10)
.mp_pivot.run(entities.IpAddress.util.whois, column=”ip”, join=”left”)
.mp_pivot.run(entities.IpAddress.util.geoloc_mm, column=”ip”, join=”left”)
.mp_pivot.run(entities.IpAddress.AzureSentinel.SecurityAlert_list_alerts_for_ip, source_ip_list=”ip”, join=”left”)
).head(5)
TenantId | TimeGenerated | AlertDisplayName | AlertName | Severity | Description | ProviderName | VendorName | VendorOriginalId | SystemAlertId | AlertType | ConfidenceLevel | |
0 | 8ecf8077-cf51-4820-aadd-14040956f35d | 2020-12-23 14:08:12+00:00 | Microsoft Threat Intelligence Analytics | Microsoft Threat Intelligence Analytics | Medium | Microsoft threat intelligence analytic has detected Blocked communication to a known WatchList d… | Threat Intelligence Alerts | Microsoft | 91d806d3-6b6f-4e5c-a78f-e674d602be51 | 625ff9af-dddc-0cf8-9d4b-e79067fa2e71 | ThreatIntelligence | 83 |
1 | 8ecf8077-cf51-4820-aadd-14040956f35d | 2020-12-23 14:08:12+00:00 | Microsoft Threat Intelligence Analytics | Microsoft Threat Intelligence Analytics | Medium | Microsoft threat intelligence analytic has detected Blocked communication to a known WatchList d… | Threat Intelligence Alerts | Microsoft | 173063c4-10dd-4dd2-9e4f-ec5ed596ec54 | c977f904-ab30-d57e-986f-9d6ebf72771b | ThreatIntelligence | 83 |
2 | 8ecf8077-cf51-4820-aadd-14040956f35d | 2020-12-23 14:08:12+00:00 | Microsoft Threat Intelligence Analytics | Microsoft Threat Intelligence Analytics | Medium | Microsoft threat intelligence analytic has detected Blocked communication to a known WatchList d… | Threat Intelligence Alerts | Microsoft | 58b2cda2-11c6-42b8-b6f1-72751cad8f38 | 9ee547e4-cba1-47d1-e1f9-87247b693a52 | ThreatIntelligence | 83 |
Other pipeline functions
In addition to run, the mp_pivot accessor also has the following functions:
- display – this simply displays the data at the point called in the pipeline. You can add an optional title, filtering and the number or rows to display
- tee – this forks a copy of the DataFrame at the point it is called in the pipeline. It will assign the forked copy to the name given in the var_name parameter. If there is an existing variable of the same name it will not overwrite it unless you add the clobber=True parameter.
In both cases the pipelined data is passed through unchanged.
See Pivot functions help for more details.
Use of these is shown below in this partial pipeline.
…
.mp_pivot.run(IpAddress.util.geoloc_mm, column=”ip”, join=”left”)
.mp_pivot.display(title=”Geo Lookup”, cols=[“IP”, “City”]) # << display an intermediate result
.mp_pivot.tee(var_name=”geoip_df”, clobber=True) # << save a copy called ‘geoip_df’
.mp_pivot.run(IpAddress.AzureSentinel.SecurityAlert_list_alerts_for_ip, source_ip_list=”ip”, join=”left”)
In the next release we’ve also implemented:
- tee_exec – this executes a function on a forked copy of the DataFrame The function must be a pandas function or custom accessor. A good example of the use of this might be creating a plot or summary table to display partway through the pipeline.
Extending Pivot – adding your own (or someone else’s) functions
You can add pivot functions of your own. You need to supply:
- the function
- some metadata that describes where the function can be found and how the function works
Full details of this are described here.
The current version of Pivot doesn’t let you add functions defined inline (i.e. written in the notebook itself) but this will be possible in the forthcoming release.
Let’s create a function in a Python module my_module.py. We can do this using the %%write_file magic function and running the cell.
%%writefile my_module.py
“””Upper-case and hash”””
from hashlib import md5
def my_func(input: str):
md5_hash = “-“.join(hex(b)[2:] for b in md5(input.encode(“utf-8”)).digest())
return {
“Title”: input.upper(),
“Hash”: md5_hash
}
We also need to create a YAML definition file for our pivot function. Again we can use %%write_file to create a local file in the current directory. We need to tell Pivot
- the name of the function and source module,
- the name of the container that the function will appear in,
- the input type expected by the function (“value”, “list” or “dataframe”)
- which entities to add the pivot to, along with a corresponding attribute of the entity. (The attribute is used in cases where you are passing an instance of an entity itself as an input parameter – if in doubt just use any valid attribute of the entity).
- The name of the input attribute of the underlying function.
- An (optional) new name to give the function.
%%writefile my_func.yml
pivot_providers:
my_func_defn:
src_func_name: my_func
src_module: my_module
entity_container_name: cyber
input_type: value
entity_map:
Host: HostName
func_input_value_arg: input
func_new_name: upper_hash_name
Now we can register the function we created as a pivot function.
>>> from msticpy.datamodel.pivot_register_reader import register_pivots
>>> register_pivots(“my_func.yml”)
An then run it.
>>> Host.cyber.upper_hash_name(“host_name”)
Title | Hash | input | |
0 | HOST_NAME | 5d-41-40-2a-bc-4b-2a-76-b9-71-9d-91-10-17-c5-92 | host_name |
In the next release, this will be available as a simple function that can be used to add a function defined in the notebook as shown here.
from hashlib import md5
def my_func2(input: str):
md5_hash = “-“.join(hex(b)[2:] for b in md5(input.encode(“utf-8”)).digest())
return {
“Title”: input.upper(),
“Hash”: md5_hash
}
Pivot.add_pivot_function(
func=my_func2,
container=”cyber”, # which container it will appear in on the entity
input_type=”value”,
entity_map={“Host”: “HostName”},
func_input_value_arg=”input”,
func_new_name=”il_upper_hash_name”,
)
Host.cyber.il_upper_hash_name(“host_name”)
Title | Hash | input | |
0 | HOST_NAME | 5d-41-40-2a-bc-4b-2a-76-b9-71-9d-91-10-17-c5-92 | host_name |
Conclusion
We’ve taken a short tour through the MSTICPy Pivot functions, looking at how they make the functionality in MSTICPy easier to discover and use.
I’m particularly excited about the pipeline functionality. In the next release we’re going to make it possible to define reusable pipelines in configuration files and execute them with a single function call. This should help streamline some common patterns in notebooks for Cyber hunting and investigation.
Please send any feedback or suggestions for improvements to msticpy@microsoft.com or create an issue on https://github.com/microsoft/msticpy.
Happy hunting!
Appendix – how do pivot wrappers work?
In Python you can create functions that return other functions. This is called wrapping the function.
It allows the outer function to do additional things to the input parameters and the return value of the inner function.
Take this simple function that just applies proper capitalization to an input string.
def print_me(arg):
print(arg.capitalize())
print_me(“hello”)
Hello
If we try to pass a list to this function we get an expected exception since the function only knows how to process a string
print_me([“hello”, “world”])
—————————————————————————
AttributeError Traceback (most recent call last)
<ipython-input-36-94b3e61eb86f> in <module>
…
AttributeError: ‘list’ object has no attribute ‘capitalize’
We could create a wrapper function that checked the input and iterated over the individual items if arg is a list. The works but we don’t want to have to do this for every function that we want to have flexible input!
def print_me_list(arg):
if isinstance(arg, list):
for item in arg:
print_me(item)
else:
print_me(arg)
print_me_list(“hello”)
print_me_list([“how”, “are”, “you”, “?”])
Hello
How
Are
You
?
Instead, we can create a function wrapper.
In the example below, the outer function dont_care_func defines an inner function – list_or_str – and then returns this function. The inner function list_or_str is what implements the same “is-this-a-string-or-list” logic that we saw in the previous example. Crucially though, it isn’t hard-coded to call print_me but calls whatever function is passed (the func parameter) to it from the outer function dont_care_func.
# Our magic wrapper
def dont_care_func(func):
def list_or_str(arg):
if isinstance(arg, list):
for item in arg:
func(item)
else:
func(arg)
return list_or_str
How do we use this?
We simply pass the function that we want to wrap to dont_care_func. Recall, that this function just returns an instance of the inner function. In this case the value func will have been replaced by the actual function print_me.
print_stuff = dont_care_func(print_me)
Now we have a wrapped version of print_me that can handle different types of input. Magic!
print_stuff(“hello”)
print_stuff([“how”, “are”, “you”, “?”])
Hello
How
Are
You
?
We can also define further functions and create wrapped versions of those by passing them to dont_care_func.
def shout_me(arg):
print(arg.upper(), “U0001F92C!”, end=” “)
shout_stuff = dont_care_func(shout_me)
shout_stuff(“hello”)
shout_stuff([“how”, “are”, “you”, “?”])
HELLO ?! HOW ?! ARE ?! YOU ?! ? ?!
The wrapper functionality in Pivot is a bit more complex than this but essentially operates this way.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments