This article is contributed. See the original author and article here.
AI today is about scale: models with billions of parameters used by millions of people. Azure Machine Learning is built to support your delivery of AI-powered experiences at scale. With our notebook-based authoring experience, our low-code and no-code training platform, our responsible AI integrations, and our industry-leading ML Ops capabilities, we give you the ability to develop large machine learning models easily, responsibly, and reliably.
One key component of employing AI in your business is model serving. Once you have trained a model and assessed it per responsible machine learning principles, you need to quickly process requests for predictions, for many users at a time. While serving models on general-purpose CPUs can work well for less complex models serving fewer users, those of you with a significant reliance on real-time AI predictions have been asking us how you can leverage GPUs to scale more effectively.
That is why today, we are partnering with NVIDIA to announce the availability of the Triton Inference Server in Azure Machine Learning to deliver cost-effective, turnkey GPU inferencing.
There are three components to serving an AI model at scale: server, runtime, and hardware. This new Triton server, together with ONNX Runtime and NVIDIA GPUs on Azure, complements Azure Machine Learning’s support for developing AI models at scale by giving you the ability to serve AI models to many users cheaply and with low latency. Below, we go into detail about each of the three components to serving AI models at scale.
Server
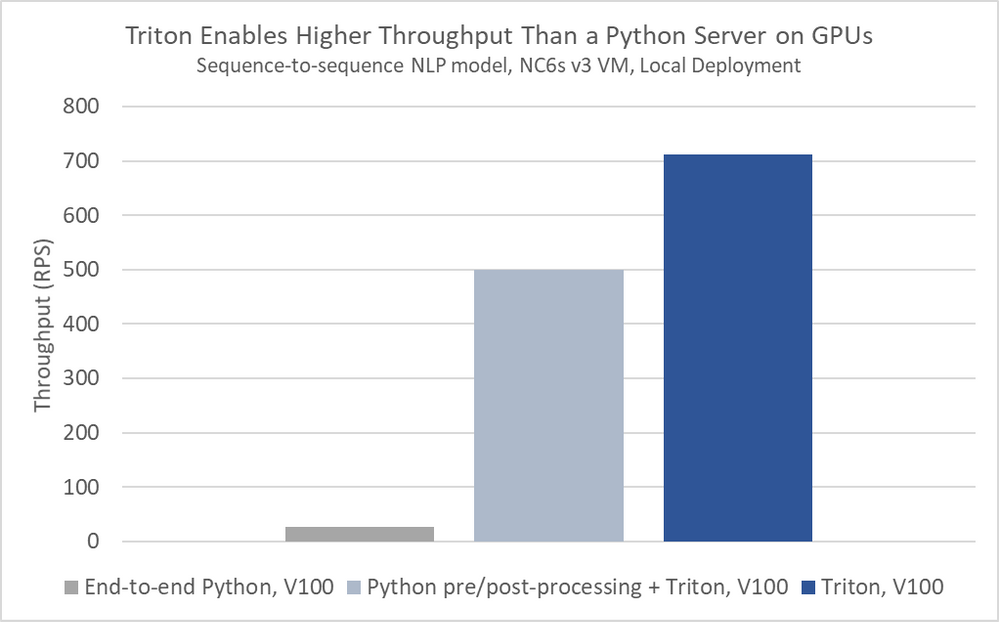
Triton Inference Server in Azure Machine Learning can, through server-side mini batching, achieve significantly higher throughput than can a general-purpose Python server like Flask.

Triton can support models in ONNX, PyTorch, TensorFlow, and Caffe2, giving your data scientists the freedom to explore any framework of interest to them during training time.
Runtime
For even better performance, serve your models in ONNX Runtime, a high-performance runtime for both training (in preview) and inferencing.

ONNX Runtime is used by default when serving ONNX models in Triton, and you can convert PyTorch, TensorFlow, and Scikit-learn models to ONNX.
Hardware
NVIDIA Tesla T4 GPUs in Azure provide a hardware-accelerated foundation for a wide variety of models and inferencing performance demands. The NC T4 v3 series is a new, lightweight GPU-accelerated VM, offering a cost-effective option for customers performing real-time or small batch inferencing who may not need the throughput afforded by larger GPU sizes such as the V100-powered ND v2 and NC v3-series VMs, and desire a wider regional deployment footprint.

The new NCasT4_v3 VMs are currently available for preview in the West US 2 region, with 1 to 4 NVIDIA Tesla T4 GPUs per VM, and will soon expand in availability with over a dozen planned regions across North America, Europe and Asia.
To learn more about NCasT4_v3-series virtual machines, visit the NCasT4_v3-series documentation.
Easy to Use
Using Triton Inference Server with ONNX Runtime in Azure Machine Learning is simple. Assuming you have a Triton Model Repository with a parent directory triton and an Azure Machine Learning deploymentconfig.json, run the commands below to register your model and deploy a webservice.
az ml model register -n triton_model -p triton --model-framework=Multi
az ml model deploy -n triton-webservice -m triton_model:1 --dc deploymentconfig.json --compute-target aks-gpu
Next Steps
In this blog, you have seen how Azure Machine Learning can enable your business to serve large AI models to many users simultaneously. By bringing together a high-performance inference server, a high-performance runtime, and high-performance hardware, we give you the ability to serve many requests per second at millisecond latencies while saving money.
To try this new offering yourself:
- Sign up for an Azure Machine Learning trial
- Clone our samples repository on GitHub
- Read our documentation
- Be sure to let us know what you think
You can also request access to the new NCasT4_v3 VM series (In Preview) by applying here.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments