This article is contributed. See the original author and article here.
The connections established to Azure SQL Database from applications or client tools may be unexpectedly terminated and impact user environments due to internal (System) maintenance work, client networking, application related or other health related issues. In this blog post, we will cover recommended steps to identify connection failures to your database and best practices to handle these failures using resources & tools available for Azure SQL Database.
Understanding the connection Problem!
When it comes to understanding a problem, we need to know where the issue is occurring, whether this is happening on the client side, or it is an issue specific to the network layer or on the SQL database itself. Most of the time, the error messages the customer receives will tell exactly where the problem is and that’s the best place to start.
When you have issues related to accessing database, the best place to start with is the Azure Resource heath blade. Resource Health gives you a personalized dashboard of the health of your resources including your SQL Database. Currently, Resource Health for your SQL Database resource examines login failures due to system errors.
The health of a resource is displayed as one of the following statuses.
A status of Available (informational) means that Resource Health has not detected login failures due to system errors on your SQL resource.
This is an informational message. It doesn’t indicate a problem but provides interesting information to an operator, such as successful completion of a regular process.
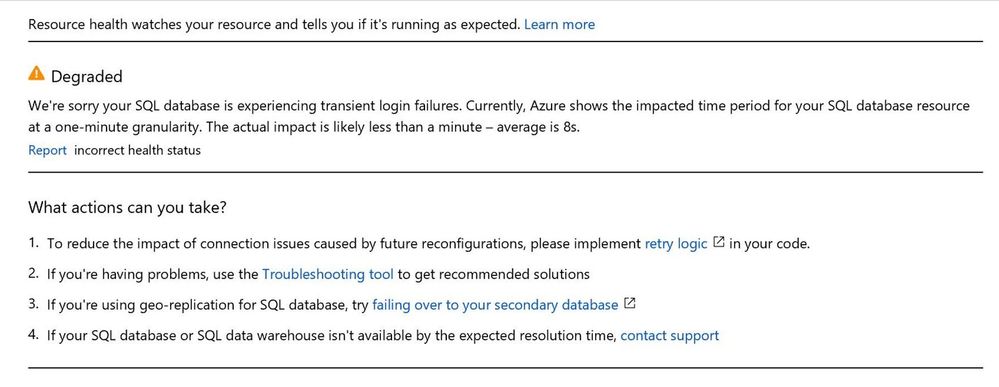
A status of Degraded (warning) means that Resource Health has detected many successful logins, but some failures as well. These are most likely transient login errors.
The health status of Unknown (warning) indicates that Resource Health hasn’t received information about this resource for more than 10 minutes. Although this status isn’t a definitive indication of the state of the resource, it is an important data point in the troubleshooting process. If the resource is running as expected, the status of the resource will change to Available after a few minutes. If you’re experiencing problems with the resource, the Unknown health status might suggest that an event in the platform is affecting the resource.
Degraded and Unknown status are warnings and should be ignored if availability is not impacted for customers.
A status of Unavailable (Critical) means that Resource Health has detected consistent login failures to your SQL resource. If your resource remains in this state for an extended period, contact support.
This is a critical message indicating loss of service or application availability or severe degradation of performance. Requires immediate attention.
Below image is an example of what you see if the database is reported as degraded in the Resource health blade.
SQL Connectivity Issues
Looking at the SQL side of connectivity issues, we often see customers not able to reach their database because of an availability issue.
This situation manifests itself in the form of the following error message.
Database x on server y is not currently available (Error 40613)
Most of the time, these issues are transient, meaning the underlying cause soon resolves itself. An occasional cause of transient errors is when there are unexpected events, such as software crash or a hardware failure that might cause failover or if the Azure system quickly shifts hardware resources to better load-balance various workloads. Most of these reconfiguration events finish in less than 60 seconds. During this reconfiguration time span, you might have issues with connecting to your Azure SQL Database.
Other common causes include planned maintenance to deploy software upgrades and other system enhancements. This usually occurs fewer than two times a month. One can enable Advance Notifications (preview) to be sent up to 24 hours before any planned event.
Applications that connect to your database should be built to expect these transient errors. To handle them, implement Retry Logic in the code instead of surfacing them to users as application errors.
In some situations, the customer uses the retry logic, but still sees the error messages. The reason is that they do not follow the principles of retry.
Principles for retry
- SQL SELECT statement should be retried after a fresh connection has been established.
- Logic must ensure that either the entire database transaction completed, or rolled back
- Applications using 3rd party middleware – confirm that the retry logic is enabled by vendor.
- Minimum 5 secs interval between retries. *
* When connection pooling is enabled, and if a timeout error or other login error occurs, an exception will be thrown and subsequent connection attempts will fail for the next five seconds, the “blocking period”. If the application attempts to connect within the blocking period, the first exception will be thrown again. Subsequent failures after a blocking period ends will result in a new blocking period that is twice as long as the previous blocking period, up to a maximum of one minute.
For a discussion of the blocking period for clients that use ADO.NET, see Connection pooling (ADO.NET).
Sometimes the transient issues can also become non transient where we lose connections for a few minutes or a few hours.
For example: A plannedunplanned event interrupted a long running transaction (such as large bulk insert operations or index build operations against a large table). The chances are it takes longer time for performing the recovery operations. The longer the recovery operation, the longer the availability issue the customer is going to face. Connectivity can only resume after the recovery is completed.
Another scenario, which customers experience is resource limit being reached, where the request hits the threshold limit assigned for the service tier.
This is usually seen in the DTU based service tiers where Azure SQL Database limits the number of concurrent sessions to the database and one has an increased workload.
We can monitor the session count using Azure Metrics as shown below

If your application uses connection pooling, a slowdown in query response time might cause a constant rate of front-end requests to require more back-end database connections. If a live incident is ongoing where the worker limit has been approached or reached, you may receive Error 10928 when you connect using SQL Server Management Studio (SSMS) or Azure Data Studio. One session can connect using the Diagnostic Connection for Database Administrators (DAC) even when the maximum worker threshold has been reached.
DAC was built to help you connect and run basic troubleshooting queries in cases of serious performance problems. It allows us to connect to the database despite the limit has been reached.
Note: Only one Dedicated admin connection is available for us to log in and check the database.
You should not try connecting to DAC using the object browser in SSMS because it creates multiple connections for getting the graphical view of an instance.
In the SSMS, go to File -> New -> Database Engine Query and try specifying the DAC connection.
Prefix server name with ADMIN: as shown below

Click on Options -> Connection Properties and specify the database that you are connecting to.

Click on connect, and you can connect to Azure SQL DB with a DAC connection. In the connection bar, you can see, we are connected to Azure SQL Server using Admin: prefix, i.e. DAC connection. Now you can run dmv’s for any diagnostic information.
To remediate from this issue,
- One can scale the database to a larger service tier that can handle the workload. Switch to an elastic pool or vCore-based purchasing models, which removes the session limit (increasing it to 30000)
- Identify long-running or resource-intensive queries using Query Performance Insight and look for other performance bottlenecks so that the workload is handled by the current service tier.
Another issue that we observe is Dropped connections to Azure SQL database:
When you connect to an Azure SQL Database, idle connections may be terminated by a network component (such as a firewall) after a period of inactivity. There are two types of idle connections, in this context:
- Idle at the TCP layer, where connections can be dropped by any number of network devices.
- Idle by the Azure SQL Gateway, where TCP keepalive messages might be occurring (which makes the connection not idle from a TCP perspective), but not had an active query in 30 minutes. In this scenario, the Gateway will determine that the TDS connection is idle at 30 minutes and terminates the connection.
To avoid the Gateway terminating idle connections, you can use the Redirect connection policy instead of proxy to configure your Azure SQL data source.
Note: The recommendation is to use redirect connection policy for improved performance.
To avoid dropping idle connections by a network component, set the following registry settings or their non-Windows equivalents on the operating system where the driver is loaded:

Restart the computer for the registry settings to take effect.
Also have the latest client drivers ( JDBC, OLEDB and so on ) installed.
We also see communication link failures on the network side. It usually manifests like the errors below.
- A connection was successfully established with the server, but then an error occurred during the login process. (provider: SSL Provider, error: 0 – An existing connection was forcibly closed by the remote host.)
- A connection was successfully established with the server, but then an error occurred during the pre-login handshake. (provider: TCP Provider, error: 0 – An existing connection was forcibly closed by the remote host.)
We get this situation when customers are not using the updated drivers. The recommendation for this situation is to have the updated driver, Which would support the TLS 1.2 version that’s just default for the SQL database.
We do also have an option for customers to use the lower version of TLS, but it is not recommended. We always recommend to use the updated version of the driver.
We also see this error if your administrator restricted certain algorithms on the client. The TLS protocols match between the client and the server but there are no matching TLS cipher suits.
Refer to the link below for more information
Another common issue that we see is customers getting confused between a connection timeout and query timeout. The connection or login timeout occurs when the initial connection to the database server reaches a predefined time-out period. At this stage, no query has been submitted to the server. Understanding the error messages and exceptions in this case, checking the class, if it is a SQL connection class or it’s a SQL command class would tell us whether this is a performance related issues or a connection timeout issue and then take necessary steps onward.
In the below screenshot, we can observe the difference in error messages between a connection timeout vs query timeout.


For troubleshooting query timeouts in Azure SQL Database, refer to the links below.
Lesson Learned #254: Checking Execution Timeouts in Azure Log Analytics – Microsoft Community Hub
Find query execution timeouts with Query Store
We can leverage the Connectivity checker tool for end-to-end checks and to understand the connection failures.
Azure/SQL-Connectivity-Checker:
The checker is a PowerShell script that automates a series of checks for the most common connectivity issues. It performs an end-to-end connection check. It checks for your certificates, gateway connections and then connects to your master database, user databases and then also performs pre-login checks and in addition, it also allows us to capture the network trace for it. This gives us a clear idea of where the connection is failing and if I’m not sure what to do, I can do the network capture and give it to the support team to handle this efficiently.
Most issues it detects come with recommended solutions. Instructions to run the script can be found in the above link.
Summary
- Identify the problem source.
- Understand Transient / Non-Transient connection issues
- Handle transient conditions using retry logic
- Use error stack/exception to understand timeout scenarios
- Consider using Redirect policy to prevent dropped connection scenarios and for performance improvement
- Use updated driver versions to match TLS version and avoid communication failures.
- Leverage the Connectivity checker tool for end-to-end check and to understand the connection failures.
Resources
Most of the above topics I covered are explained in these links. Please refer to them for a detailed explanation.
Use Azure Resource Health to monitor database health – Azure SQL Database | Microsoft Learn
Troubleshoot common connection issues to Azure SQL Database – Azure SQL Database | Microsoft Learn Understanding Connectivity issues in SQL Database | Data Exposed – YouTube
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments