This article is contributed. See the original author and article here.
Troubleshooting Azure Stack HCI 23H2 Preview Deployments
With Azure Stack HCI release 23H2 preview, there are significant changes to how clusters are deployed, enabling low touch deployments in edge sites. Running these deployments in customer sites or lab environments may require some troubleshooting as kinks in the process are ironed out. This post aims to give guidance on this troubleshooting.
The following is written using a rapidly changing preview release, based on field and lab experience. We’re focused on how to start troubleshooting, rather than digging into specific issues you may encounter.
Understanding the deployment process
Deployment is completed in two steps: first, the target environment and configuration are validated, then the validated configuration is applied to the cluster nodes by a deployment. While ideally any issues with the configuration will be caught in validation, this is not always the case. Consequently, you may find yourself working through issues in validation only to also have more issues during deployment to troubleshoot. We’ll start with tips on working through validation issues then move to deployment issues.
When the validation step completes, a ‘deploymentSettings’ sub-resource is created on your HCI cluster Azure resource.
Logs Everywhere!
When you run into errors in validation or deployment the error passed through to the Portal may not have enough information or context to understand exactly what is going on. To get to the details, we frequently need to dig into the log files on the HCI nodes. The validation and deployment processes pull in components used in Azure Stack Hub, resulting in log files in various locations, but most logs are on the seed node (the first node sorted by name).
Viewing Logs on Nodes
When connected to your HCI nodes with Remote Desktop, Notepad is available for opening log files and checking contents. Another useful trick is to use the PowerShell Get-Content command with the -wait parameter to follow a log and -last parameter to show only recent lines. This is especially helpful to watch the CloudDeployment log progress. For example:
Get-Content C:CloudDeploymentLogsCloudDeployment.2024-01-20.14-29-13.0.log -wait -last 150
Log File Locations
The table below describes important log locations and when to look in each:
Path | Content | When to use… |
C:CloudDeploymentLogsCloudDeployment* | Output of deployment operation | This is the primary log to monitor and troubleshoot deployment activity. Look here when a deployment fails or stalls |
C:CloudDeploymentLogsEnvironmentValidatorFull* | Output of validation run | When your configuration fails a validation step |
C:ECEStoreLCMECELiteLogsInitializeDeploymentService* | Logs related to the Life Cycle Manager (LCM) initial configuration | When you can’t start validation, the LCM service may not have been fully configured |
C:ECEStoreMASLogs | PowerShell script transcript for ECE activity | Shows more detail on scripts executed by ECE—this is a good place to look if CloudDeployment shows an error but not enough detail |
C:CloudDeploymentLogscluster* | Cluster validation report | Cluster validation runs when the cluster is created; when validation fails, these logs tell you why |
Retrying Validations and Deployments
Retrying Validation
In the Portal, you can usually retry validation with the “Try Again…” button. If you are using an ARM template, you can redeploy the template.
In the Validation stage, your node is running a series of scripts and checks to ensure it is ready for deployment. Most of these scripts are part of the modules found here:
C:Program FilesWindowsPowerShellModulesAzStackHci.EnvironmentChecker
Sometimes it can be insightful to run the modules individually, with verbose or debug output enabled.
Retrying Deployment
The ‘deploymentSettings’ resource under your cluster contains the configuration to deploy and is used to track the status of your deployment. Sometimes it can be helpful to view this resource; an easy way to do this is to navigate to your Azure Stack HCI cluster in the Portal and append ‘deploymentsettings/default’ after your cluster name in the browser address bar.

Image 1 – the deploymentSettings Resource in the Portal
From the Portal
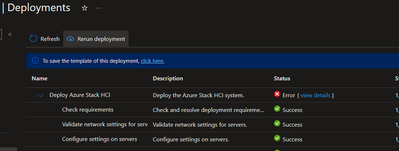
In the Portal, if your Deployment stage fails part-way through, you can usually restart the deployment by clicking the ‘Return Deployment’ button under Deployments at the cluster resource.
Image 2 – access the deployment in the Portal so you can retry
Alternatively, you can navigate to the cluster resource group deployments. Find the deployment matching the name of your cluster and initiate a redeploy using the Redeploy option.

Image 3 – the ‘Redploy’ button on the deployment view in the Portal
If Azure/the Portal show your deployment as still in progress, you won’t be able to start it again until you cancel it or it fails.
From an ARM Template
To retry a deployment when you used the ARM template approach, just resubmit the deployment. With the ARM template deployment, you submit the same template twice—once with deploymentMode: “Validate” and again with deploymentMode: “Deploy”. If you’re wanting to retry validation, use “Validate” and to retry deployment, use “Deploy”.

Image 4 – ARM template showing deploymentMode setting
Locally on the Seed Node
In most cases, you’ll want to initiate deployment, validation, and retries from Azure. This ensures that your deploymentSettings resource is at the same stage as the local deployment.
However, in some instances, the deployment status as Azure understands it becomes out of sync with what is going on at the node level, leaving you unable to retry a stuck deployment. For example, Azure has your deploymentSettings status as “Provisioning” but the logs in CloudDeployment show the activity has stopped and/or the ‘LCMAzureStackDeploy’ scheduled task on the seed node is stopped. In this case, you may be able to rerun the deployment by restarting the ‘LCMAzureStackDeploy’ scheduled task on the seed node:
Start-ScheduledTask -TaskName LCMAzureStackDeploy
If this does not work, you may need to delete the deploymentSettings resource and start again. See: The big hammer: full reset.
Advanced Troubleshooting
Invoking Deployment from PowerShell
Although deployment activity has lots of logging, sometimes either you can’t find the right log file or seem to be missing what is causing the failure. In this case, it is sometimes helpful to retry the deployment directly in PowerShell, executing the script which is normally called by the Scheduled Task mentioned above. For example:
C:CloudDeploymentSetupInvoke-CloudDeployment.ps1 -Rerun
Local Group Membership
In a few cases, we’ve found that the local Administrators group membership on the cluster nodes does not get populated with the necessary domain and virtual service account users. The issues this has caused have been difficult to track down through logs, and likely has a root cause which will soon be addressed.
Check group membership with: Get-LocalGroupMember Administrators
Add group membership with: Add-LocalGroupMember Administrators -Member [,…]
Here’s what we expect on a fully deployed cluster:
Type | Accounts | Comments |
Domain Users | DOMAIN | This is the domain account created during AD Prep and specified during deployment |
Local Users | AzBuiltInAdmin (renamed from Administrator) ECEAgentService | These accounts don’t exist initially but are created at various stages during deployment. Try adding them—if they are not provisioned, you’ll get a message that they don’t exist. |
Virtual Service Accounts | S-1-5-80-1219988713-3914384637-3737594822-3995804564-465921127 S-1-5-80-949177806-3234840615-1909846931-1246049756-1561060998 S-1-5-80-2317009167-4205082801-2802610810-1010696306-420449937 S-1-5-80-3388941609-3075472797-4147901968-645516609-2569184705 S-1-5-80-463755303-3006593990-2503049856-378038131-1830149429 S-1-5-80-649204155-2641226149-2469442942-1383527670-4182027938 S-1-5-80-1010727596-2478584333-3586378539-2366980476-4222230103 S-1-5-80-3588018000-3537420344-1342950521-2910154123-3958137386 | These are the SIDs of the various virtual service accounts used to run services related to deployment and continued lifecycle management. The SIDs seem to be hard coded, so these can be added any time. When these accounts are missing, there are issues as early as the JEA deployment step. |
ECEStore
The files in the ECEStore directory show state and status information of the ECE service, which handles some lifecycle and configuration management. The JSON files in this directory may be helpful to troubleshoot stuck states, but most events also seem to be reported in standard logs. The MASLogs directory in the ECEStore directory shows PowerShell transcripts, which can be helpful as well.
NUGET Packages
During initialization, several NuGet packages are downloaded and extracted on the seed node. We’ve seen issues where these packages are incomplete or corrupted—usually noted in the MASLogs directory. In this case, the The big hammer: full reset option seems to be required.
The Big Hammer: Full Reset
If you’ve pulled the last of your hair out, the following steps usually perform a full reset of the environment, while avoiding needing to reinstall the OS and reconfigure networking, etc (the biggest hammer). This is not usually necessary and you don’t want to go through this only to run into the same problem, so spend some time with the other troubleshooting options first.
- Uninstall the Arc agents on all nodes with the Remove-AzStackHciArcInitialization command
- Delete the deploymentSettings resource in Azure
- Delete the cluster resource in Azure
- Reboot the seed node
- Delete the following directories on the seed node:
- C:CloudContent
- C:CloudDeployment
- C:Deployment
- C:DeploymentPackage
- C:EceStore
- C:NugetStore
- Remove the LCMAzureStackStampInformation registry key on the seed node:
Get-Item -path HKLM:SOFTWAREMicrosoftLCMAzureStackStampInformation | Remove-Item -whatif - Reinitialize Arc on each node with Invoke-AzStackHciArcInitialization and retry the complete deployment
Conclusion
Hopefully this guide has helped you troubleshoot issues with your deployment. Please feel free to comment with additional suggestions or questions and we’ll try to get those incorporated in this post.
If you’re still having issues, a Support Case is your next step!
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments