This article is contributed. See the original author and article here.
Kafka Connect
In a normal Kafka cluster a producer application produces a message and publishes it to Kafka and a consumer application consumes the message from Kafka.
In these circumstances it is the application developer’s responsibility to ensure that the producer and consumers are reliable and fault tolerant.
Kafka Connect is a framework for connecting Kafka with external systems such as databases, storage systems, applications , search indexes, and file systems, using so-called Connectors, in a reliable and fault tolerant way.
Kafka Connectors are ready-to-use components, which can help import data from external systems into Kafka topics and export data from Kafka topics into external systems. Existing connector implementations are normally available for common data sources and sinks with the option of creating ones own connector.
A source connector collects data from a system. Source systems can be entire databases, applications or message brokers. A source connector could also collect metrics from application servers into Kafka topics, making the data available for stream processing with low latency.
A sink connector delivers data from Kafka topics into other systems, which might be indexes such as Elasticsearch, storage systems such as Azure Blob storage, or databases.
**Most connectors are maintained by the community, while others are supported by Confluent or its partners at Confluent Connector Hub. One can normally find connectors for most popular systems like Azure Blob ,Azure Data Lake Store, Elastic Search etc.
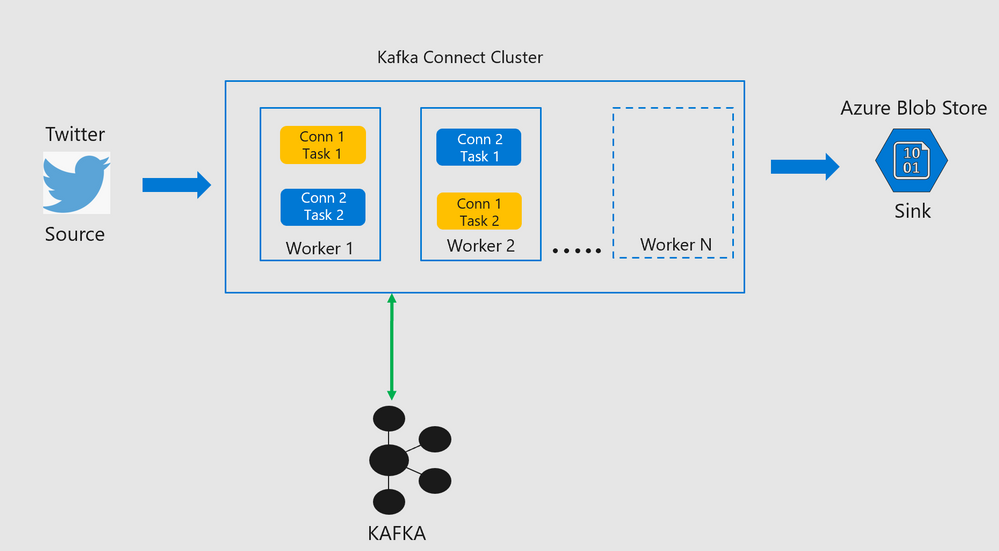
Every connector spawns tasks which are then distributed across workers in the Kafka Connect cluster.
Kafka Connect Architecture


Lab Objectives
- This lab explores ways to use Kafka Connect on an HDInsight Managed Kafka Cluster in both Standalone Mode and Distributed Mode.The connect cluster in both the setups would ingest messages from twitter and write them to an Azure Storage Blob.
Standalone Mode
- A single edge node on an HDInsight cluster will be used to demonstrate Kafka Connect in standalone mode.
Distributed Mode
-
Two edge nodes on an HDInsight cluster will be used to demonstrate Kafka Connect in distributed mode.
-
Scalability is achieved in Kafka Connect with the addition of more edges nodes to the HDInsight cluster either at the time of creation or post creation.
-
Since the number of edge nodes can be scaled up or down on an existing cluster , this functionality can be used to scale the size of the Kafka Connect cluster as well.
Deploy a HDInsight Managed Kafka with Kafka connect standalone
In this section we would deploy an HDInsight Managed Kafka cluster with two edge nodes inside a Virtual Network and then enable Kafka Connect in standalone mode on one of those edge nodes.
- Click on the Deploy to Azure Button to start the deployment process
-
On the Custom deployment template populate the fields as described below. Leave the rest of their fields at their default entries
- Resource Group : Choose a previously created resource group from the dropdown
- Location : Automatically populated based on the Resource Group location
- Cluster Name : Enter a cluster name( or one is created by default)
- Cluster Login Name: Create a administrator name for the Kafka Cluster( example : admin)
- Cluster Login Password: Create a administrator login password for the username chosen above
- SSH User Name: Create an SSH username for the cluster
- SSH Password: Create an SSH password for the username chosen above
-
Check he box titled “I agree to the terms and conditions stated above” and click on Purchase.
-
Wait till the deployment completes and you get the Your Deployment is Complete message and then click on Go to resource.


- On the Resource group explore the various components created as part of the Deployment . Click on the HDInsight Cluster to open the cluster page.

- On the HDInsight cluster page click on the SSH+Cluster login blade on the left and get the hostname of the edge node that was deployed.


- Using an SSH client of your choice ssh into the edge node using the sshuser and password that you set in the custom ARM script.
Note: In this the Kafka Connect standalone mode you will need to make config changes on a single edge node.

- In the next sections we would configure the Kafka Connect standalone on a single edge node.
Configure Kafka Connect in Standalone Mode
Acquire the Zookeeper and Kafka broker data
- Set up password variable. Replace
PASSWORDwith the cluster login password, then enter the command
export password='PASSWORD'
- Extract the correctly cased cluster name
export clusterName=$(curl -u admin:$password -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')
- Extract the Kafka Zookeeper hosts
export KAFKAZKHOSTS=$(curl -sS -u admin:$password -G https://$clusterName.azurehdinsight.net/api/v1/clusters/$clusterName/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);
- Validate the content of the
KAFKAZKHOSTSvariable
echo $KAFKAZKHOSTS
- Zookeeper values appear in the below format . Make a note of these values as they will be used later
zk1-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181,zk2-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181
- To extract Kafka Broker information into the variable KAFKABROKERS use the below command
export KAFKABROKERS=$(curl -sS -u admin:$password -G https://$clusterName.azurehdinsight.net/api/v1/clusters/$clusterName/services/KAFKA/components/KAFKA_BROKER | jq -r '["(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);
- Check to see if the Kafka Broker information is available
echo $KAFKABROKERS
- Kafka Broker host information appears in the below format
wn1-kafka.eahjefyeyyeyeyygqj5y1ud.cx.internal.cloudapp.net:9092,wn0-kafka.eaeyhdseyy1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Configure Kafka Connect in standalone mode
-
To run Kafka Connect in standalone mode one needs to look at two important files.
-
connect-standalone.properties: Located at /usr/hdp/current/kafka-broker/bin -
connect-standalone.sh: Located at /usr/hdp/current/kafka-broker/bin
Note : The reason we create two copies of the connect-standalone. properties file below is to separate the rest.port property to different ports. If you do not do this , you will run into a rest.port conflict when you try creating the connectors.
- Copy the
connect-standalone.propertiestoconnect-standalone.properties-1and populate the properties as shows below.
sudo cp /usr/hdp/current/kafka-broker/config/connect-standalone.properties /usr/hdp/current/kafka-broker/config/connect-standalone-1.properties
bootstrap.servers=<Enter the full contents of $KAFKABROKERS>
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets1
offset.flush.interval.ms=10000
rest.port=8084
plugin.path=/usr/hdp/current/kafka-broker/connectors/jcustenborder-kafka-connect-twitter-0.3.33,/usr/hdp/current/kafka-broker/connectors/confluentinc-kafka-connect-azure-blob-storage-1.3.2
- Copy the
connect-standalone.propertiesto “connect-standalone.properties-2` and edit the properties as below( Note the changed rest.port )
sudo cp /usr/hdp/current/kafka-broker/config/connect-standalone.properties /usr/hdp/current/kafka-broker/config/connect-standalone-2.properties
bootstrap.servers=<Enter the full contents of $KAFKAZKHOSTS>
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets1
offset.flush.interval.ms=10000
rest.port=8085
plugin.path=/usr/hdp/current/kafka-broker/connectors/jcustenborder-kafka-connect-twitter-0.3.33,/usr/hdp/current/kafka-broker/connectors/confluentinc-kafka-connect-azure-blob-storage-1.3.2
Deploy the Kafka Connect Plugins
-
Download the relevant Kafka Plugins from the Confluent Hub to your local desktop
-
Unzip the files to create the folder structures

