This article is contributed. See the original author and article here.
Documentation says:
“SQL on-demand is serverless, hence there is no infrastructure to setup or clusters to maintain. A default endpoint for this service is provided within every Azure Synapse workspace, so you can start querying data as soon as the workspace is created. There is no charge for resources reserved, you are only being charged for the data scanned by queries you run, hence this model is a true pay-per-use model.
If you use Apache Spark for Azure Synapse in your data pipeline, for data preparation, cleansing or enrichment, you can query external Spark tables you’ve created in the process, directly from SQL on-demand.” https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/on-demand-workspace-overview
About Spark: https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-overview
“Apache Spark provides primitives for in-memory cluster computing. A Spark job can load and cache data into memory and query it repeatedly. In-memory computing is much faster than disk-based applications. Spark also integrates with multiple programming languages to let you manipulate distributed data sets like local collections. There’s no need to structure everything as map and reduce operations.”
Using Synapse I have the intention to provide Lab loading data into Spark table and querying from SQL OD.
This was an option for a customer that wanted to build some reports querying from SQL OD.
You need:
1) A Synapse Workspace ( SQL OD will be there after the workspace creation)
2)Add Spark to the workspace
You do not need:
1) SQL Pool.
Step by Step
Launch Synapse Studio and create a new notebook. Add the following code ( phyton):

%%pyspark
from pyspark.sql.functions import col, when
df = spark.read.load('abfss://<container>@<storageAccount>.dfs.core.windows.net/folder/file.snappy.parquet', format='parquet')
df.createOrReplaceTempView("pysparkdftemptable")
Add some magic by include another cell and running Scala on it:
%%spark
spark.sql("CREATE DATABASE IF NOT EXISTS SeverlessDB")
val scala_df = spark.sqlContext.sql ("select * from pysparkdftemptable")
scala_df.write.mode("overwrite").saveAsTable("SeverlessDB.Parquet_file")
Run.
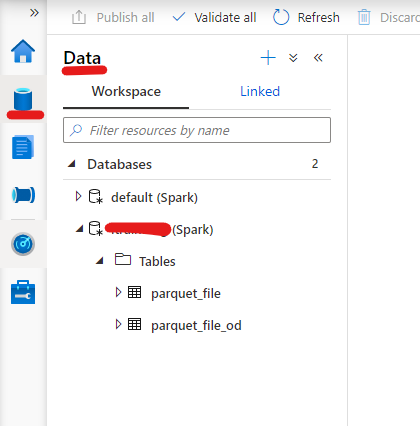
If everything ran successfully you should be able to see your new database and table under the Data Option:

Now it is the easy part. Query the table ( Right button -> New SQL Script -> Select):

Super quick and easy.
That is it!
Liliam C Leme
UK Engineer
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments