This article is contributed. See the original author and article here.
This case started as an issue on SQL on-demand while reading a parquet file. The error was conversion overflows.
Error: Conversion overflows.
So my objective on this post is to describe a possible workaround to read this file in the Spark as also to give some ideas on how to troubleshoot this with the notebook.
Basically I loaded the file on Spark using Scala and it completed successfully:
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create a DataFrame
val df = sqlContext.read.parquet("abfss://<storage>.dfs.core.windows.net/folder/file.parquet")
Display (df.limit(10))
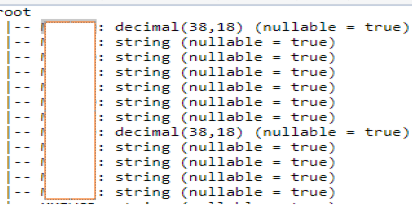
No big deal here. After that, I wanted to check the metadata:
// Print the schema in a tree format
df.printSchema()
You should have a result like the following:

More information you can find here:
https://spark.apache.org/docs/preview/sql-programming-guide.html
Once I found the metadata I used the column name information to run the query against SQL on-demand. With this information, I found the issue was related to a decimal column.
Here some SQL On-demand query tips for conversion issues:
1) You can use schema inferring while querying and by using it you can convert the column datatype. For example, I will convert the decimal column named as column_dec_converted to varchar.
SELECT *
FROM OPENROWSET(
BULK 'https://<storage>.dfs.core.windows.net/folder/file.parquet',
FORMAT='PARQUET' ) WITH ( column_dec_converted varchar(100) ) as rows
2) You can actually apply the convert on the Select Clause as you would do on standard SQL Server:
SELECT cast (column_dec_converted as varchar(100))
FROM OPENROWSET(
BULK https://<storage>.dfs.core.windows.net/folder/file.parquet',
FORMAT='PARQUET' ) as ResultThat is it!
Liliam C Leme
UK Engineer
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments