This article is contributed. See the original author and article here.
Introducing Unified Neural Text Analyzer: an innovation for Neural Text-to-Speech pronunciation accuracy improvement
This post is co-authored by Dongxu Han, Junwei Gan and Sheng Zhao
Neural Text-to-Speech (Neural TTS), part of Speech in Azure Cognitive Services, enables you to convert text to lifelike speech for more natural user interactions. Neural TTS has powered a wide range of scenarios, from audio content creation to natural-sounding voice assistants, for customers from all over the world. For example, BBC, Progressive and Motorola Solutions are using Azure Neural TTS to develop conversational interfaces for their voice assistants in English speaking locales. Swisscom and Poste Italiane are adopting neural voices in French, German and Italian to interact with their customers in the European market. Hongdandan, a non-profit organization, is adopting neural voices in Chinese to make their online library audible for the blind people in China.
In this blog, we introduce our latest innovation in the Neural TTS technology that helps to improve the pronunciation accuracy significantly: Unified Neural Text Analyzer.
What is text analyzer?
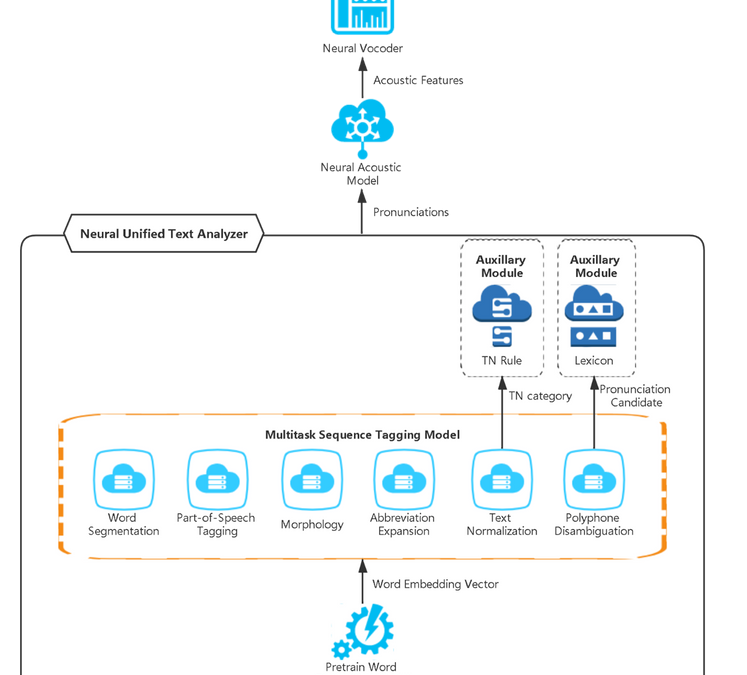
Neural TTS converts plain text into wave form via three modules: neural text analyzer, neural acoustic model and neural vocoder. Text analyzer converts plain text to pronunciations, acoustic model converts pronunciations to acoustic features and finally vocoder generates waveforms. Text analyzer is the first link of the entire TTS system with results directly affecting the acoustic model and vocoder. The correct pronunciation of a word or phrase is the basic expectation in TTS, which delivers the right information to use but it’s not always easy. For example, “live” should be read different in “We live in a mobile world” and “TV Apps and live streaming offerings from The Weather Network” depending on context. If TTS reads them incorrectly, the intelligibility and naturalness of the content will be significantly influenced. Thus, text analyzer is important to TTS.
Recent updates on Neural TTS include a major innovation to the text analyzer, called “UniTA” (Unified Neural Text Analyzer). UniTA is a unified text analyzer model, which seamlessly simplifies text analyzer workflow and reduces time latency in the runtime server. It adopts a multitask learning approach, jointly training all ambiguity models to solve context ambiguity and generate correct pronunciation and as a result reduces over 50% of pronunciation errors.
What are the challenges?
Generally, different natural languages have different linguistic grammar. In TTS, text analyzer needs to follow the same grammar of languages in order to generate correct pronunciations, which contains but isn’t limited to the following required grammar categories:
- Word Segmentation is the process of dividing the written text into meaningful units, such as words. In English and many other languages using some form of the Latin alphabet, the space is a good approximation of a word divider. On the other hand, in languages such as Chinese or Japanese, there is no spacing in sentences. Different word segmentation results may cause different meanings and pronunciations.
- Part-of-Speech Tagging is the process of marking up a word in a text as corresponding to a particular part of speech (such as noun, verb, adj, adv and so on), based on both its definition and its context.
- Morphology is the progress of classifying words according to shared inflectional categories such as person (first, second, third), number (singular vs. plural), gender (masculine, feminine, neuter) and case (nominative, oblique, genitive) with a given lexeme.
- Text Normalization is the process of transforming digits or symbols to their standard format for disambiguation, for example: “$200″ would be normalized as “two hundred dollars”, “200M” would be normalized as “two hundred meters” or “two hundred million”.
- Similar to Text Normalization, Abbreviation Expansion is the process of transforming non-standard words to their standard format for disambiguation, for example: “VI” would be normalized as “six”, “St” would be normalized as “Saint” or “street”.
- Polyphone Disambiguation is the process of marking up polyphone word (heteronym word, which has one spelling but has more than one pronunciation and meaning) to its correct pronunciation based on its context.
Category | Example |
Word Segmentation | [English] [Chinese] 在圣诞节纽约大都会有演出 –> 在 / 圣诞节 / 纽约 / 大 / 都会(du1 hui4) / 有 / 演出 [Chinese] 在圣诞节纽约大都会有演出 –> 在/ 圣诞节 / 纽约 / 大都(da4 dou1) / 会 / 有 / 演出 |
Part-of-Speech Tagging | [Noun, | l ai v s |] [Verb, | l I v s |] I also discovered the very angry raccoon that lives near my porch. |
Morphology | [Singular] 1km –> one kilometer [Plural] 5km –> five kilometers |
Text Normalization | [Fraction, nine out of ten] The O.S. Speed T1202 ups the ante for race-winning performance, resulting in a power plant that will dominate 9/10 scale competition. [Date, September tenth] 1st episode will air 9/10 with never before seen video of her birth! |
Abbreviation Expansion | [Street] Oh man, biking from 24th St BART to the 29th St bikeshare station, that will be sweet. [Saint] We continue to ask anyone who was in the wider area near St Heliers School between 7.30am and 9am and witnessed any suspicious activity to contact police |
Polyphone Disambiguation | [p r ih – z eh 1 n t] The prices will present the estimated discount utilizing the drug discount card. [p r eh 1 – z ax n t] But our present situation is not a natural one. |
Most pronunciations are affected by these categories based on syntactic or semantic context, and these categories are all challenging disambiguation problems. The traditional TTS approach is a pipeline-based module called “text analyzer” with a series of models aimed at solving grammar disambiguation problems, which causes some of the following issues:
- Complex model. Redundant models are built and optimized separately but implemented together in the traditional text analyzer, which causes pipeline long and complicated.
- Error propagation. Accumulated errors caused by the models isolated would affect the final results.
- High latency. Models run one by one in the traditional text analyzer which is pipeline-based. Time cost is high in the runtime server.
Compared to the traditional pipeline-based text analyzers, our Neural TTS proposes a Unified Neural Text Analyzer model (UniTA) to improve TTS pronunciation.
- It builds a unified text analyzer model, which greatly simplifies the text analyzer workflow and reduces time latency in the runtime server.
- It adopts a multitask learning approach, jointly training all ambiguity models to solve context ambiguity and generate the correct pronunciations, reducing pronunciation errors by over 50%.
How does UniTA improve pronunciations?
Firstly, UniTA converts the input text to word embedding vectors through a pre-trained model. Word embedding is a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from vocabulary are mapped to vectors of real numbers. Conceptually, it involves a mathematical embedding from a space with many dimensions per word to a continuous vector space with a much lower dimension. Pre-training models like XYZ-Code have demonstrated unprecedented effectiveness for learning universal language representations based on unlabeled corpus with the method achieving great success in many tasks like language understanding and language generation.
Secondly, a sequence tagging fine-tune strategy is adopted in the UniTA model. UniTA is designed as a typical word classification task, in which
- Word Segmentation predicts word delimiter as word boundary or not.
- Part-of-Speech (POS) predicts “noun”, “verb”, “adj” and so on to classify word part-of-speech.
- Morphology predicts “singular”, “plural”, “masculine”, “feminine”, “neuter” and so on to classify word number, gender and case.
- Text Normalization (TN) predicts candidate digits to “cardinal”, “date”, “time”, “stock” or other TN categories, and then an auxiliary component “TN Rule” helps convert digits to word form based on predicted category.
- Abbreviation Expansion predicts candidate abbreviation word to its expanded form.
- Polyphone disambiguation predicts polyphone words’ pronunciation. An auxiliary component, “Lexicon” is used here for achieving non-polyphone words’ pronunciations.
Different from the traditional text analyzer training models , UniTA adopts a multitask learning approach to jointly train all categories together including word segmentation, part-of-speech tagging, morphology, abbreviation expansion, text normalization and polyphone disambiguation. The multitask learning approach shares hidden layers’ information and jointly trains across different tasks, which has achieved state-of-art achievements on many NLP tasks. In UniTA, hidden information is also shared in models when training.
For example, the sentence “St. John had a 10-3 run to build its lead to 78-64 with 4:44 left.” in the training corpus is annotated as showed in the table below. “–” means there is no related tag in the category. In the word segmentation column, the phrase “10-3” is segmented as “10”, “-” and “3”; in the morphology column, the word “had” is annotated as “past tense”; in the text normalization column, “10-3” belongs to interpreting word “to” instead of “-“ while “4:44” belongs to the pattern using time format; In the abbreviation column, word “St.” is expanded as “Saint” rather than “Street”; and in the polyphone disambiguation column, the word “lead” is pronounced as [l i: d]. Actually, the word “lead” has two pronunciations, it is pronounced as [l i: d] when its POS is noun while pronounced as [l e d] when its POS is verb. This means the POS results and Polyphone results can share the inner information. In this way, multitask model improves UniTA accuracy.
Word | Word Segmentation | Part-of-Speech | Morphology | Text Normalization | Abbreviation | Polyphone disambiguation |
St. | — | Noun | — | — | Saint | — |
John | — | Noun | — | — | — | — |
had | — | Verb | Past tense | — | — | — |
a | — | Det | — | — | — | — |
10-3 | 10 / – / 3 | Num | — | numbers are predicted as “ten to three” | — | — |
run | — | Noun | Singular | — | — | — |
to | — | Particle | — | — | — | — |
build | — | Verb | — | — | — | — |
its | — | Det | — | — | — | — |
lead | — | Noun | Singular | — | — | l i: d |
to | — | Particle | — | — | — | — |
78-64 | 78 / – / 64 | Num | — | numbers are predicted as “seventy-eight to sixty-four” | — | — |
with | — | Prep | — | — | — | — |
4:44 | 4 / : / 44 | Num | — | numbers are predicted as time format | — | — |
left | — | Verb | Past participle | — | — | — |
. | — | Symbol | — | — | — | — |
UniTA model predicts categories’ results together in the neural TTS runtime service. The same as training, UniTA converts the plain texts to word embeddings and then the multitask sequence tagging model predicts all the categories’ results. Some auxiliary modules are embedded after fine-tuning categories to further improve pronunciations. Finally, the pronunciation results are generated from UniTA.
Here is the figure of the UniTA model structure in Neural TTS:

Pronunciation accuracy improved with UniTA
Compared with the traditional TTS text analyzer, UniTA reduces over 50% of pronunciation errors in improving pronunciation accuracy. It is already used many neural voice languages such as English (United States), English (United Kingdom), Chinese (Mandarin, simplified), Russian (Russia), German (Germany), Japanese (Japan), Korean (Korea), Polish (Poland) and Finnish (Finland). Due to varying types of grammar in language, not all categories are suitable for every language. For example, Chinese and Japanese heavily depend on word segmentation and polyphone while these languages don’t need morphology or abbreviation expansion.
Here are some samples of the pronunciation improvement using UniTA.
Category | Language | Input text (target word bolded) | Previous pronunciation | Current pronunciation |
Word Segmentation | Chinese (Mandarin, simplified) | 太子与三殿下行过礼后坐了片刻就离开了。 | “三殿 / 下行 / 过礼” | “三殿下 / 行过礼” |
Word Segmentation | Chinese (Mandarin, simplified) | 叶奎最终还是在剧痛下泄了气 | “剧痛 / 下泄了气” | “剧痛下 / 泄了气” |
Word Segmentation | German (Germany) | kulturform | kult+urform | kultur+form |
Word Segmentation | Korean (Korea) | 해외감염병 | h̬ɛwɛg̥mjʌmbjʌŋ | h̬ɛwɛg̥mjʌmpjʌŋ |
Morphology – case ambiguity | Russian (Russia) | Количество ударов по воротам (15 против 7) также говорит о преимуществе чемпионов мира | Семь | Семи |
Abbreviation Expansion | English (United States) | Joined TX Army National Guard in 1979. | T.X. | Texas |
Text Normalization | English (United States) | The Downtown Cabaret Theatre’s Main Stage Theatre division concludes its 2010/11 season with the Tony Award winning musical, in the heights by Lin-Manuel Miranda. | November 2010 | 2010 to 2011 |
Polyphone disambiguation | Chinese (Mandarin, simplified) | 卓文君听琴后,理解了琴曲的含意,不由脸红耳热,心驰神往。 | qu1 | qu3 |
Polyphone disambiguation | English (United States) | I received a copy early in November, and read and contemplated it’s provisions with great satisfaction. | ||
Polyphone disambiguation | Japanese (Japan) | パッケージには、富士屋ホテルが発刊した「We Japanese」内の説明用の挿絵を採用。 | うち (w u – ch i) | ない (n a – y i) |
Hear how the Cortana voice pronounces each word accurately with UniTA.
Get started
With these updates, we’re excited to continue to power accurate, natural and intuitive voice experiences for customers world-wide. Azure Text-to-Speech service provides more than 200 voices in over 50 languages for developers all over the world.
For more information:
- Try the demo
- See our documentation
- Check out our sample code
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments