by Scott Muniz | Jul 24, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
As discussed in my two previous posts, Azure Sentinel provides a variety of methods for importing threat intelligence directly into the ThreatIntelligenceIndicator Logs table where it can be used to power Analytics, Workbooks, Hunting, and other experiences.
However, Azure Sentinel also allows you to leverage massive repositories of external intelligence data as enrichment sources to enhance the triage and investigation experience of security incidents. Using the built-in automation capabilities of Azure Sentinel you can take any incident created through Azure Sentinel analytics rules, and retrieve additional context about the entities from third party sources, and make this context readily available to your security operations personnel to aid triage and investigation.
Today, we are announcing the availability of the RiskIQ Intelligence Connector for Azure Sentinel which allows you to tap into petabytes of external threat intelligence from RiskIQ’s Internet Intelligence Graph. Incidents can be enriched automatically using Azure Sentinel Playbooks, saving time and resources for your security responders. This blog will walk you through the setup, configuration, and show you how the rich context from the new RiskIQ Intelligence Connector playbooks is surfaced in Azure Sentinel security incidents.
Installation
Each RiskIQ enrichment playbook leverages one or more RiskIQ Security Intelligence Service APIs to provide up to the minute threat and contextual information. To learn more about the service and request a trial key, see the API documentation.
The set of RiskIQ Intelligence Connector playbooks are located in the Azure Sentinel GitHub repository.
In this blog we’ll use the Enrich-SentinelIncident-RiskIQ-IP-Passive-DNS playbook as an example.
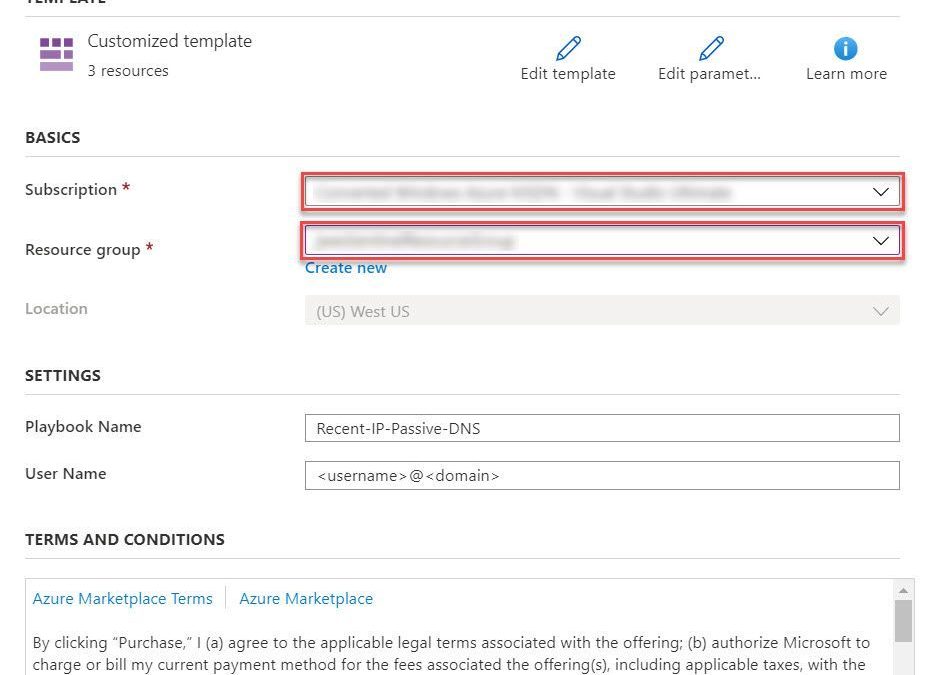
- Select the Deploy to Azure button on the playbook page in GitHub

- This will bring you to the Azure portal, Custom Deployment page. Input the Subscription and Resource Group values corresponding to your Azure Sentinel instance, and select the terms and conditions check box

- Select the Purchase button at the bottom of the page
- You will receive an Azure notification when the deployment has completed

Configuration
Once the playbook has been imported into your Azure Sentinel instance your will need to edit the playbook to configure the connections. Certain playbook actions require additional connection information to function, most commonly these are in the form of credentials for actions that require connecting to APIs. In this example, the playbook requires two connections, one for Azure Sentinel to read security alerts and the second for RiskIQ APIs to query for enrichment context for entities found in alerts.
- In the Azure portal, navigate to your Azure Sentinel workspace where you imported the playbook
- Select Playbooks from the Azure Sentinel navigation menu
- Select the Recent-IP-Passive-DNS playbook by selecting the playbook name
- Select Edit from the top menu of the playbook
- There are four steps in this playbook requiring you to configure connections

- Select a Connection from one of the steps requiring configuration and configure a new connection. For the connections to Azure Sentinel the user specified when establishing the connection must have sufficient permissions in the Azure Sentinel workspace to read the security alerts. For the RiskIQ connection, enter your RiskIQ API token and secret obtained from RiskIQ.
- Select Save from the top menu of the playbook to save the playbook
Use the RiskIQ playbook to enrich security incidents
Now that the Recent-IP-Passive-DNS playbook is installed and configured you can use it with the built-in Azure Sentinel automation framework in your analytics rules. Let’s take a look at how to associate this playbook with an analytic rule to enrich security incidents and give your security responders additional context for triage and investigation.
- Navigate to your Azure Sentinel Analytics page and select an existing analytics rule or template item you wish to add the playbook automation. Select Edit for an existing rule or Create rule for a new rule.
- The Recent-IP-Passive-DNS playbook works with analytics rules which map IP address entities so make sure you are working with such a rule. For simple testing of the playbook automation you can use rule logic as shown below to force an alert creation with a specific IP address.
AzureActivity
| take 1
| extend IPCustomEntity = "144.91.119.160"
- Navigate to the Automated response tab and place a check mark in the box for the Recent-IP-Passive-DNS playbook which will enable the playbook to run each time the analytic rule generates security alerts
- Select Save to finish and return to the Analytics page
The Recent-IP-Passive-DNS playbook queries the RiskIQ passive DNS database and retrieves any domains from the last 30 days associated with the IP address found in the security alert. It then adds this enrichment information to the resulting security incident so your security responders can easily access this additional context with triaging the incident. Let’s take a look at this experience for your security responders.
- Navigate to your Azure Sentinel Incidents page
- Locate the incident generated from the analytic rule configured to run the Recent-IP-Passive-DNS playbook automation and select Full details from the information pane
- Select the Comments tab to see the enrichment added by the Recent-IP-Passive-DNS playbook automation. You can also view the information in the RiskIQ portal by following the link provided at the bottom of the comment

Summary
In this post you learned how to obtain, configure, and associate the RiskIQ Intelligence Connector playbooks with analytics rules to enrich security incidents with additional context. Azure Sentinel, when combined with RiskIQ, has the potential to reshape how security teams operate, seamlessly integrating the most comprehensive external visibility with the advanced threat detection, AI, and orchestration found in Azure Sentinel.
by Scott Muniz | Jul 24, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Hi, all! Rod Trent here. I am a Cybersecurity CE/Consultant at Microsoft and work with Azure Sentinel literally every waking hour, so I see and hear a lot of unique and interesting things in relation to this fantastic product. I also blog for our Secure Infrastructure Blog and have quite a few Azure Sentinel articles posted there already.
Did you know that the Log Analytics agent requires an Internet connection no matter if it’s installed on an on-premises system or as an extension on a virtual machine stored in Azure? It may seem a bit quirky, but it’s true. Yes, even though an Azure VM has been spun up in the same cloud that the Log Analytics Workspace resides in, the agent still checks to see if there’s a valid Internet connection – well, actually it checks for a specific port (443) to be accessible, but the return error message is that an Internet connection is required.
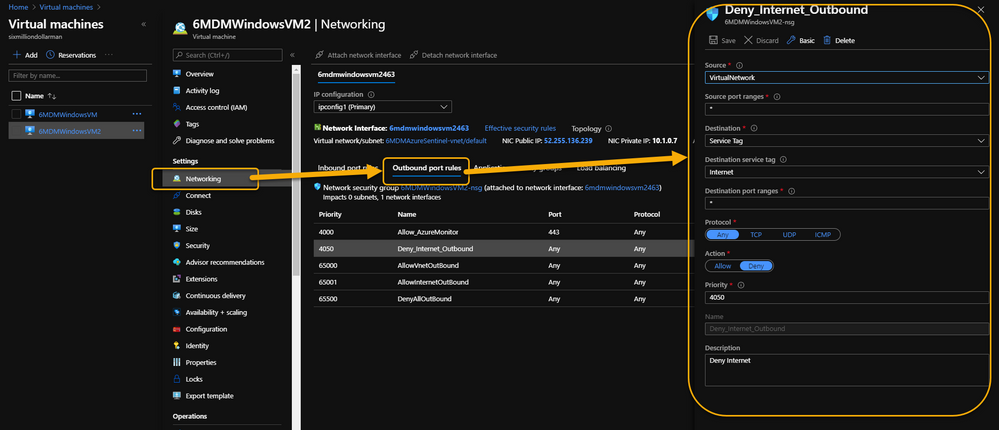
As a security precaution, some customers spin up VMs in Azure and disable all outbound Internet access. This is done through an Outbound rule (VM => Networking => Outbound port rules => Deny Internet) similar to what is shown in the following image:
 VM => Networking => Outbound port rules => Deny Internet
VM => Networking => Outbound port rules => Deny Internet
However, the same customer may also want to monitor potential threats against these VMs using Azure Sentinel. Azure Sentinel, of course, requires a Log Analytics workspace which requires the Log Analytics agent extension to be installed which, yeah…you guessed it…requires the outbound Internet connection already discussed.
Even more interesting is that the Log Analytics agent extension will deploy perfectly. And, unless it’s monitored obsessively, all seems just fine. Well, that is, until it’s realized that the newly installed agent isn’t sending its data to Azure Sentinel’s Log Analytics Workspace.
 Log Analytics Agent cannot connect due to a blocked port
Log Analytics Agent cannot connect due to a blocked port
If it’s required that the Azure VM remains Internet disconnected, the solution is to create a new Outbound rule for the VM to provide the necessary port to trick the agent into thinking it has the required Internet connection. The new Outbound rule also needs to have a higher priority than the blocker, otherwise the port will never be exposed.
The new Outbound rule should look like the following:
 Enable a new Outbound Rule specifically for AzureMonitor
Enable a new Outbound Rule specifically for AzureMonitor
The details:
Create a new Outbound rule with a higher priority than the Deny Internet rule with the following information:
- Source: VirtualNetwork
- Secure port ranges: *
- Destination: ServiceTag
- Destination service tag: AzureMonitor
- Destination port ranges: 443
- Protocol: Any
- Action: Allow
- Priority: (set it higher than the Deny Internet rule)
- Description: (I always recommend being very verbose when describing something you create – just in case you have a tendency to forget later on)
Summary
This technique ensures that the Virtual Machine doesn’t have Internet access according to policy, and that security can still be managed and monitored through Azure Sentinel. Disabling full Internet access for each Virtual Machine may seem a rare occurrence, but as I noted in my opening statement, I regularly work with scenarios that are sometimes uncommon. And, if I see it once, it’s most likely going to happen again. Sharing makes us all smarter.
A use case example where this makes perfect sense is for Windows Virtual Desktops (WVD). Disabling the Internet completely for a compromised WVD, ensures that the device is effectively quarantined from the other VMs in the WVD pool while still maintaining the ability to kick-off a malware scan through an Azure Sentinel Playbook because the Azure Monitor port is still open.
NOTE: In the future, you can Use Azure Private Link to securely connect networks to Azure Monitor.
For additional knowledge in relation to Azure Sentinel-specific role access components, see the following:
Granting Access to Specific Azure Sentinel Playbooks for Specific Analysts: https://secureinfra.blog/2020/06/19/granting-access-to-specific-azure-sentinel-playbooks-for-specific-analysts/
Controlling access to Azure Sentinel Data: Resource RBAC: https://techcommunity.microsoft.com/t5/azure-sentinel/controlling-access-to-azure-sentinel-data-resource-rbac/ba-p/1301463
Table Level RBAC In Azure Sentinel: https://techcommunity.microsoft.com/t5/azure-sentinel/table-level-rbac-in-azure-sentinel/ba-p/965043
Permissions in Azure Sentinel: https://docs.microsoft.com/en-us/azure/sentinel/roles
* Check out my other blog for more Azure Sentinel content: Rod Trent at the Secure Infrastructure Blog
* Follow me on Twitter: https://twitter.com/rodtrent

by Scott Muniz | Jul 23, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
What a busy week for Azure Services! Microsoft Inspire took place this week and new announcements were shared. Announcements include: The next generation of Azure Stack HCI, Numerous Azure Kubernetes Service announcements, Azure IoT Connector to ingest data from Internet of Medical Things (IoMT) devices and Azure Monitor Logs connector.
The new Azure Stack HCI solution
The new Microsoft Azure Stack HCI provides the best-in-class hyper-converged infrastructure stack, which integrates seamlessly into existing on-premises environments using existing processes and tools. It also is delivered as an Azure hybrid service, which natively integrates into your Azure environment, comes with subscription-based billing, and a dedicated support team. It provides many Azure Hybrid services which can be leveraged to make on-premises environments better. More information regarding the Microsoft Inspire announcement can be found here: The next generation of Azure Stack HCI
Numerous Azure Kubernetes Service Announcements
- AKS-managed Azure Active Directory support is now generally available – Azure Kubernetes Service (AKS)-managed Azure Active Directory (Azure AD) support is now generally available. This simplifies AKS integration with Azure AD. Customers are no longer required to create client apps or service apps or require tenant owners to grant elevated permissions. AKS creates appropriate roles/role bindings with group memberships though delegated permissions to facilitate administration.
- Secure Azure Kubernetes Service (AKS) pods with Azure Policy (in preview) – To improve the security of your Azure Kubernetes Service (AKS) cluster, secure your pods with Azure Policy (in preview). Users can choose from a list of built-in options and apply those policies to secure pods.
- Azure Kubernetes Service (AKS) now supports bring-your-own control plane managed identity – Azure Kubernetes Service (AKS) now supports bring-your-own identities for the control plane managed identity. The Kubernetes cloud provider uses this identity to create resources like Azure Load Balancer, public IP addresses, and others on behalf of the user. Managed identities simplify overall management of authorization, as users don’t have to manage service principals on their own.
Azure IoT Connector for FHIR now in preview
IoT Connector enables a new set of scenarios like remote patient monitoring, telehealth, clinical trials, and smart hospitals by bringing PHI data from devices into Azure API for FHIR, which can be used along with other clinical data to enable newer insights and clinical workflows. It can accept JSON-based messages from IoMT devices, use mapping templates to transform device data into a FHIR standard resource, and finally persist the resource into Azure API for FHIR. Use it seamlessly with Azure IoT Central, Azure IoT Hub, and other IoT cloud gateways.
Azure Monitor Logs connector is now generally available
Create automated workflows using hundreds of actions for a variety of services with Azure Logic Apps and Power Automate. The Azure Monitor logs connector is now generally available and can be used to build workflows that retrieve data from the Azure Monitor Logs workspace or Application Insights component.
MS Learn Module of the Week
Implement hybrid identity with Windows Server
In this module, you’ll learn to configure an Azure environment so that Windows IaaS workloads requiring Active Directory are supported. You’ll also learn to integrate on-premises Active Directory Domain Services (AD DS) environment into Azure.
Let us know in the comments below if there are any news items you would like to see covered in next week show. Az Update streams live every Friday. Be sure to catch the next episode and join us in the live chat.
by Scott Muniz | Jul 23, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Monitoring your database is one of the most crucial tasks to ensure a continued healthy and steady workload. Azure Database for PostgreSQL, our managed database service for Postgres, provides a wealth of metrics to monitor your Postgres database on Azure. But what if the very metric that you are after is not yet available?
Worry not because there are ample options to easily create and monitor custom metrics with Azure Database for PostgreSQL. One solution you can use with Postgres on Azure is Datadog’s custom metrics.
If you are not familiar with Datadog, it is one of many solid 3rd party solutions that provides a set of canned metrics for various technologies, including PostgreSQL. Datadog also enables you to poll our databases with the help of custom queries to emit custom metrics data to a central location where you can monitor how well your workload is doing.
If you don’t yet have a Datadog account, no problem, you can use a free trial Datadog account to try out everything I’m going to show you in this post.
What is bloat in Postgres & why should you monitor it?
As a proud owner of a PostgreSQL database, you will inevitably have to experience and manage bloat, which is a product of PostgreSQL’s storage implementation for multi-version concurrency control. Concurrency is achieved by creating different versions of tuples as they receive modifications. As you can imagine, PostgreSQL will keep as many versions of the same tuple as the number of concurrent transactions at any time and make the last committed version visible to the consecutive transactions. Eventually, this creates dead tuples in pages that later need to be reclaimed.
To keep your database humming, it’s important to understand how your table and index bloat values progress over time—and to make sure that garbage collection happens as aggressively as it should. So you need to monitor your bloat in Postgres and act on it as needed.
Before you start, I should clarify that this post is focused on how to monitor bloat on Azure Database for PostgreSQL – Single Server. On Azure, our Postgres managed database service also has a built-in deployment option called Hyperscale (Citus)—based on the Citus open source extension—and this Hyperscale (Citus) option enables you to scale out Postgres horizontally. Because the code snippets and instructions below are a bit different for monitoring a single Postgres server vs. monitoring a Hyperscale (Citus) server group, I plan to publish the how-to instructions for using custom monitoring metrics on a Hyperscale (Citus) cluster in a separate/future blog post. Stay tuned! Now, let’s get started.
First, prepare your monitoring setup for Azure Database for PostgreSQL – Single Server
If you do not already have an Azure Database for PostgreSQL server, you may create one as prescribed in our quickstart documentation.
Create a read-only monitoring user
As a best practice, you should allocate a read-only user to poll your data from database. Depending on what you want to collect, granting pg_monitor role, which is a member of pg_read_all_settings, pg_read_all_stats and pg_stat_scan_tables starting from Postgres 10, could be sufficient.
For this situation, we will also need to GRANT SELECT for the role to all the tables that we want to track for bloat.
CREATE USER metrics_reader WITH LOGIN NOSUPERUSER NOCREATEDB NOCREATEROLE INHERIT NOREPLICATION CONNECTION LIMIT 1 PASSWORD 'xxxxxx';
GRANT pg_monitor TO metrics_reader;
--Rights granted here as blanket for simplicity.
GRANT SELECT ON ALL TABLES IN SCHEMA public to metrics_reader;
Create your bloat monitoring function
To keep Datadog configuration nice and tidy, let’s first have a function to return the bloat metrics we want to track. Create the function below in the Azure Database for PostgreSQL – Single Server database you would like to track.
If you have multiple databases to track, you can consider an aggregation mechanism from different databases into a single monitoring database to achieve the same objective. This how-to post is designed for a single database, for the sake of simplicity.
The bloat tracking script used here is a popular choice and was created by Greg Sabino Mullane. There are other bloat tracking scripts out there in case you want to research a better fitting approach to track your bloat estimates and adjust your get_bloat function.
CREATE OR REPLACE FUNCTION get_bloat ()
RETURNS TABLE (
database_name NAME,
schema_name NAME,
table_name NAME,
table_bloat NUMERIC,
wastedbytes NUMERIC,
index_name NAME,
index_bloat NUMERIC,
wastedibytes DOUBLE PRECISION
)
AS $$
BEGIN
RETURN QUERY SELECT current_database() as databasename, schemaname, tablename,ROUND((CASE WHEN otta=0 THEN 0.0 ELSE sml.relpages::FLOAT/otta END)::NUMERIC,1) AS tbloat,CASE WHEN relpages < otta THEN 0 ELSE bs*(sml.relpages-otta)::BIGINT END AS wastedbytes,iname, ROUND((CASE WHEN iotta=0 OR ipages=0 THEN 0.0 ELSE ipages::FLOAT/iotta END)::NUMERIC,1) AS ibloat,CASE WHEN ipages < iotta THEN 0 ELSE bs*(ipages-iotta) END AS wastedibytes FROM (SELECT schemaname, tablename, cc.reltuples, cc.relpages, bs,CEIL((cc.reltuples*((datahdr+ma-(CASE WHEN datahdr%ma=0 THEN ma ELSE datahdr%ma END))+nullhdr2+4))/(bs-20::FLOAT)) AS otta,COALESCE(c2.relname,'?') AS iname, COALESCE(c2.reltuples,0) AS ituples, COALESCE(c2.relpages,0) AS ipages,COALESCE(CEIL((c2.reltuples*(datahdr-12))/(bs-20::FLOAT)),0) AS iotta FROM (SELECT ma,bs,schemaname,tablename,(datawidth+(hdr+ma-(CASE WHEN hdr%ma=0 THEN ma ELSE hdr%ma END)))::NUMERIC AS datahdr,(maxfracsum*(nullhdr+ma-(CASE WHEN nullhdr%ma=0 THEN ma ELSE nullhdr%ma END))) AS nullhdr2 FROM (SELECT schemaname, tablename, hdr, ma, bs,SUM((1-null_frac)*avg_width) AS datawidth,MAX(null_frac) AS maxfracsum,hdr+(SELECT 1+COUNT(*)/8 FROM pg_stats s2 WHERE null_frac<>0 AND s2.schemaname = s.schemaname AND s2.tablename = s.tablename) AS nullhdr FROM pg_stats s, (SELECT(SELECT current_setting('block_size')::NUMERIC) AS bs,CASE WHEN SUBSTRING(v,12,3) IN ('8.0','8.1','8.2') THEN 27 ELSE 23 END AS hdr,CASE WHEN v ~ 'mingw32' THEN 8 ELSE 4 END AS ma FROM (SELECT version() AS v) AS foo) AS constants GROUP BY 1,2,3,4,5) AS foo) AS rs JOIN pg_class cc ON cc.relname = rs.tablename JOIN pg_namespace nn ON cc.relnamespace = nn.oid AND nn.nspname = rs.schemaname AND nn.nspname <> 'information_schema' LEFT JOIN pg_index i ON indrelid = cc.oid LEFT JOIN pg_class c2 ON c2.oid = i.indexrelid) AS sml WHERE schemaname NOT IN ('pg_catalog') ORDER BY wastedbytes DESC;
END; $$
LANGUAGE 'plpgsql';
Confirm your read-only Postgres user can observe results
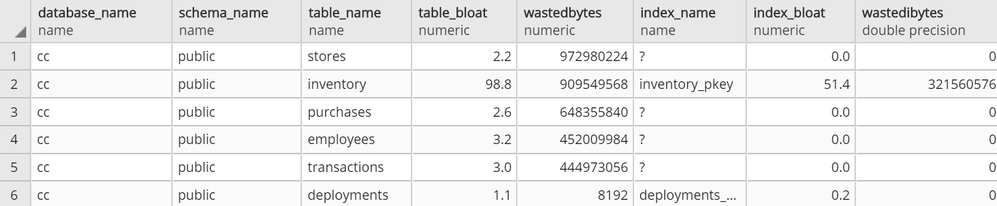
At this point, you should be able to connect to your Azure Database for PostgreSQL server with your read-only user and run SELECT * FROM get_bloat(); to observe results.
 get_bloat function’s sample output
get_bloat function’s sample output
If you don’t get anything in the output, see if the following steps remedy this:
- Check your pg_stat records with
SELECT * FROM pg_stats WHERE schemaname NOT IN ('pg_catalog','information_schema');
- If you don’t see your table and columns in there, make sure to run
ANALYZE <your_table> and try again
- If you still don’t see your table in the result set from #1, your user very likely does not have select privilege on a table that you expect to see in the output
Then, setup your 3rd party monitoring (in this case, with Datadog)
Once you confirm that your read-only user is able to collect the metrics you want to track on your Azure Postgres single server, you are now ready to set up your 3rd party monitoring!
For this you will need two things. First, a Datadog account. Second, a machine that will host your Datadog agent, to do the heavy lifting of connecting to your database to extract the metrics you want and to push the metrics into your Datadog workspace.
For this exercise, I had an Azure Linux virtual machine handy that I could use as the agent host, but you can follow quickstart guides available for Azure Virtual Machines to create a new machine or use an existing one. Datadog provides scripts to set up diverse environments, which you can find after you log in to your Datadog account and go to the Agents section in Datadog’s Postgres Integrations page. Following the instructions, you should get message similar to the following.
 datadog agent setup success state
datadog agent setup success state
Next step is to configure datadog agent for Postgres specific collection. If you aren’t already working with an existing postgres.d/conf.yaml, just copy the conf.yaml.example in /etc/datadog-agent/conf.d/postgres.d/ and adjust to your needs.
Once you follow the directions and set up your host, port, user, and password in /etc/datadog-agent/conf.d/postgres.d/conf.yaml, the part that remains is to set up your custom metrics section with below snippet.
custom_queries:
- metric_prefix: azure.postgres.single_server.custom_metrics
query: select database_name, schema_name, table_name, table_bloat, wastedbytes, index_name, index_bloat, wastedibytes from get_bloat();
columns:
- name: database_name
type: tag
- name: schema_name
type: tag
- name: table_name
type: tag
- name: table_bloat
type: gauge
- name: wastedbytes
type: gauge
- name: index_name
type: tag
- name: index_bloat
type: gauge
- name: wastedibytes
type: gauge
Once this step is done, all you need to do is to restart your datadog-agent sudo systemctl restart datadog-agent for your custom metrics to start flowing in.
Setup your new bloat monitoring dashboard for Azure Database for PostgreSQL – Single Server
If all goes well, you should be able to see your custom metrics in Metrics Explorer shortly!
 azure postgresql custom metrics flowing successfully into datadog workspace
azure postgresql custom metrics flowing successfully into datadog workspace
From above you can export these charts to a new or existing dashboard and edit the widgets to your needs to show separate visuals by dimensions as table or index or you can simply overlay them as below. Datadog documentation is quite rich to help you out.
 custom metrics added to a new dashboard
custom metrics added to a new dashboard
Knowing how your bloat metrics are trending will help you investigate performance problems and help you to identify if bloat is contributing to performance fluctuations. Monitoring bloat in Postgres will also help you evaluate whether your workload (or your Postgres tables) are configured optimally for autovacuum to perform its function.
Using custom metrics makes it easy to monitor bloat in Azure Database for PostgreSQL
You can and absolutely should track bloat. And with custom metrics and Datadog, you can easily track bloat in your workload for an Azure Database for PostgreSQL server. You can track other types of custom Postgres metrics easily in the same fashion.
One more thing to keep in mind: I recommend you always be intentional on what and how to collect, as metric polling can impact your workload.
If you have a much more demanding workload and are using Hyperscale (Citus) to scale out Postgres horizontally, I will soon have a post on how you can monitor bloat with custom metrics in Azure Database for Postgres – Hyperscale (Citus). I look forward to seeing you there!
by Scott Muniz | Jul 23, 2020 | Alerts, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
In my introductory post we saw that there are many different ways in which you can host a GraphQL service on Azure and today we’ll take a deeper look at one such option, Azure App Service, by building a GraphQL server using dotnet. If you’re only interested in the Azure deployment, you can jump forward to that section. Also, you’ll find the complete sample on my GitHub.
Getting Started
For our server, we’ll use the graphql-dotnet project, which is one of the most common GraphQL server implementations for dotnet.
First up, we’ll need an ASP.NET Core web application, which we can create with the dotnet cli:
Next, open the project in an editor and add the NuGet packages we’ll need:
<PackageReference Include="GraphQL.Server.Core" Version="3.5.0-alpha0046" />
<PackageReference Include="GraphQL.Server.Transports.AspNetCore" Version="3.5.0-alpha0046" />
<PackageReference Include="GraphQL.Server.Transports.AspNetCore.SystemTextJson" Version="3.5.0-alpha0046" />
At the time of writing graphql-dotnet v3 is in preview, we’re going to use that for our server but be aware there may be changes when it is released.
These packages will provide us a GraphQL server, along with the middleware needed to wire it up with ASP.NET Core and use System.Text.Json as the JSON seralizer/deserializer (you can use Newtonsoft.Json if you prefer with this package).
We’ll also add a package for GraphiQL, the GraphQL UI playground, but it’s not needed or recommended when deploying into production.
<PackageReference Include="GraphQL.Server.Ui.Playground" Version="3.5.0-alpha0046" />
With the packages installed, it’s time to setup the server.
Implementing a Server
There are a few things that we need when it comes to implementing the server, we’re going to need a GraphQL schema, some types that implement that schema and to configure our route engine to support GraphQL’s endpoints. We’ll start by defining the schema that’s going to support our server and for the schema we’ll use a basic trivia app (which I’ve used for a number of GraphQL demos in the past). For the data, we’ll use Open Trivia DB.
.NET Types
First up, we’re going to need some generic .NET types that will represent the underlying data structure for our application. These would be the DTOs (Data Transfer Objects) that we might use in Entity Framework, but we’re just going to run in memory.
public class Quiz
{
public string Id
{
get
{
return Question.ToLower().Replace(" ", "-");
}
}
public string Question { get; set; }
[JsonPropertyName("correct_answer")]
public string CorrectAnswer { get; set; }
[JsonPropertyName("incorrect_answers")]
public List IncorrectAnswers { get; set; }
}
As you can see, it’s a fairly generic C# class. We’ve added a few serialization attributes to help converting the JSON to .NET, but otherwise it’s nothing special. It’s also not usable with GraphQL yet and for that, we need to expose the type to a GraphQL schema, and to do that we’ll create a new class that inherits from ObjectGraphType<Quiz> which comes from the GraphQL.Types namespace:
public class QuizType : ObjectGraphType<Quiz>
{
public QuizType()
{
Name = "Quiz";
Description = "A representation of a single quiz.";
Field(q => q.Id, nullable: false);
Field(q => q.Question, nullable: false);
Field(q => q.CorrectAnswer, nullable: false);
Field<NonNullGraphType<ListGraphType<NonNullGraphType>>>("incorrectAnswers");
}
}
The Name and Description properties are used provide the documentation for the type, next we use Field to define what we want exposed in the schema and how we want that marked up for the GraphQL type system. We do this for each field of the DTO that we want to expose using a lambda like q => q.Id, or by giving an explicit field name (incorrectAnswers). Here’s also where you control the schema validation information as well, defining the nullability of the fields to match the way GraphQL expects it to be represented. This class would make a GraphQL type representation of:
type Quiz {
id: String!
question: String!
correctAnswer: String!
incorrectAnswers: [String!]!
}
Finally, we want to expose a way to query our the types in our schema, and for that we’ll need a Query that inherits ObjectGraphType:
public class TriviaQuery : ObjectGraphType
{
public TriviaQuery()
{
Field<NonNullGraphType<ListGraphType<NonNullGraphType<QuizType>>>>("quizzes", resolve: context =>
{
throw new NotImplementedException();
});
Field<NonNullGraphType<QuizType>>("quiz", arguments: new QueryArguments() {
new QueryArgument<NonNullGraphType<StringGraphType>> { Name = "id", Description = "id of the quiz" }
},
resolve: (context) => {
throw new NotImplementedException();
});
}
}
Right now there is only a single type in our schema, but if you had multiple then the TriviaQuery would have more fields with resolvers to represent them. We’ve also not implemented the resolver, which is how GraphQL gets the data to return, we’ll come back to that a bit later. This class produces the equivalent of the following GraphQL:
type TriviaQuery {
quizzes: [Quiz!]!
quiz(id: String!): Quiz!
}
Creating a GraphQL Schema
With the DTO type, GraphQL type and Query type defined, we can now implement a schema to be used on the server:
public class TriviaSchema : Schema
{
public TriviaSchema(TriviaQuery query)
{
Query = query;
}
}
Here we would also have mutations and subscriptions, but we’re not using them for this demo.
Wiring up the Server
For the Server we integrate with the ASP.NET Core pipeline, meaning that we need to setup some services for the Dependency Injection framework. Open up Startup.cs and add update the ConfigureServices:
public void ConfigureServices(IServiceCollection services)
{
services.AddTransient<HttpClient>();
services.AddSingleton<QuizData>();
services.AddSingleton<TriviaQuery>();
services.AddSingleton<ISchema, TriviaSchema>();
services.AddGraphQL(options =>
{
options.EnableMetrics = true;
options.ExposeExceptions = true;
})
.AddSystemTextJson();
}
The most important part of the configuration is lines 8 – 13, where the GraphQL server is setup and we’re defining the JSON seralizer, System.Text.Json. All the lines above are defining dependencies that will be injected to other types, but there’s a new type we’ve not seen before, QuizData. This type is just used to provide access to the data store that we’re using (we’re just doing in-memory storage using data queried from Open Trivia DB), so I’ll skip its implementation (you can see it on GitHub).
With the data store available, we can update TriviaQuery to consume the data store and use it in the resolvers:
public class TriviaQuery : ObjectGraphType
{
public TriviaQuery(QuizData data)
{
Field<NonNullGraphType<ListGraphType<NonNullGraphType<QuizType>>>>("quizzes", resolve: context => data.Quizzes);
Field<NonNullGraphType<QuizType>>("quiz", arguments: new QueryArguments() {
new QueryArgument<NonNullGraphType<StringGraphType>> { Name = "id", Description = "id of the quiz" }
},
resolve: (context) => data.FindById(context.GetArgument<string>("id")));
}
}
Once the services are defined we can add the routing in:
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseGraphQLPlayground();
}
app.UseRouting();
app.UseGraphQL<ISchema>();
}
I’ve put the inclusion GraphiQL. within the development environment check as that’d be how you’d want to do it for a real app, but in the demo on GitHub I include it every time.
Now, if we can launch our application, navigate to https://localhost:5001/ui/playground and run the queries to get some data back.
Deploying to App Service
With all the code complete, let’s look at deploying it to Azure. For this, we’ll use a standard Azure App Service running the latest .NET Core (3.1 at time of writing) on Windows. We don’t need to do anything special for the App Service, it’s already optimised to run an ASP.NET Core application, which is all this really is. If we were using a different runtime, like Node.js, we’d follow the standard setup for a Node.js App Service.
To deploy, we’ll use GitHub Actions, and you’ll find docs on how to do that already written. You’ll find the workflow file I’ve used in the GitHub repo.
With a workflow committed and pushed to GitHub and our App Service waiting, the Action will run and our application will be deployed. The demo I created is here.
Conclusion
Throughout this post we’ve taken a look at how we can create a GraphQL server running on ASP.NET Core using graphql-dotnet and deploy it to an Azure App Service.
When it comes to the Azure side of things, there’s nothing different we have to do to run the GraphQL server in an App Service than any other ASP.NET Core application, as graphql-dotnet is implemented to leverage all the features of ASP.NET Core seamlessly.
Again, you’ll find the complete sample on my GitHub for you to play around with yourself.
This post was originally published on www.aaron-powell.com .

Recent Comments