- Create a new folder path on the edge node and set its properties
sudo mkdir /usr/hdp/current/kafka-broker/connectors
sudo chmod 777 /usr/hdp/current/kafka-broker/connectors
-
Using WINSCP or any other SCP tool of your choice upload the Kafka Connect plugins into the folder path
/usr/hdp/current/kafka-broker/connectors


Configure Kafka Connect plugin for streaming data from Twitter to Kafka
Create a Twitter App and get the credentials
- Go to https://dev.twitter.com/apps/new and log in, if necessary
- Enter your Application Name, Description and your website address. You can leave the callback URL empty.
- Accept the TOS, and solve the CAPTCHA.
- Submit the form by clicking the Create your Twitter Application
- Copy the below information from the screen for later use in your properties file.
twitter.oauth.consumerKey
twitter.oauth.consumerSecret
twitter.oauth.accessToken
twitter.oauth.accessTokenSecret

Update the Kafka Connect plugin for Twitter properties file
- Navigate to the folder path
/usr/hdp/current/kafka-broker/connectorsand create a new properties file calledtwitter.properties
cd /usr/hdp/current/kafka-broker/connectors/
sudo vi twitter.properties
- Insert the below Twitter Connect plugin properties into the properties file.
"name": "Twitter-to-Kafka",
"connector.class": "com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector",
"tasks.max": 1,
"kafka.status.topic":"twitterstatus",
"kafka.delete.topic":"twitterdelete",
"topic": "twitter1",
"twitter.oauth.consumerKey":"<twitter.oauth.consumerKey>",
"twitter.oauth.consumerSecret":"<twitter.oauth.consumerSecret>",
"twitter.oauth.accessToken":"<twitter.oauth.accessToken>",
"twitter.oauth.accessTokenSecret":"<twitter.oauth.accessTokenSecret>",
"filter.keywords":"keyword1,keyword2 ,...",
"process.deletes":false
Configure Kafka Connect plugin for Azure Blob Storage Sink connector
-
Create a regular Azure Blob storage account and a container on Azure and note the storage access keys
-
Navigate to the folder path
/usr/hdp/current/kafka-broker/connectorsand create a new properties file calledblob.properties
cd /usr/hdp/current/kafka-broker/connectors/
sudo vi blob.properties
- Insert the below Azure Blob Storage Sink plugin properties into the properties file
name=Kafka-to-Blob
connector.class=io.confluent.connect.azure.blob.AzureBlobStorageSinkConnector
tasks.max=1
topics=twitterstatus
flush.size=3
azblob.account.name=<Azure Blob account Name>
azblob.account.key=<security key>
azblob.container.name=<container name>
format.class=io.confluent.connect.azure.blob.format.avro.AvroFormat
confluent.topic.bootstrap.servers=<Enter the full contents of $KAFKAZKHOSTS>
confluent.topic.replication.factor=3
-
In the next section we would use the command line to start separate connector instances for running Source Tasks and Sink Tasks.
Start source tasks and sink tasks
- From the edge node run each of the below in a separate session to create new connectors and start tasks.
Start Source connector
- In a new session start the source connector
sudo /usr/hdp/current/kafka-broker/bin/connect-standalone.sh /usr/hdp/current/kafka-broker/config/connect-standalone-1.properties /usr/hdp/current/kafka-broker/connectors/twitter.properties
- If the connector is created and tasks are started you will see the below notifications

- Message ingestion from Twitter will start immediately thereafter.

- One other to way to test if Twitter Messages with the keywords are indeed being ingested is to start a console consumer in a fresh session and start consuming messages from topic twitterstatus .In a new session , launch a console consumer. (Make sure $KAFKAZKHOSTS still holds values of Kafka brokers)
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKAZKHOSTS --topic twitterstatus
- If everything is working , you should see a stream of relevant Twitter Messages on the console with specified keywords.
Start Sink Connector
- In a new session start the sink connector
sudo /usr/hdp/current/kafka-broker/bin/connect-standalone.sh /usr/hdp/current/kafka-broker/config/connect-standalone-2.properties /usr/hdp/current/kafka-broker/connectors/blob.properties
- If the connector is created and tasks are started you will see the below notifications

- Messages from the Kafka Topic twitterstatus will be written to container on the Azure Blob Store

- Authenticate into your Azure portal and navigate to the storage account to validate if Twitter Messages are being sent to the specific container.


- This ends the section for Kafka Connect in standalone mode.
Deploy an HDInsight Managed Kafka cluster with a Kafka Connect cluster in distributed mode.
In this section we would deploy an HDInsight Managed Kafka cluster with two Edge Node inside a Virtual Network and then enable distributed Kafka Connect on both of those edge nodes.
- Click on the Deploy to Azure Button to start the deployment process
Deploy to Azure -
On the Custom deployment template populate the fields as described below. Leave the rest of their fields at their default entries
- Resource Group : Choose a previously created resource group from the dropdown
- Location : Automatically populated based on the Resource Group location
- Cluster Name : Enter a cluster name( or one is created by default)
- Cluster Login Name: Create a administrator name for the Kafka Cluster( example : admin)
- Cluster Login Password: Create a administrator login password for the username chosen above
- SSH User Name: Create an SSH username for the cluster
- SSH Password: Create an SSH password for the username chosen above
-
Check he box titled “I agree to the terms and conditions stated above” and click on Purchase.
- Wait till the deployment completes and you get the Your Deployment is Complete message and then click on Go to resource.
- On the Resource group explore the various components created as part of the Deployment . Click on the HDInsight Cluster to open the cluster page.
- Log into Ambari from the cluster page to get the Hostnames(FQDN) of the edge nodes . They should appear in the below format
ed10-ag4kac.ohdqdgkr0bpe3kjx3dteggje4c.gx.internal.cloudapp.net
ed12-ag4kac.ohdqdgkr0bpe3kjx3dteggje4c.gx.internal.cloudapp.net

- On the HDInsight cluster page click on the SSH+Cluster login blade on the left and get the hostname of the edge node that was deployed.
- Using an SSH client of your choice ssh into the edge node using the sshuser and password that you set in the custom ARM script. You will notice that you have logged into edge node
ed10
Note: In this lab you will need to make config changes in both the edge nodes ed10 and ed12 . To log into ed12 simply ssh into ed12 from ed10
sshuser@ed10-ag4kac:~$ ssh ed12-ag4kac.ohdqdgkr0bpe3kjx3dteggje4c.gx.internal.cloudapp.net
- In the next sections we would configure the Kafka Connect distributed on both the edge nodes.
Configure Kafka Connect in Distributed Mode
Acquire the Zookeeper and Kafka broker data
- Set up password variable. Replace
PASSWORDwith the cluster login password, then enter the command
export password='PASSWORD'
- Extract the correctly cased cluster name
export clusterName=$(curl -u admin:$password -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')
- Extract the Kafka Zookeeper hosts
export KAFKAZKHOSTS=$(curl -sS -u admin:$password -G https://$clusterName.azurehdinsight.net/api/v1/clusters/$clusterName/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);
- Validate the content of the
KAFKAZKHOSTSvariable
echo $KAFKAZKHOSTS
- Zookeeper values appear in the below format . Make a note of these values as they will be used later
zk1-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181,zk2-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181
- To extract Kafka Broker information into the variable KAFKABROKERS use the below command
export KAFKABROKERS=$(curl -sS -u admin:$password -G https://$clusterName.azurehdinsight.net/api/v1/clusters/$clusterName/services/KAFKA/components/KAFKA_BROKER | jq -r '["(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);
- Check to see if the Kafka Broker information is available
echo $KAFKABROKERS
- Kafka Broker host information appears in the below format
wn1-kafka.eahjefyeyyeyeyygqj5y1ud.cx.internal.cloudapp.net:9092,wn0-kafka.eaeyhdseyy1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Configure the nodes for Kafka Connect in Distributed mode
Create the topics you will need
- Create the Offset Storage topic with a name of your choice . Here we use agconnect-offsets
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic agconnect-offsets --zookeeper $KAFKAZKHOSTS
- Create the Config Storage topic with a name of your choice. Here we use agconnect-configs
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic agconnect-configs --zookeeper $KAFKAZKHOSTS
- Create the Status topic with a name of your choice. Here we use agconnect-status
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic agconnect-status --zookeeper $KAFKAZKHOSTS
- Create the Topic for storing Twitter Messages. Here we use twitterstatus
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic twitterstatus --zookeeper $KAFKAZKHOSTS
Deploy the Kafka Connect Plugins
-
Download the relevant Kafka Plugins from the Confluent Hub to your local desktop
-
Unzip the files to create the folder structures

-
Note: The below step needs to be repeated for both ed10 and ed12 edge nodes
- Create a new folder path on the edge node
sudo mkdir /usr/hdp/current/kafka-broker/connectors sudo chmod 777 /usr/hdp/current/kafka-broker/connectors -
Using WINSCP or any other SCP tool of your choice upload the Kafka Connect Plugins into folder path created in the last step


- Transfer the files to ed12 using the below command. Make sure that folders have the right permissions for this operation.
rsync -r /usr/hdp/current/kafka-broker/connectors/ sshuser@<edge-node12-FQDN>:/usr/hdp/current/kafka-broker/connectors/
Note: The below steps needs to be repeated for both ed10 and ed12 edge nodes
Configure Kafka Connect
-
To run Kafka Connect in distributed mode one needs to look at two important files.
-
connect-distributed.properties: Located at /usr/hdp/current/kafka-broker/bin/conf -
connect-distributed.sh: Located at /usr/hdp/current/kafka-broker/bin/ -
In distributed mode, the workers need to be able to discover each other and have shared storage for connector configuration and offset data. Below are some of important parameters we would need to configure.
group.id: ID that uniquely identifies the cluster these workers belong to. Make sure this value is not changed between the edge nodes.config.storage.topic: Topic to store the connector and task configuration state in.offset.storage.topic: Topic to store the connector offset state in.rest.port: Port where the REST interface listens for HTTP requests.plugin.path: Path for the Kafka Connect Plugins
-
Edit the
connect-distributed.propertiesfilesudo vi /usr/hdp/current/kafka-broker/conf/connect-distributed.properties -
In the
connect-distributed.propertiesfile, define the topics that will store the connector state, task configuration state, and connector offset state. Uncomment and modify the parameters inconnect-distributed.propertiesfile as shown below. Note that we use some of the topics we created earlier.
bootstrap.servers=<Enter the full contents of $KAFKABROKERS>
group.id=agconnect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=agconnect-offsets
offset.storage.replication.factor=3
offset.storage.partitions=25
config.storage.topic=agconnect-configs
config.storage.replication.factor=3
status.storage.topic=agconnect-status
status.storage.replication.factor=3
status.storage.partitions=5
offset.flush.interval.ms=10000
rest.port=8083
plugin.path=/usr/hdp/current/kafka-broker/connectors/jcustenborder-kafka-connect-twitter-0.3.33,/usr/hdp/current/kafka-broker/connectors/confluentinc-kafka-connect-azure-blob-storage-1.3.2
- Start Kafka Connect in distributed mode in the background on the Edge Node .
nohup sudo /usr/hdp/current/kafka-broker/bin/connect-distributed.sh /usr/hdp/current/kafka-broker/conf/connect-distributed.properties &
- Repeat the same steps on other edge node to start Kafka Connect in distributed mode
Note : A file nohup.out is created in the same folder from where it is executed. If you are interested in exploring the startup logs simply cat nohup.out
Kafka Connect REST API
Note : In distributed mode, the REST API is the primary interface to the Connect cluster. Requests can be made from any edge node and the REST API automatically forwards requests. By default REST API for Kafka Connect runs on port 8083 but is configurable in connector properties
- Use the below REST API calls from any edge node to verify of Kafka Connect is working as expected on both the nodes
curl -s http://<edge-node-FQDN>:8083/ |jq
curl -s http://<edge-node-FQDN>:8083/ |jq
- If Kafka Connect is working as expected each of the REST API calls will return an output like below
{
"version": "2.1.0.3.1.2.1-1",
"commit": "ded5eefdb4f63651",
"kafka_cluster_id": "W0HIh8naTgip7Taju7G7fg"
}

-
In this section we started Kafka Connect in distributed mode alongside an HDInsight cluster and verified it using the Kafka REST API.
-
In the next section we would use Kafka REST API’s to start separate connector instances for running Source Tasks and Sink Tasks.
Create connectors and start tasks
Create a Twitter App and get the credentials
- Go to https://dev.twitter.com/apps/new and log in, if necessary
- Enter your Application Name, Description and your website address. You can leave the callback URL empty.
- Accept the TOS, and solve the CAPTCHA.
- Submit the form by clicking the Create your Twitter Application
- Copy the below information from the screen for later use in your properties file.
twitter.oauth.consumerKey
twitter.oauth.consumerSecret
twitter.oauth.accessToken
twitter.oauth.accessTokenSecret

Source Task
- From any edge node run the below to create a new connector and start tasks. Note that the number of tasks can be increased as per the size of your cluster.
curl -X POST http://<edge-node-FQDN>:8083/connectors -H "Content-Type: application/json" -d @- <<BODY
{
"name": "Twitter-to-Kafka",
"config": {
"name": "Twitter-to-Kafka",
"connector.class": "com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector",
"tasks.max": 3,
"kafka.status.topic":"twitterstatus",
"kafka.delete.topic":"twitterdelete",
"twitter.oauth.consumerKey":"<twitter.oauth.consumerKey>",
"twitter.oauth.consumerSecret":"<twitter.oauth.consumerSecret>",
"twitter.oauth.accessToken":"<twitter.oauth.accessToken>",
"twitter.oauth.accessTokenSecret":"<twitter.oauth.accessTokenSecret>",
"filter.keywords":"<keyword>",
"process.deletes":false
}
}
BODY
- If the connector is created , you will see a notification like below.

- Use the Kafka REST API to check if the connector
Twitter-to-Kafkawas created
curl -X GET http://ed10-ag4kac.ohdqdgkr0bpe3kjx3dteggje4c.gx.internal.cloudapp.net:8083/connectors
["local-file-source","Twitter-to-Kafka"]

- One way to test if Twitter Messages with the keywords are being ingested is to start a console consumer in a different session and start consuming messages from the topic twitterstatus .
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKAZKHOSTS --topic twitterstatus
-
If everything is working , you should see a stream of relevant Twitter Messages on the console with specified keywords.
-
Try pausing the tasks in the connector , this should also pause the Twitter Stream on the console producer.
curl -X PUT http://<edge-node-FQDN>:8083/connectors/Twitter-to-Kafka/pause
- Try resuming the tasks in the connector , this should also resume the Twitter Stream on the console producer.
curl -X PUT http://<edge-node-FQDN>:8083/connectors/Twitter-to-Kafka/resume
Sink Task
-
Create a regular Azure Blob storage account and a container on Azure and note the storage access keys
-
From any edge node run the below to create a new connector and start tasks. Note that the number of tasks can be increased as per the size of your cluster.
curl -X POST http://<edge-node-FQDN>:8083/connectors -H "Content-Type: application/json" -d @- <<BODY
{
"name": "Kafka-to-Blob",
"config": {
"connector.class": "io.confluent.connect.azure.blob.AzureBlobStorageSinkConnector",
"tasks.max": 1,
"topics":"twitterstatus",
"flush.size":3,
"azblob.account.name":"<Storage-account-name>",
"azblob.account.key":"<Storage-accesss-key>",
"azblob.container.name":"<Container-name>",
"format.class":"io.confluent.connect.azure.blob.format.avro.AvroFormat",
"confluent.topic.bootstrap.servers":"Enter the full contents of $KAFKAZKHOSTS",
"confluent.topic.replication.factor":3
}
}
BODY
- If the connector is created , you will see a notification like below.

- Use the Kafka REST API to check if the connector
Kafka-to-Blobwas created. You should see both the source and sink connectors.
curl -X GET http://<edge-node-FQDN>:8083/connectors
["local-file-source","Twitter-to-Kafka","Kafka-to-Blob"]

Authenticate into your Azure portal and navigate to the storage account to validate if Twitter Messages are being sent to the specific container.
- In this section we saw how the source and sink connectors were created . In the next section , we will explore some Kafka REST API’s to control Kafka Connect.
Kafka REST APIs
Commonly used REST APIs for Kafka Connect
-
Below are some commonly used REST APIs for controlling KAFKA Connect
-
Status of distributed connect
curl -s http://<edge-node-FQDN>:8083/ |jq
- Get list of Connect
curl -X GET http://<edge-node-FQDN>:8083/connector-plugins | jq
- Get list of connectors in the cluster
curl -X GET http://<edge-node-FQDN>:8083/connectors
- Get Status of connector
curl -X GET http://<edge-node-FQDN>:8083/connectors/<connector-name>
- Get connector Tasks
curl -X GET http://<edge-node-FQDN>:8083/connectors/<connector-name>/tasks
- Restart a connector
curl -X POST http://<edge-node-FQDN>:8083/connectors/<connector-name>/restart
- Delete a connector
curl -X DELETE http://<edge-node-FQDN>:8083/connectors/<connector-name>/
- Pause a connector
curl -X PUT http://<edge-node-FQDN>:8083/connectors/<connector-name>/pause
- Resume a connector
curl -X PUT http://<edge-node-FQDN>:8083/connectors/<connector-name>/resume
- Refer Apache Kafka documentation to get exhaustive list of REST API functions
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments