This article is contributed. See the original author and article here.
Introduction
In today’s data-driven world, the ability to act upon data as soon as its generated is crucial for businesses to make informed decisions quickly. Organizations seek to harness the power of up-to-the-minute data to drive their operations, marketing strategies, and customer interactions.
This becomes challenging in the world of real-time data where it is not always possible to do all the transformations while the data is being streamed. Therefore, you must come up with a flow that does not impact the data stream and is also quick.
This is where Microsoft Fabric comes into play. Fabric offers a comprehensive suite of services including Data Engineering, Data Factory, Data Science, Real-Time Intelligence, Data Warehouse, and Databases. But today, we are going to focus on Real-Time Intelligence.
Use-Cases
This set up can be used in scenarios where data transformation is needed to be used in downstream processing/analytical workload. As example of this would be to enable OneLake availability in KQL table and use that data to be accessed by other Fabric engines like Notebooks, Lakehouse etc. for training ML models/analytics.
Another example let’s say you have a timestamp column in your streaming data and you would like to change its format based on your standard. You can use the update policy to transform the timestamp data format and store it.
Overview
Fabric Real-Time Intelligence supports KQL database as its datastore which is designed to handle real-time data streams efficiently. After ingestion, you can use Kusto Query Language (KQL) to query the data in the database.
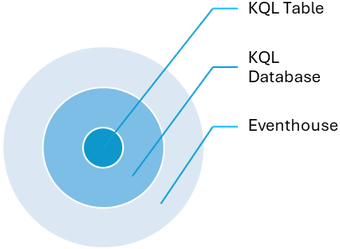
KQL Table is a Fabric item which is part of the KQL Database. Both these entities are housed within an Eventhouse. An Eventhouse is a workspace of databases, which might be shared across a certain project. It allows you to manage multiple databases at once, sharing capacity and resources to optimize performance and cost. Eventhouses provide unified monitoring and management across all databases and per database.
Figure 1: Hierarchy of Fabric items in an Eventhouse
Update policies are automated processes activated when new data is added to a table. They automatically transform the incoming data with a query and save the result in a destination table, removing the need for manual orchestration. A single table can have multiple update policies for various transformations, saving data to different tables simultaneously. These target tables can have distinct schemas, retention policies, and other configurations from the source table.
Scope
In this blog, we have a scenario where we will be doing data enrichment on the data that lands in the KQL table. In this case, we will be dropping the columns we don’t need but you can also do other transformations supported in KQL on the data.
Here we have a real-time stream pushing data to a KQL table. Once loaded into the source table, we will use an update policy which will drop columns not needed and push the data of interest to the destination table from the source table.

Prerequisites
- A Microsoft account or a Microsoft Entra user identity. An Azure subscription isn’t required.
- Fabric Capacity. If you don’t have one, you can sign-up for Fabric Trial Capacity.
- A KQL database in Real-Time Intelligence in Microsoft Fabric.
Creating sample data stream
- In the Real-Time Intelligence experience, create a new event stream.
- Under source, add new source and select sample data.
- Continue configuring the stream. I am using the Bicycles sample data stream in this blog.
- Select Direct ingestion as the Data Ingestion Mode for destination.
- Select your workspace and KQL database you have created as a prerequisite to this exercise for the destination.
- You should be seeing a pop-up to configure the database details and continue to configure the table where you need to land the data from the stream.

Configuring KQL Table with Update Policy
- Open the Eventhouse page in Fabric. There you should now be able to preview the data that is being ingested from the sample data stream.
Create a new destination table. I used the following KQL to create the new table (destination):
.create table RTITableNew ( BikepointID: string,Street: string, Neighbourhood: string, No_Bikes: int, No_Empty_Docks: int )- Under the Database tab, click on new and select Table Update Policy.
You can edit the existing policy format or paste the one below that I used:
NOTE: RTITable is source and RTITableNew is the destination table.
.alter table RTITable policy update ```[ { "IsEnabled": true, "Source": "RTITable", "Query": "RTITable | project BikepointID=BikepointID, Street=Street, Neighbourhood=Neighbourhood, No_Bikes=No_Bikes, No_Empty_Docks=No_Empty_Docks ", "IsTransactional": true, "PropagateIngestionProperties": false, "ManagedIdentity": null } ]```
The above policy drops the Longitude and Latitude columns and stores the rest of the columns in the destination table. You can do more transformations as per your requirements, but the workflow remains the same.- After running the above command, your destination table will start populating with the new data as soon as the source table gets data. To review the policy on the destination table, you can run the following command:
.show table policy update

Conclusion
To summarize, we took a real-time data stream, stored the data in a KQL database and then performed data enrichment on the data and stored in a destination table. This flow caters the scenarios where you want to perform processing on the data once its ingested from the stream.
Further Reading and Resources
Common scenarios for using table update policies – Kusto | Microsoft Learn
Create a table update policy in Real-Time Intelligence – Microsoft Fabric | Microsoft Learn
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments